Implementasi Dimensionality Reduction dengan PCA dan t-SNE: Visualisasi Data Dimensi Tinggi

Mengapa Data Dimensi Tinggi Menjadi Tantangan dalam Analisis
Semakin banyak fitur yang kita miliki dalam sebuah dataset, semakin kompleks analisis yang harus dilakukan. Fenomena ini dikenal sebagai curse of dimensionality — ketika jumlah fitur bertambah, data menjadi semakin sparse dan jarak antar titik data cenderung seragam, sehingga algoritma machine learning kesulitan menemukan pola yang bermakna. Lebih dari itu, manusia secara alami hanya mampu memvisualisasikan data dalam dua atau tiga dimensi. Data dengan puluhan atau ratusan fitur tidak bisa langsung di-plot untuk diamati.
Dimensionality reduction hadir sebagai solusi untuk mengatasi tantangan ini. Teknik ini memproyeksikan data dari dimensi tinggi ke dimensi rendah sambil mempertahankan struktur informatif yang penting. Dua pendekatan yang paling populer adalah Principal Component Analysis (PCA) yang bersifat linear, dan t-Distributed Stochastic Neighbor Embedding (t-SNE) yang non-linear. PCA bekerja dengan menemukan sumbu-sumbu baru yang memaksimalkan varians data, sementara t-SNE memetakan kemiripan antar titik data ke dalam peta berdimensi rendah. Keduanya memiliki kegunaan yang berbeda dan saling melengkapi.
PCA — Menangkap Varian Maksimum dengan Transformasi Linear
Principal Component Analysis bekerja dengan mentransformasi data ke dalam sistem koordinat baru di mana sumbu-sumbunya — yang disebut principal components — diorientasikan searah dengan varians terbesar dari data. Ide dasarnya sederhana: jika sebuah fitur tidak menunjukkan banyak variasi antar observasi, fitur tersebut mungkin tidak terlalu penting untuk memahami struktur data.
Proses PCA dimulai dengan standarisasi data agar setiap fitur memiliki mean nol dan varians satu. Langkah ini penting karena PCA sensitif terhadap skala — fitur dengan satuan lebih besar akan mendominasi perhitungan varians. Selanjutnya, kita menghitung matriks kovarians dari data yang sudah distandarisasi, lalu melakukan dekomposisi eigen untuk menemukan eigenvector dan eigenvalue. Eigenvector dengan eigenvalue terbesar menjadi principal component pertama karena menangkap varians terbanyak.
Mari kita lihat implementasinya menggunakan dataset Wine dari Scikit-learn, yang memiliki 13 fitur kimiawi dari tiga jenis anggur:
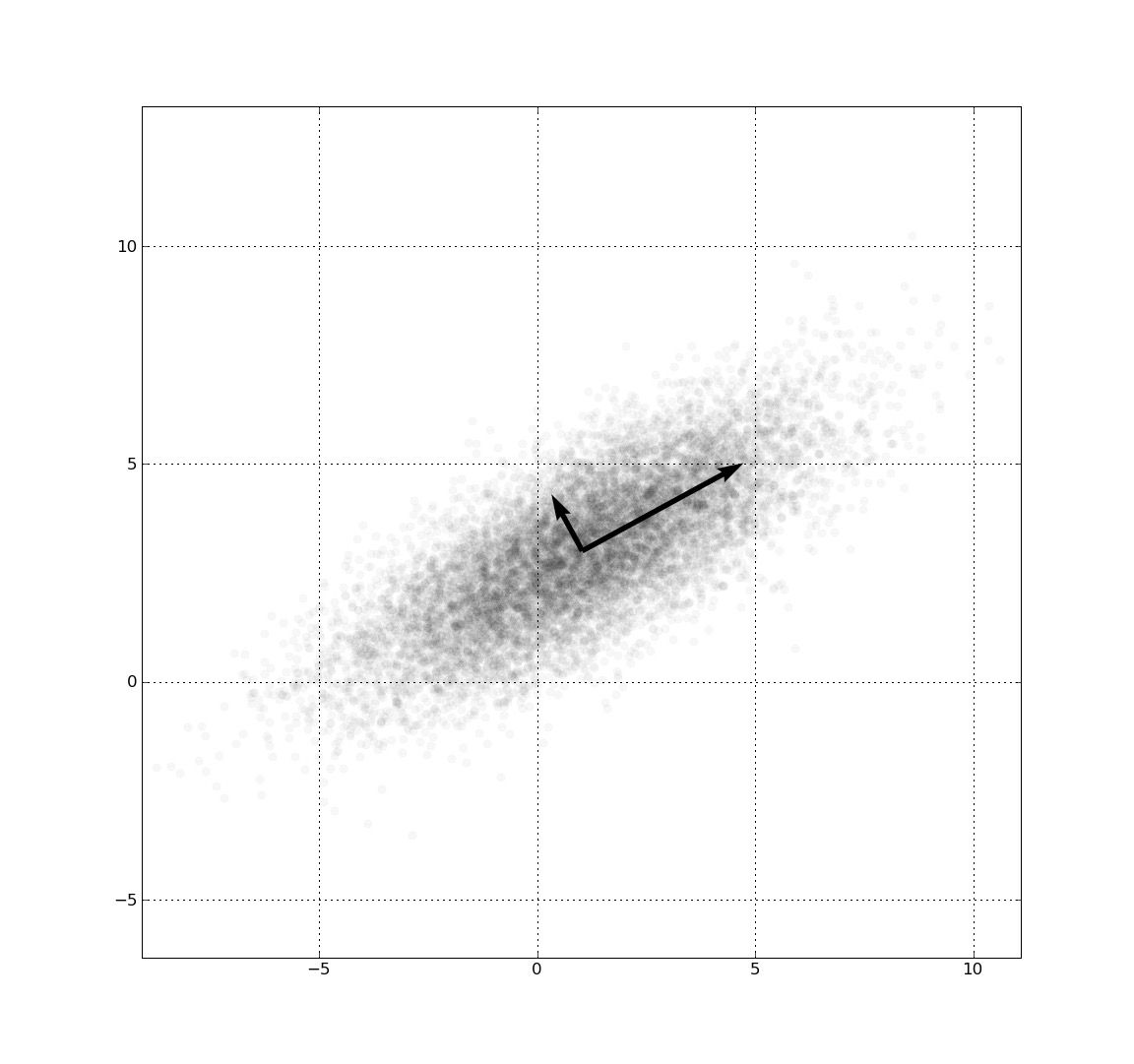
Gambar: Scatter plot sampel distribusi Gaussian bivariat dengan principal components — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:GaussianScatterPCA.png)
!pip install scikit-learn matplotlib pandas
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Load data
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
# Standarisasi
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# Explained variance ratio
explained_variance = pca.explained_variance_ratio_
cumulative = np.cumsum(explained_variance)
# Visualisasi
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Scree plot
axes[0].bar(range(1, len(explained_variance) + 1), explained_variance, alpha=0.7)
axes[0].plot(range(1, len(cumulative) + 1), cumulative, 'ro-', markersize=4)
axes[0].set_xlabel('Principal Component')
axes[0].set_ylabel('Explained Variance Ratio')
axes[0].set_title('Scree Plot - Explained Variance per Component')
axes[0].axhline(y=0.95, color='gray', linestyle='--', alpha=0.5)
# 2D scatter
scatter = axes[1].scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolors='k', s=50)
axes[1].set_xlabel(f'PC1 ({explained_variance[0]:.1%})')
axes[1].set_ylabel(f'PC2 ({explained_variance[1]:.1%})')
axes[1].set_title('PCA 2D Projection - Wine Dataset')
fig.colorbar(scatter, ax=axes[1], label='Wine Class')
plt.tight_layout()
plt.show()Output:
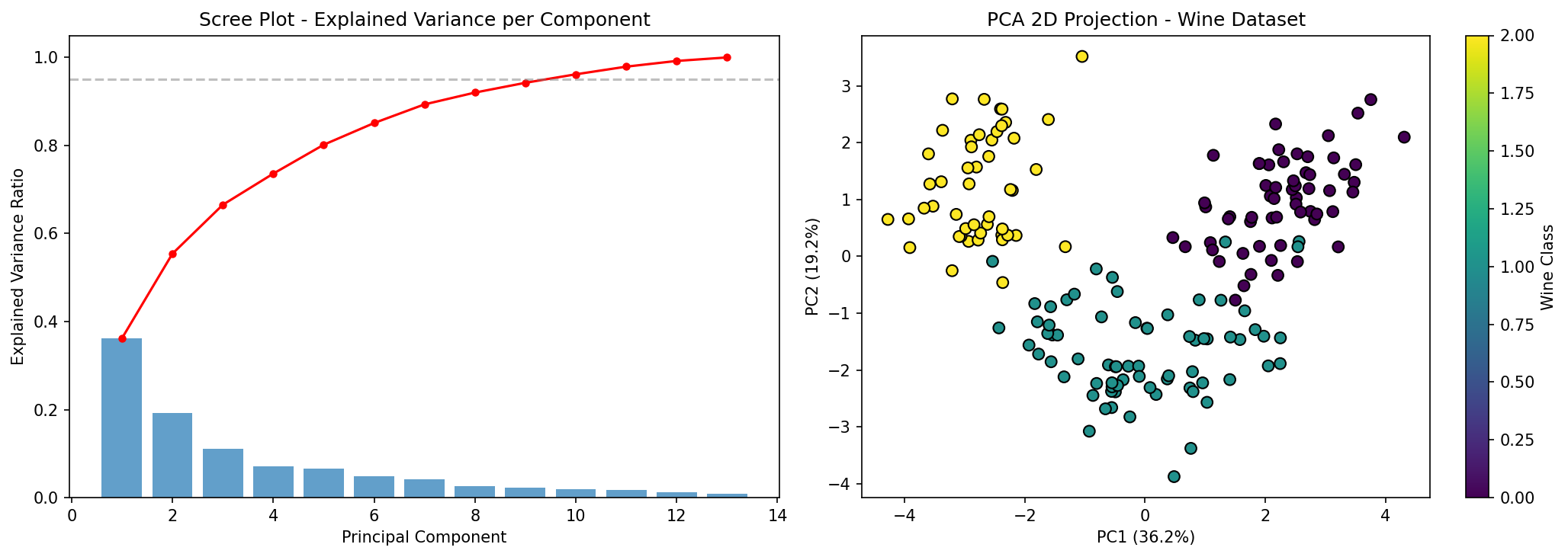
Dua komponen pertama PCA menangkap sekitar 55-60% dari total varians dataset Wine. Ini berarti kita kehilangan sekitar 40% informasi, tetapi dalam praktiknya visualisasi 2D ini sudah cukup untuk melihat bahwa titik-titik dari kelas yang berbeda mulai terpisah. Scree plot di sebelah kiri membantu kita memutuskan berapa banyak komponen yang perlu dipertahankan — kita bisa memilih titik di mana kurva cumulative menjelang 95% atau mulai mendatar.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
t-SNE — Memetakan Kemiripan Non-Linear ke Peta 2D
t-SNE mengambil pendekatan yang berbeda secara fundamental. Alih-alih mencari sumbu dengan varians maksimum, t-SNE mengukur kemiripan antar titik data dalam dimensi tinggi dengan menggunakan distribusi Gaussian. Titik-titik yang berdekatan dalam dimensi tinggi mendapat probabilitas tinggi untuk juga berdekatan dalam peta 2D, sementara titik yang jauh mendapat probabilitas rendah. Proses optimasi kemudian meminimalkan perbedaan antara distribusi probabilitas di dimensi tinggi dan distribusi di peta 2D menggunakan Kullback-Leibler divergence.
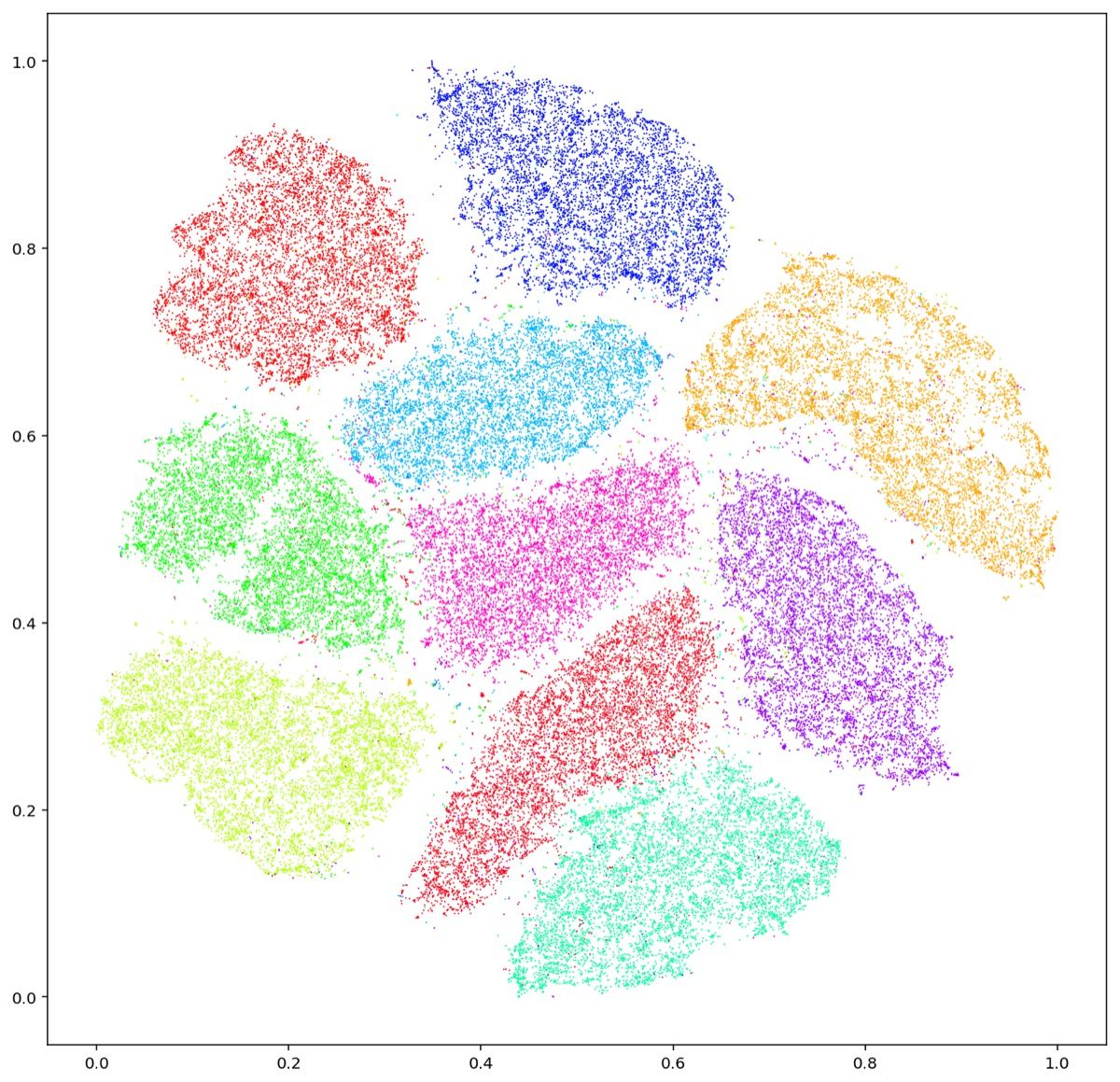
Gambar: Visualisasi dataset MNIST menggunakan t-SNE — sepuluh digit (0-9) tercluster secara alami — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:T-SNE_Embedding_of_MNIST.png)
Parameter paling penting dalam t-SNE adalah perplexity, yang secara kasarnya mengontrol keseimbangan antara memperhatikan struktur lokal dan global. Perplexity yang terlalu kecil (misal 5) membuat plot terfragmentasi menjadi cluster kecil yang terlalu banyak, sementara perplexity terlalu besar (misal 100) bisa membuat data menyatu tanpa struktur yang jelas. Nilai tipikal berkisar antara 20 hingga 50.
Mari kita bandingkan PCA dan t-SNE secara langsung pada dataset yang sama:
from sklearn.manifold import TSNE
# t-SNE dengan berbagai perplexity
perplexities = [5, 30, 50]
fig, axes = plt.subplots(1, 4, figsize=(20, 5))
# PCA (referensi)
axes[0].scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolors='k', s=50)
axes[0].set_title('PCA (referensi)')
axes[0].set_xlabel('PC1')
axes[0].set_ylabel('PC2')
# t-SNE
for i, perp in enumerate(perplexities):
tsne = TSNE(n_components=2, perplexity=perp, random_state=42)
X_tsne = tsne.fit_transform(X_scaled)
axes[i + 1].scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis', edgecolors='k', s=50)
axes[i + 1].set_title(f't-SNE (perplexity={perp})')
axes[i + 1].set_xlabel('t-SNE 1')
axes[i + 1].set_ylabel('t-SNE 2')
plt.tight_layout()
plt.show()Output:
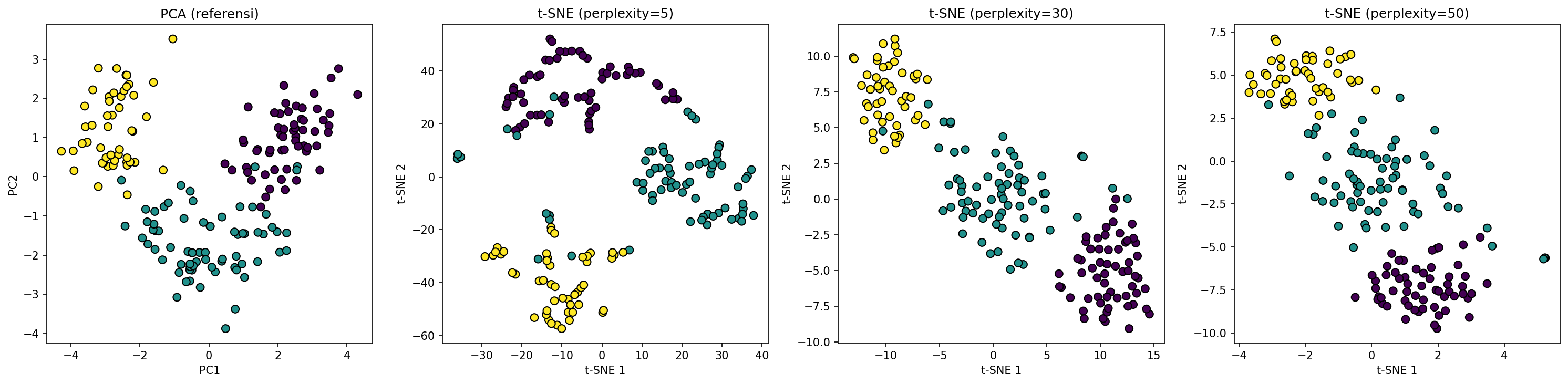
Perhatikan perbedaan visual yang mencolok antara PCA dan t-SNE. PCA menghasilkan plot yang relatif longgar dan cenderung mempertahankan jarak global antar titik. t-SNE, di sisi lain, menghasilkan cluster yang jauh lebih rapat dan terdefinisi dengan jelas — kita bisa melihat tiga kelompok yang sangat terpisah untuk tiga kelas wine. Ini karena t-SNE fokus pada struktur lokal: titik-titik dalam kelas yang sama ditarik saling mendekat, sementara titik dari kelas berbeda dijauhkan.
Dengan perplexity 5, plot t-SNE menunjukkan terlalu banyak fragmentasi. Perplexity 30 dan 50 memberikan hasil yang lebih stabil dan interpretable. Dalam praktiknya, kita perlu mencoba beberapa nilai perplexity dan mengamati konsistensi pola — t-SNE bersifat stokastik, jadi hasil bisa berbeda setiap kali dijalankan.
Panduan Memilih antara PCA dan t-SNE
Setiap teknik memiliki keunggulan dan kelemahan yang menentukan kapan kita harus menggunakannya. PCA unggul dalam kecepatan, determinisme, dan interpretability — kita bisa mengetahui seberapa besar kontribusi setiap fitur asli terhadap komponen utama. Ini membuat PCA ideal sebagai langkah preprocessing sebelum melatih model machine learning, terutama ketika kita menghadapi multikolinearitas atau ingin mengurangi jumlah fitur untuk mempercepat training.
t-SNE, sebaliknya, adalah alat eksplorasi dan visualisasi murni. Hasilnya tidak bisa digunakan untuk inference atau sebagai input model karena t-SNE tidak mempertahankan jarak global — hanya struktur lokal yang terjaga. t-SNE juga bersifat non-deterministik dan membutuhkan komputasi yang jauh lebih berat, terutama pada dataset dengan ribuan sampel.
Kombinasi keduanya sering menjadi pendekatan terbaik. Kita bisa menggunakan PCA terlebih dahulu untuk mengurangi noise dan dimensi data menjadi 30-50 komponen, lalu menerapkan t-SNE pada hasil PCA untuk visualisasi akhir. Strategi ini secara signifikan mempercepat komputasi t-SNE dan sering menghasilkan visualisasi yang lebih bersih:
from sklearn.datasets import load_digits
# Load dataset digit (64 fitur dari 8x8 pixel)
digits = load_digits()
X_digits = digits.data
y_digits = digits.target
# Pipeline: PCA 30 komponen → t-SNE
pca_50 = PCA(n_components=30)
X_pca_50 = pca_50.fit_transform(X_digits)
tsne_final = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne_final = tsne_final.fit_transform(X_pca_50)
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_tsne_final[:, 0], X_tsne_final[:, 1],
c=y_digits, cmap='tab10', edgecolors='k', s=40)
plt.colorbar(scatter, label='Digit Class')
plt.title('PCA (30) → t-SNE: Visualisasi Dataset Digit')
plt.xlabel('t-SNE 1')
plt.ylabel('t-SNE 2')
plt.show()Output:
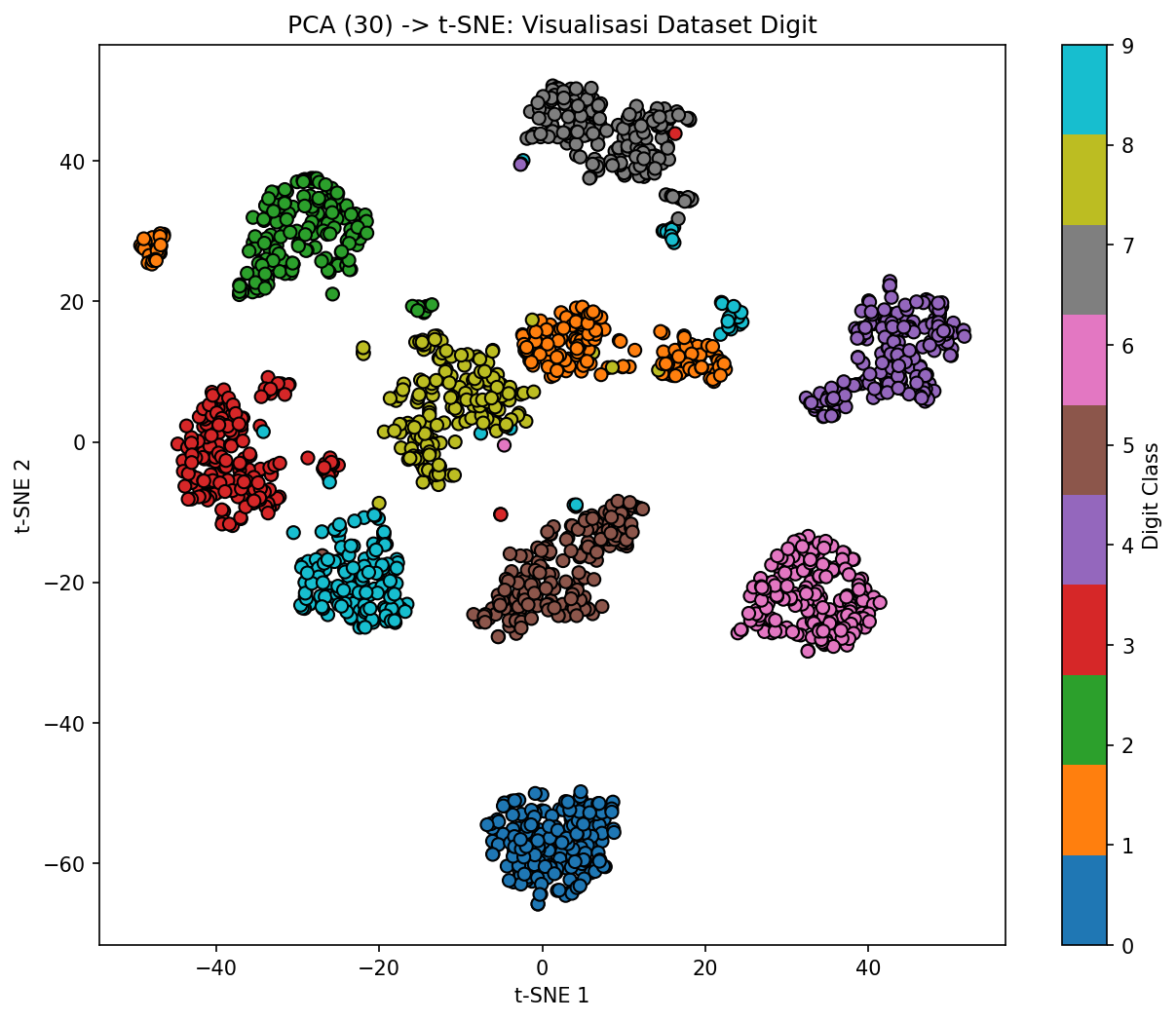
Pada dataset digit tulisan tangan (64 fitur), pipeline PCA→t-SNE menghasilkan visualisasi yang luar biasa. Sepuluh kelas digit (0-9) terpisah menjadi cluster yang jelas, dan kita bisa melihat bahwa digit seperti 3 dan 8 yang secara visual mirip berada berdekatan. Informasi ini sangat berharga untuk memahami struktur data sebelum membangun model klasifikasi.
Kesimpulannya, pilih PCA ketika kita membutuhkan interpretability, kecepatan, dan hasil yang konsisten untuk preprocessing model. Pilih t-SNE ketika prioritas utama adalah visualisasi eksploratori dan penemuan cluster dalam data berdimensi tinggi. Dan ingat — keduanya bukanlah pesaing, melainkan alat yang saling melengkapi dalam toolkit data scientist.
Tertarik mendalami teknik data science dan machine learning lebih lanjut? Rumah Coding menyediakan kursus komprehensif yang mencakup dari preprocessing data, feature engineering, visualisasi, hingga deployment model. Mulai perjalanan belajarmu sekarang dan bangun fondasi data science yang kokoh bersama para mentor profesional.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model
Artikel Terkait

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python

Time Series Decomposition dengan Python: Memisahkan Trend, Seasonal, dan Residual menggunakan Statsmodels
