Serialisasi Data di Python: Perbandingan Pickle, JSON, dan Protocol Buffers
Mengapa Serialisasi Data Penting dalam Pengembangan Aplikasi
Serialisasi data adalah proses mengubah struktur data Python menjadi format yang dapat disimpan ke file atau ditransmisikan melalui jaringan. Proses sebaliknya, deserialisasi, mengembalikan data ke bentuk aslinya. Kita menggunakan serialisasi setiap kali menyimpan model machine learning, mengirim data melalui REST API, atau mengimplementasikan sistem cache.
Pemilihan format serialisasi yang tepat memengaruhi performa aplikasi secara langsung. Format yang salah dapat memperlambat response time API, meningkatkan penggunaan storage, atau bahkan menimbulkan celah keamanan.Sebagai developer, kita perlu memahami karakteristik masing-masing format agar dapat memilih инструмент yang sesuai dengan kebutuhan spesifik proyek.
JSON: Format Text Universal untuk Interoperability
JSON menjadi pilihan utama untuk komunikasi antar service karena formatnya yang human-readable dan language-agnostic. Hampir semua bahasa pemrograman modern memiliki parser JSON bawaan, sehingga data dapat dikonsumsi oleh client dengan teknologi berbeda.
Keterbatasan JSON terletak pada tidak adanya dukungan tipe data binary dan kecepatan parsing yang lebih lambat compared to binary formats. JSON juga tidak memiliki schema bawaan, sehingga validasi struktur data bergantung sepenuhnya pada application logic.
Penggunaan json module cukup straightforward. Fungsi json.dumps() mengkonversi Python object ke JSON string, sementara json.loads() melakukan proses sebaliknya.
import json
data = {
"user_id": 42,
"username": "budisentana",
"email": "[email protected]",
"roles": ["admin", "developer"],
"is_active": True
}
json_string = json.dumps(data, indent=2)
print(json_string)
parsed_data = json.loads(json_string)
print(parsed_data["username"])Output:
{
"user_id": 42,
"username": "budisentana",
"email": "[email protected]",
"roles": [
"admin",
"developer"
],
"is_active": true
}
budisentanaJSON ideal untuk REST API public, configuration files, dan pertukaran data antar service yang berbeda bahasa pemrogramannya.
Pickle: Serialisasi Python Object dengan Dukungan Binary
Pickle adalah format native Python yang dapat menserialisasi hampir semua Python object tanpa konversi manual. Module ini mendukung custom class instances, closure, fungsi, dan tipe data kompleks lainnya yang tidak dapat direpresentasikan dalam JSON.
Kecepatan serialisasi dan deserialisasi Pickle lebih tinggi dibandingkan JSON karena formatnya binary dan tidak perlu melakukan parsing string. Pickle juga mempertahankan referensi objek dan circular references dengan akurat.
Keterbatasan utama Pickle adalah masalah keamanan. Module ini tidak dirancang untuk menangani data dari sumber yang tidak trusted karena dapat mengeksekusi arbitrary code saat deserialisasi. Selain itu, format Pickle tidak interoperable antar bahasa pemrograman.
import pickle
class User:
def __init__(self, user_id, username, metadata=None):
self.user_id = user_id
self.username = username
self.metadata = metadata or {}
def __repr__(self):
return f"User(id={self.user_id}, name='{self.username}')"
user = User(42, "budisentana", {"department": "engineering", "level": 3})
with open("user.pkl", "wb") as f:
pickle.dump(user, f)
with open("user.pkl", "rb") as f:
loaded_user = pickle.load(f)
print(loaded_user)
print(loaded_user.metadata)
API Development with Golang
A hands-on, project-based course designed to teach beginners how to build robust...
Output:
User(id=42, name='budisentana')
{'department': 'engineering', 'level': 3}Pickle tepat untuk internal caching, inter-process communication dalam ekosistem Python, dan menyimpan model machine learning yang tidak dibagikan ke sistem eksternal.
Protocol Buffers: Schema-Based Binary Format untuk Skalabilitas
Protocol Buffers (Protobuf) mengembangkan schema definition file (.proto) untuk mendefinisikan struktur data secara explicit. Schema ini menjadi kontrak antara producer dan consumer, memberikan type safety dan backward/forward compatibility yang kuat.
Format binary Protobuf menghasilkan ukuran payload yang lebih kecil dan kecepatan parsing yang lebih tinggi dibandingkan JSON. Schema evolution memungkinkan penambahan field baru tanpa memecahkan existing clients, selama rules tertentu dipatuhi.
Kelemahan Protobuf adalah kompleksitas setup awal. Developer perlu mendefinisikan .proto file, menginstall compiler, dan menghasilkan code dalam bahasa target. Proses ini menambah friction dalam development workflow.
Definisi schema dan penggunaan Protobuf dalam Python:
// user.proto
syntax = "proto3";
message UserProto {
int32 user_id = 1;
string username = 2;
string email = 3;
repeated string roles = 4;
bool is_active = 5;
}# Install protobuf compiler dan generated code
# pip install protobuf
# protoc --python_out=. user.proto
import user_pb2
# Membuat instance user dari generated class
user = user_pb2.UserProto()
user.user_id = 42
user.username = "budisentana"
user.email = "[email protected]"
user.roles.append("admin")
user.roles.append("developer")
user.is_active = True
# Serialisasi ke binary
binary_data = user.SerializeToString()
print(f"Ukuran binary: {len(binary_data)} bytes")
# Deserialisasi dari binary
loaded_user = user_pb2.UserProto()
loaded_user.ParseFromString(binary_data)
print(f"Username: {loaded_user.username}")
print(f"Roles: {list(loaded_user.roles)}")Protobuf optimal untuk high-performance microservices dengan volume data besar, komunikasi antar service dalam distributed system, dan skenario where bandwidth efficiency sangat kritikal.
Perbandingan Langsung: Kapan Menggunakan Format yang Tepat
Pemilihan format serialisasi sebaiknya didasarkan pada karakteristik spesifik proyek. JSON menawarkan readability dan interoperability terbaik dengan trade-off ukuran payload dan kecepatan parsing. Pickle menyediakan convenience untuk Python-only ecosystem dengan risiko keamanan yang harus diperhatikan. Protobuf memberikan performa optimal dengan biaya kompleksitas setup.
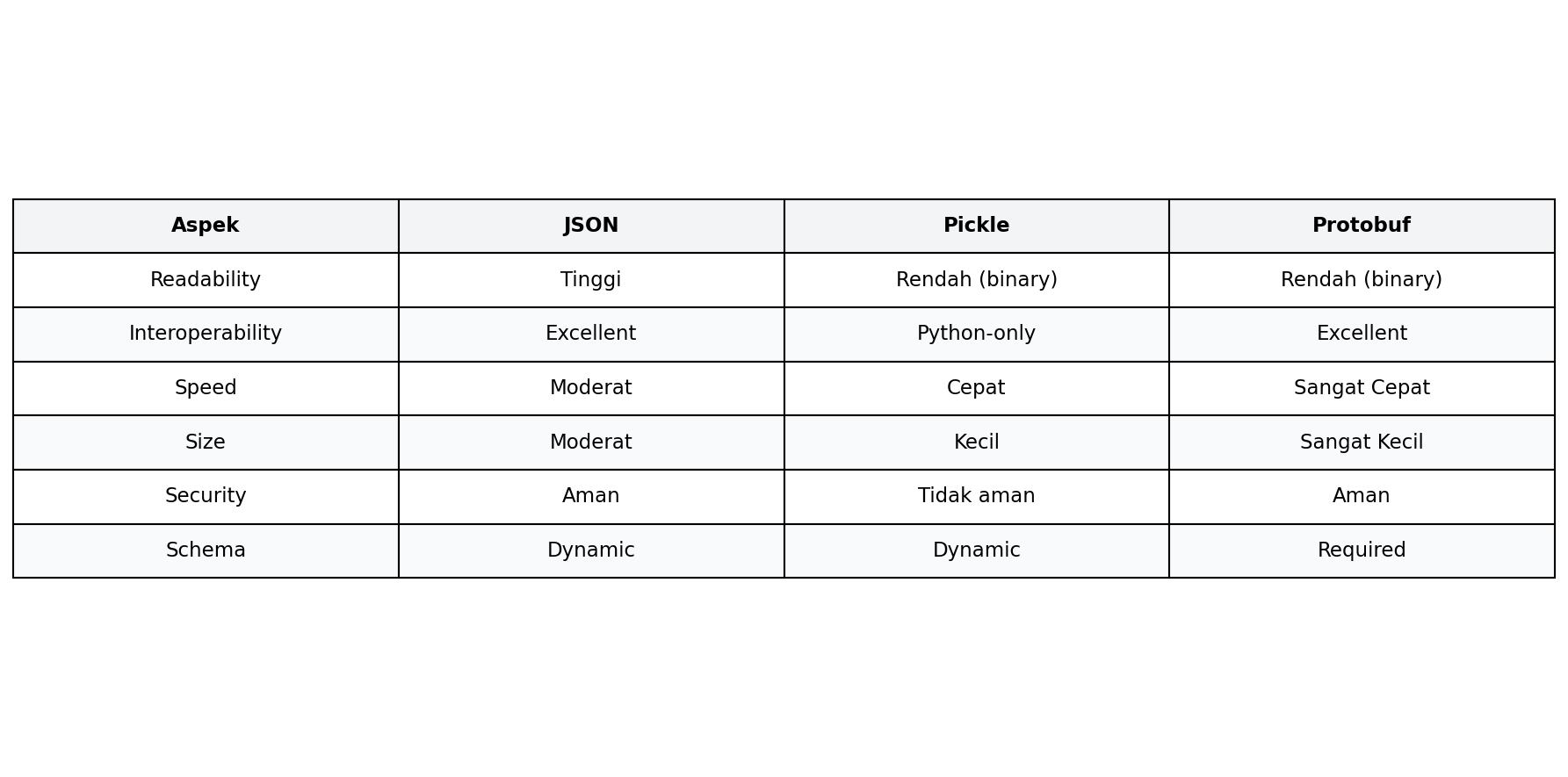
Kesalahan umum adalah menggunakan Pickle untuk data yang dikonsumsi oleh sistem eksternal atau menggunakan JSON untuk payload berukuran sangat besar dalam high-throughput systems. Hybrid approach sering kali menjadi solusi optimal: JSON untuk API layer yang memerlukan debugging mudah, Pickle untuk internal caching dalam Python services, dan Protobuf untuk inter-service communication dengan требования performa tinggi.
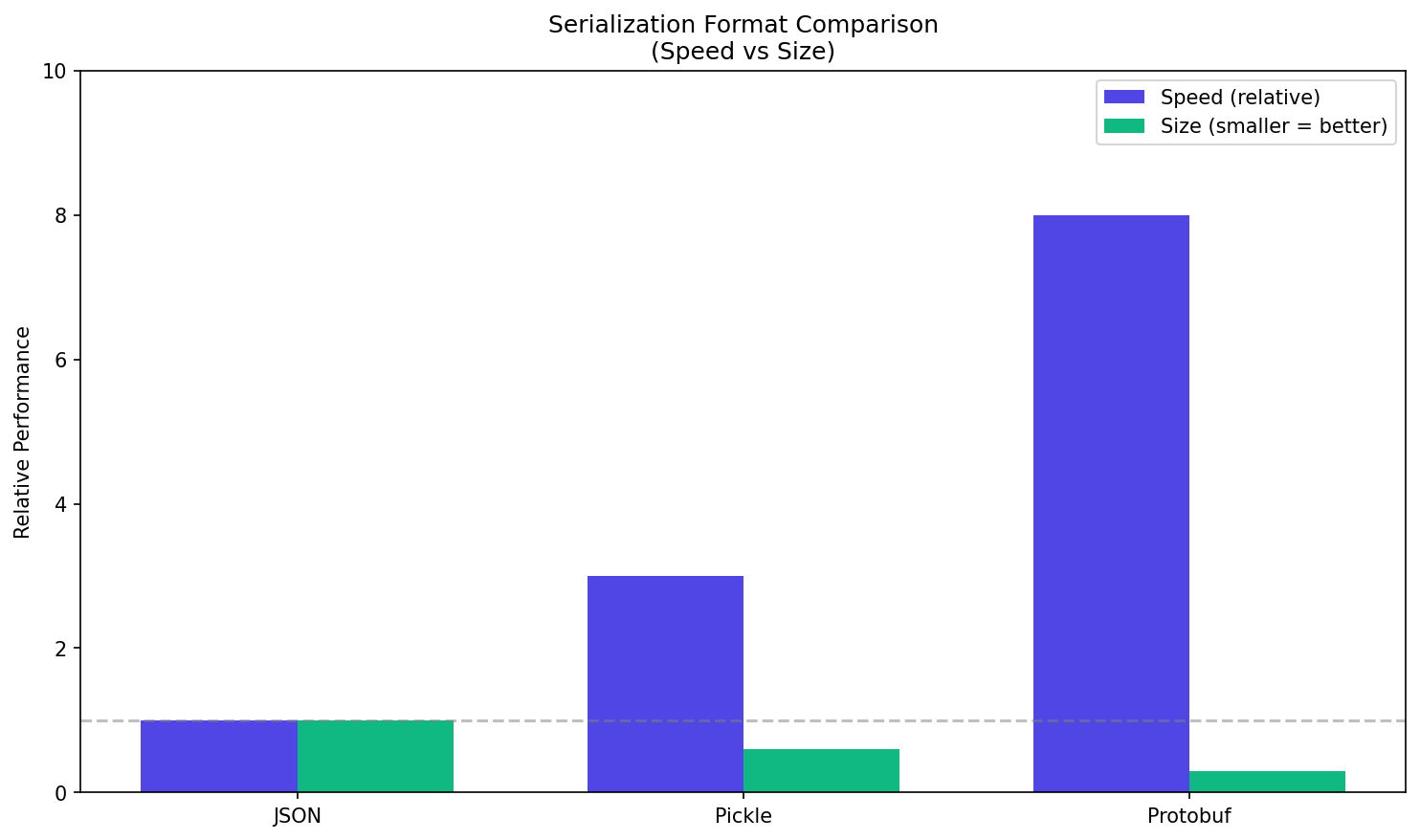
[Image: Perbandingan performa format serialisasi]
Gambar: Perbandingan relatif kecepatan dan ukuran payload antar format serialisasi. Protobuf menunjukkan performa tertinggi dengan ukuran payload terkecil, sedangkan JSON sebagai baseline. — Sumber: Rumah Coding
Best Practices dan Pertimbangan Keamanan
Validasi struktur data sebelum deserialisasi merupakan langkah krusial yang sering diabaikan. Meskipun Protobuf memiliki type safety bawaan, kita tetap perlu memvalidasi business logic constraints seperti range nilai atau format string spesifik.
Schema evolution membutuhkan strategi yang matang. Saat mengubah struktur data, kita harus memastikan backward compatibility dengan existing consumers. Aturan umum Protobuf adalah tidak mengubah nomor field yang sudah ada dan tidak menggunakan kembali nomor field yang telah dihapus.
Untuk security, never unpickle data dari sumber yang tidak trusted. Jika sistem membutuhkan serialisasi untuk data eksternal, gunakan JSON atau Protobuf. Untuk internal use dengan custom objects, pertimbangkan untuk mengimplementasikan __reduce__ atau __getstate__ dengan hati-hati.
Benchmark dengan data realistic sebelum membuat keputusan final. Perbedaan performa antar format sangat bergantung pada struktur data spesifik, ukuran payload, danfrekuensi operasi. Jangan asumsikan bahwa format yang lebih baru atau lebih populer selalu lebih baik untuk use case tertentu.
Ingin mendalamiPython dan kemampuan data processing yang lebih advanced? Rumah Coding menyediakan bootcamp dan course yang membahas Python dari fundamental sampai implementasi tingkat lanjut. Kunjungi website kami untuk informasi lebih lanjut tentang program yang tersedia.
Tags: Python, Serialization, JSON, Pickle, Protocol Buffers, Backend Development
Kursus Terkait

API Development with Golang
A hands-on, project-based course designed to teach beginners how to build robust, high-performance RESTful APIs using Golang. Starting from core Go syntax and concurrency, students will progress through routing, database integration, security, and finally containerize their application for production deployment.
EduTrack: Learning Management & Assessment API
- Role-Based Access Control (RBAC)
- Course & Module Management
- Enrollment & Progress Tracking

Advanced Architecture with Laravel Containers & Queues
A problem-driven, project-based course designed to elevate intermediate developers to a senior architectural mindset. Instead of just memorizing documentation, students will tackle real-world bottleneck issues by mastering the Inversion of Control (IoC) principle, Dependency Injection, and asynchronous background processing. Learn to decouple services and orchestrate robust queues to build scalable, high-performance applications that never freeze under heavy loads.
Asynchronous Bulk E-Certificate & Notification Engine
- Decoupled Service Architecture: PDF generation and Email delivery are built as independent, interface-driven services injected via the Service Container.
- Job Chaining: Ensuring processes run in strict asynchronous order (Generate PDF ➔ Upload to Storage ➔ Send Email).
- Job Batching & Real-Time Tracking: Grouping hundreds of jobs together and displaying a live progress bar (e.g., "65% Completed") on the admin dashboard.

Building Modern Apps with Filament
Learn how to build modern, full-stack web applications rapidly using FilamentPHP and the TALL stack. This project-based course is designed for beginners, guiding you step-by-step to create a fully functional backend administration panel. By the end of the course, you will have mastered Filament's powerful Panel Builder, robust CRUD operations, complex database relationships, and interactive dashboards.
Mini Academic Portal (Learning Management System)
- Master Data Management: Comprehensive CRUD functionality to manage Instructors and Course catalogs.
- Student Registry: A dedicated module to manage student profiles and personal information.
- Dynamic Enrollment System: Handling Many-to-Many relationships to enroll students into specific courses using Filament's pivot features.


