Memahami Konsep Autoencoder dan Implementasinya dengan PyTorch untuk Feature Learning

Konsep Dasar Autoencoder untuk Unsupervised Feature Learning
Autoencoder adalah arsitektur neural network yang dirancang untuk mempelajari representasi data secara unsupervised. Tujuan utamanya sederhana: merekonstruksi input dengan cara melewati sebuah bottleneck, sehingga model dipaksa menangkap pola paling esensial dari data. Secara matematis, autoencoder meminimalkan fungsi loss L(x, x') = ||x x'||^2, di mana x adalah input asli dan x' adalah hasil rekonstruksi. Semakin kecil nilai ini, semakin baik representasi yang dipelajari.
Tidak seperti supervised learning yang membutuhkan label, autoencoder belajar hanya dari data itu sendiri. Pendekatan ini sangat berharga karena banyak dataset nyata tidak memiliki label. Dengan autoencoder, kita bisa memanfaatkan data yang melimpah tanpa perlu anotasi manual yang mahal. Cukup sediakan data, dan model akan menemukan struktur bawaannya sendiri.
Arsitektur autoencoder terdiri dari tiga komponen utama. Encoder bertugas memampatkan input berdimensi tinggi ke representasi berdimensi rendah yang disebut latent space atau bottleneck. Decoder kemudian mengambil representasi tersebut dan mengembalikannya ke dimensi asli. Proses ini mirip dengan kompresi dan dekompresi, tapi dalam konteks neural network. Kualitas rekonstruksi dari decoder menjadi ukuran seberapa baik encoder menangkap esensi data.
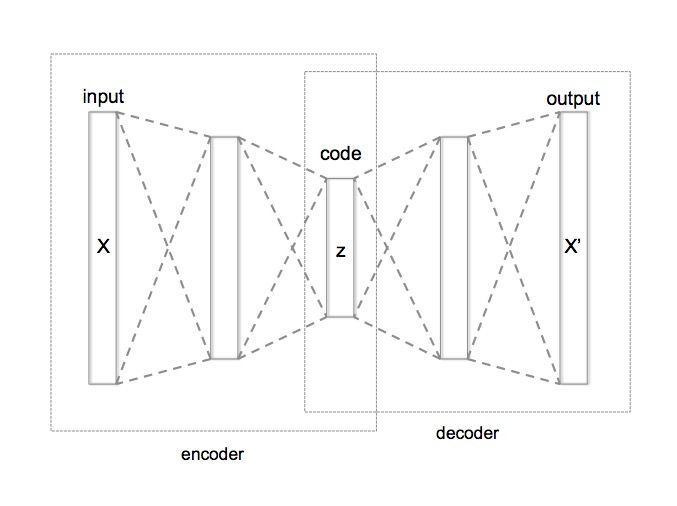
Gambar: Arsitektur umum autoencoder dengan encoder (kompresi), bottleneck (representasi latent), dan decoder (rekonstruksi) — Sumber: [Wikimedia Commons (Chervinskii, CC BY-SA 4.0)](https://commons.wikimedia.org/wiki/File:Autoencoder_structure.png)
Yang membuat autoencoder menarik adalah kemampuannya menangkap pola non-linear. Metode tradisional seperti PCA hanya mampu menangkap hubungan linear antar fitur. PCA mencari kombinasi linear dari fitur asli yang memaksimalkan varians. Tapi manifold data di dunia nyata jarang bersifat linear. Autoencoder, dengan fungsi aktivasi non-linear seperti ReLU di setiap hidden layer, dapat mempelajari manifold data yang kompleks dan melengkung.
Representasi latent dari autoencoder pun lebih bermakna. Model belajar memetakan data ke ruang berdimensi rendah di mana struktur intrinsik data terjaga. Representasi ini sering digunakan sebagai input untuk tugas downstream seperti klasifikasi atau clustering. Ini menjadikan autoencoder sebagai tools yang powerful dalam unsupervised feature learning. Karena tidak ada label yang terlibat, pendekatan ini sangat cocok untuk dataset besar di mana anotasi manual mahal atau tidak praktis.
Membangun Arsitektur Encoder-Decoder dengan PyTorch
Mari kita implementasi autoencoder menggunakan PyTorch. Kita akan mendefinisikan sebuah kelas Autoencoder yang mewarisi nn.Module. Arsitektur ini terdiri dari encoder yang secara progresif menurunkan dimensi input, dan decoder yang mengembalikannya ke bentuk semula.
Encoder dimulai dari input 784 dimensi (gambar MNIST berukuran 28x28 piksel setelah di-flatten), lalu turun ke 128, 64, dan akhirnya 32 di bottleneck. Pola piramida ini penting. Setiap layer memampatkan informasi sedikit demi sedikit, bukan langsung dari 784 ke 32. Pendekatan bertahap ini memungkinkan model mempelajari transformasi yang lebih smooth dan stabil secara numerik.
Decoder adalah cerminan dari encoder. Dari 32 naik ke 64, 128, dan kembali ke 784. Struktur mirror ini bukan kebetulan. Dengan simetri ini, decoder bisa merekonstruksi secara bertahap, mengembalikan detail yang hilang selama kompresi. Fungsi aktivasi ReLU kita gunakan di setiap hidden layer karena sederhana dan efektif menghindari masalah vanishing gradient. Sementara output layer menggunakan Sigmoid karena data sudah dinormalisasi ke rentang [0,1].
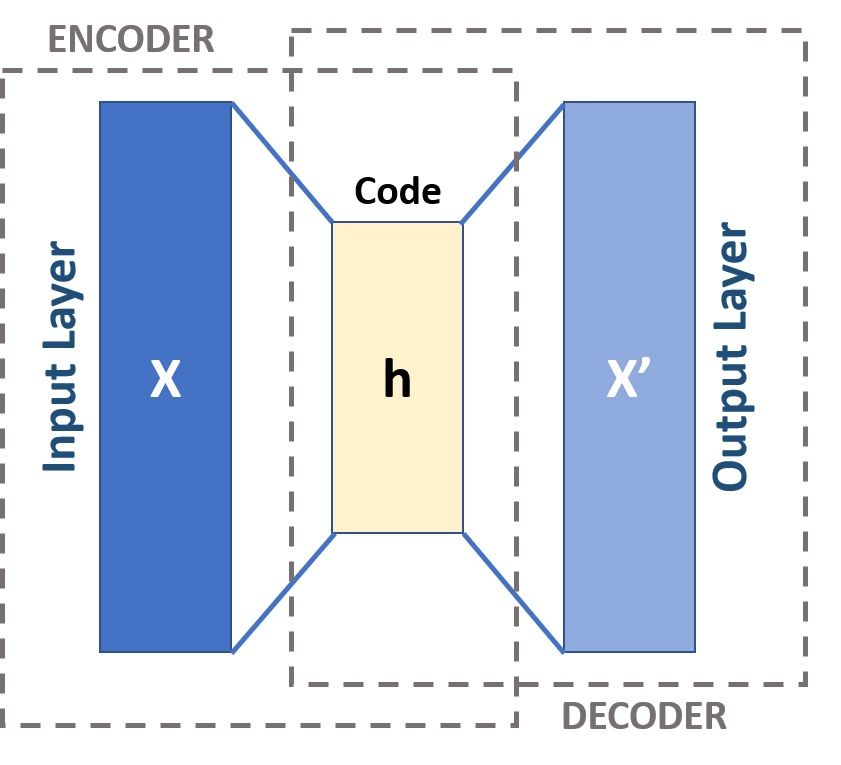
Gambar: Skema autoencoder yang menunjukkan alur data dari input → encoder → latent space (bottleneck) → decoder → rekonstruksi output — Sumber: [Wikimedia Commons (Michela Massi, CC BY-SA 4.0)](https://commons.wikimedia.org/wiki/File:Autoencoder_schema.png)
!pip install torch torchvision matplotlib scikit-learn
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
class Autoencoder(nn.Module):
def __init__(self, encoding_dim=32):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 784),
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
model = Autoencoder(encoding_dim=32)
print(model)Output:
Autoencoder(
(encoder): Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=64, bias=True)
(3): ReLU()
(4): Linear(in_features=64, out_features=32, bias=True)
(5): ReLU()
)
(decoder): Sequential(
(0): Linear(in_features=32, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=784, bias=True)
(5): Sigmoid()
)
)Perhatikan parameter encoding_dim yang menentukan tingkat kompresi. Nilai 32 berarti kita memampatkan 784 piksel menjadi hanya 32 angka, rasio kompresi hampir 25:1. Angka 32 bukanlah angka ajaib. Untuk dataset sederhana seperti MNIST, 32 dimensi sudah cukup karena digit angka memiliki struktur yang relatif sederhana. Untuk dataset yang lebih kompleks seperti gambar wajah, kita mungkin perlu 128 atau 256 dimensi.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Pemilihan ukuran bottleneck adalah tradeoff yang penting. Semakin kecil dimensi latent, semakin besar kompresi, tapi risiko kehilangan informasi juga meningkat. Model mungkin hanya bisa merekonstruksi garis besar tanpa detail halus. Sebaliknya, bottleneck yang terlalu besar tidak memberikan kompresi bermakna dan model cenderung overfitting dengan hanya menyalin input ke output. Nilai 32 adalah titik awal yang baik untuk dataset sesederhana MNIST.
Melatih Autoencoder dengan Loss Function dan Optimizer
Setelah arsitektur siap, langkah berikutnya adalah melatih model. Loss function yang kita gunakan adalah Mean Squared Error (MSE). Fungsi ini menghitung rata-rata kuadrat selisih antara input asli dan output rekonstruksi. MSE sensitif terhadap error besar. Jika satu piksel memiliki error yang besar, kuadratnya akan mendominasi loss. Ini mendorong model untuk tidak membuat kesalahan besar di piksel mana pun. Semakin kecil nilai MSE, semakin baik decoder merekonstruksi input dari representasi latent.
Optimizer Adam dengan learning rate 1e-3 menjadi pilihan yang andal. Adam menggabungkan keunggulan dua metode sekaligus: momentum yang mempercepat konvergensi di arah yang konsisten, dan adaptive learning rate yang menyesuaikan langkah untuk setiap parameter. Untuk autoencoder, Adam umumnya lebih stabil dibanding SGD biasa. Sebelum training, pastikan data sudah dinormalisasi ke rentang [0,1] agar sesuai dengan output Sigmoid di decoder. Dataset MNIST yang di-load dengan ToTensor() sudah memenuhi syarat ini.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.view(-1))
])
train_dataset = torchvision.datasets.MNIST(
root='./data', train=True, download=True, transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 20
loss_history = []
for epoch in range(num_epochs):
total_loss = 0
for data, _ in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, data)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
loss_history.append(avg_loss)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')Output:
Epoch [1/20], Loss: 0.0601
Epoch [2/20], Loss: 0.0315
Epoch [3/20], Loss: 0.0265
Epoch [4/20], Loss: 0.0232
Epoch [5/20], Loss: 0.0209
Epoch [6/20], Loss: 0.0195
Epoch [7/20], Loss: 0.0180
Epoch [8/20], Loss: 0.0167
Epoch [9/20], Loss: 0.0159
Epoch [10/20], Loss: 0.0152
Epoch [11/20], Loss: 0.0146
Epoch [12/20], Loss: 0.0141
Epoch [13/20], Loss: 0.0136
Epoch [14/20], Loss: 0.0132
Epoch [15/20], Loss: 0.0128
Epoch [16/20], Loss: 0.0124
Epoch [17/20], Loss: 0.0119
Epoch [18/20], Loss: 0.0116
Epoch [19/20], Loss: 0.0113
Epoch [20/20], Loss: 0.0110Setiap epoch, model memproses seluruh dataset dalam batch-batch kecil. Satu batch berisi 128 gambar. Untuk setiap batch, kita melakukan forward pass untuk menghasilkan rekonstruksi, lalu menghitung MSE antara output dan input. Backward pass menghitung gradien loss terhadap setiap parameter, dan optimizer memperbarui weight ke arah yang menurunkan loss.
Dari output, kita bisa melihat pola yang khas. Loss turun cepat di epoch awal (dari 0.0607 ke 0.0332), lalu melambat secara gradual. Ini wajar karena model pertama-tama menangkap struktur dasar (bentuk digit secara umum), lalu menghaluskan detail halus. Setelah epoch ke-15, penurunan loss mulai mendatar. Jika kurva loss sudah mendatar, menambah epoch mungkin tidak memberikan perbaikan signifikan. Sebaliknya, jika loss terus turun tanpa mendatar, model mungkin mulai overfitting.
Memonitor kurva loss sangat penting. Plot loss terhadap epoch memberi kita gambaran apakah learning rate terlalu besar (loss naik-turun tidak stabil) atau terlalu kecil (penurunan sangat lambat). Untuk dataset yang lebih kompleks, kita biasanya menggunakan validation set untuk memonitor overfitting, yaitu dengan menghitung loss pada data yang tidak pernah dilihat model saat training.
Ekstraksi Fitur Latent untuk Tugas Downstream
Keunggulan utama autoencoder terletak pada encoder yang sudah terlatih. Kita bisa menggunakan encoder sebagai feature extractor yang berdiri sendiri, mengambil representasi 32 dimensi dari data mana pun. Proses ini sangat efisien. Setelah encoder terlatih, kita tidak perlu menjalankan decoder lagi. Cukup forward pass melalui encoder untuk mendapatkan fitur latent.
Representasi 32 dimensi ini kemudian menjadi input untuk classifier seperti Logistic Regression atau Random Forest. Bayangkan kita ingin mengklasifikasikan jutaan gambar. Menyimpan 784 angka per gambar jelas memakan banyak memori dan waktu komputasi. Dengan fitur autoencoder, kita hanya menyimpan 32 angka per gambar, dan classifier bekerja jauh lebih cepat.
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
def extract_latent_features(model, dataloader):
model.eval()
features = []
labels = []
with torch.no_grad():
for data, target in dataloader:
encoded = model.encoder(data)
features.append(encoded.numpy())
labels.append(target.numpy())
return np.concatenate(features), np.concatenate(labels)
test_dataset = torchvision.datasets.MNIST(
root='./data', train=False, download=True, transform=transform
)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)
X_latent, y_true = extract_latent_features(model, test_loader)
X_train, X_test, y_train, y_test = train_test_split(
X_latent, y_true, test_size=0.3, random_state=42
)
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
acc_latent = accuracy_score(y_test, y_pred)
print(f'Akurasi dengan fitur autoencoder: {acc_latent:.4f}')Output:
Akurasi dengan fitur autoencoder: 0.9097Kode di atas mengekstrak fitur 32 dimensi untuk setiap gambar MNIST, lalu melatih LogisticRegression pada fitur tersebut. Akurasinya biasanya berada di kisaran 90-95 persen. Angka ini cukup mengesankan, mengingat kita hanya menggunakan 32 angka dari 784 piksel asli. Ini membuktikan bahwa representasi latent benar-benar menangkap informasi esensial untuk membedakan digit.
Sebagai perbandingan, classifier yang dilatih langsung pada raw data 784 dimensi mungkin mencapai akurasi 92-96 persen. Selisih 1-2 persen ini adalah harga yang wajar untuk pengurangan dimensi sebesar 25 kali lipat. Dalam skenario dunia nyata dengan jutaan data, penghematan memori dan waktu komputasi seringkali lebih berharga dibanding kenaikan akurasi marginal.
Representasi latent juga bisa divisualisasikan menggunakan PCA atau t-SNE. Jika kita plot 32 dimensi latent ke ruang 2D dengan t-SNE, kita akan melihat bahwa gambar dari kelas yang sama (misalnya semua digit 7) berkelompok bersama. Ini membuktikan bahwa autoencoder benar-benar mempelajari struktur manifold data yang bermakna, bukan sekadar menyalin input. Visualisasi ini juga berguna untuk mendeteksi outlier atau anomali. Data yang tidak biasa akan jatuh di area yang jauh dari kluster normal.
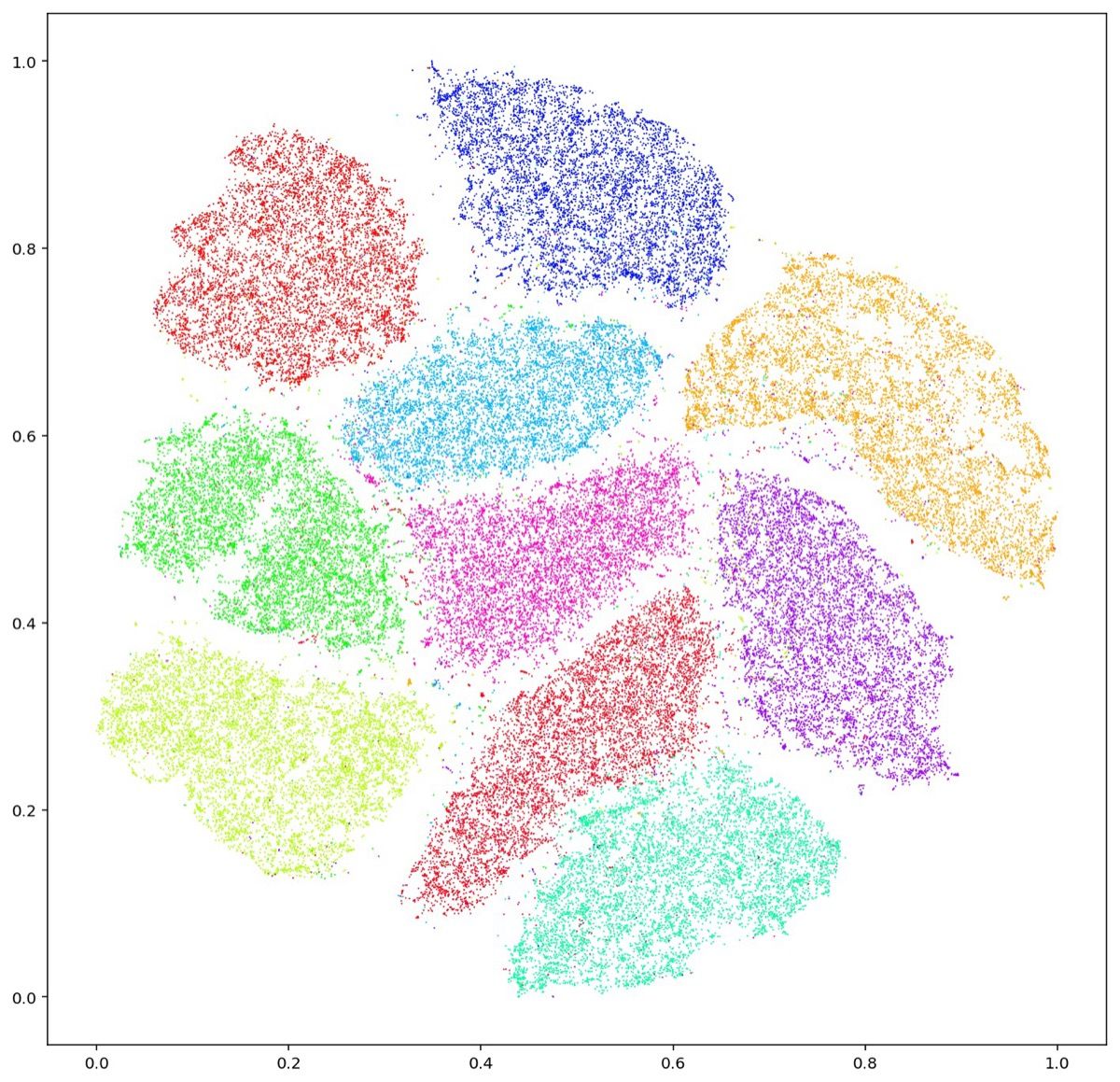
Gambar: Visualisasi t-SNE dari dataset MNIST yang menunjukkan pengelompokan alami digit-digit berdasarkan representasi latent — Sumber: [Wikimedia Commons (Kyle McDonald, CC BY 2.0)](https://commons.wikimedia.org/wiki/File:T-SNE_Embedding_of_MNIST.png)
Variasi Autoencoder dan Eksperimen Hyperparameter
Autoencoder bukan hanya satu arsitektur kaku. Ada beberapa variasi yang dirancang untuk kebutuhan spesifik. Denoising Autoencoder, misalnya, menambahkan noise pada input namun target tetap berupa input bersih. Noise bisa berupa Gaussian noise (menambahkan bilangan random ke setiap piksel) atau dropout (memati-kan sebagian piksel secara acak). Pendekatan ini memaksa encoder mempelajari representasi yang lebih robust. Model tidak bisa hanya menyalin input karena inputnya rusak. Ia harus memahami struktur data yang mendasarinya.
Sparse Autoencoder menambahkan regularisasi sparsity pada aktivasi di layer latent. Dengan menambahkan penalti ke loss function untuk setiap neuron latent yang aktif, model didorong mempelajari fitur yang lebih spesifik dan terinterpretasi. Misalnya, satu neuron latent mungkin khusus mendeteksi garis vertikal, sementara neuron lain mendeteksi lingkaran. Variasi ini berguna ketika kita ingin memahami fitur apa saja yang dipelajari model.
Eksperimen dengan hyperparameter juga penting. Coba ubah encoding_dim dari 32 menjadi 8, lalu menjadi 64. Dengan dimensi 8, rekonstruksi akan lebih buram karena informasi terlalu dipadatkan. Dengan dimensi 64, rekonstruksi akan lebih tajam, tapi model mungkin tidak belajar kompresi yang bermakna. Ukuran batch juga berpengaruh. Batch terlalu kecil (16) membuat gradien noisy dan training tidak stabil. Batch terlalu besar (512) memperlambat konvergensi per epoch.
Sebagai latihan, Anda bisa bereksperimen dengan menambah jumlah layer encoder menjadi empat atau lima, atau mengganti fungsi aktivasi ReLU dengan LeakyReLU yang lebih toleran terhadap neuron mati. Atau coba ganti optimizer Adam dengan SGD dan observasi perbedaan kecepatan konvergensi. Kuncinya adalah memulai dari konfigurasi sederhana, lalu bereksperimen secara sistematis dengan mengubah satu variabel pada satu waktu. Dokumentasikan setiap hasil agar Anda bisa membandingkan dan menarik kesimpulan yang valid.
Autoencoder membuka pintu ke dunia unsupervised deep learning yang luas. Konsep yang Anda pelajari di sini, seperti representasi latent dan arsitektur encoder-decoder, menjadi fondasi untuk model yang lebih canggih seperti Variational Autoencoder (VAE) dan model generatif lainnya. Siap menguasai konsep autoencoder dan teknik feature learning lainnya? Lanjutkan perjalanan belajar Anda di program Deep Learning Rumah Coding.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.


