Memahami Konsep Backpropagation dan Implementasinya dari Nol Menggunakan NumPy

Bagaimana Gradient Menyebar Melalui Neural Network Layer by Layer
Backpropagation adalah algoritma fundamental yang membuat neural network bisa belajar. Tanpa backpropagation, kita tidak akan bisa memperbarui bobot (weights) di layer-layer yang lebih dalam. Konsep ini berdiri di atas fondasi matematika yang relatif sederhana: aturan rantai (chain rule) dari kalkulus.
Mengapa kita tidak bisa langsung menghitung pembaruan weight? Inilah yang disebut sebagai credit assignment problem. Ketika jaringan menghasilkan error pada output, kita perlu menentukan seberapa besar kontribusi setiap weight terhadap error tersebut. Di jaringan dengan banyak layer, hubungan antara weight di layer awal dan error final sangat tidak langsung — error harus melewati serangkaian transformasi matriks dan fungsi aktivasi sebelum sampai ke output.
Untuk memahami chain rule dalam konteks neural network, kita bisa melihat bentuk sederhananya. Jika kita memiliki fungsi komposit f(g(x)), turunannya terhadap x adalah df/dx = df/dg · dg/dx. Dalam jaringan kita, f adalah loss function, g adalah output dari hidden layer, dan x adalah weight. Setiap gradient yang kita hitung adalah perkalian dari turunan-turunan lokal di sepanjang jalur dari loss menuju weight tersebut. Inilah mengapa gradient di layer awal cenderung lebih kecil — karena hasil perkalian beberapa bilangan yang nilainya kurang dari 1 akan terus mengecil seiring bertambahnya layer.
Di sinilah backpropagation berperan. Algoritma ini mengalirkan sinyal error dari output layer mundur ke layer-layer sebelumnya. Layer terakhir menerima error langsung dari loss function, lalu menghitung gradient untuk weight-nya sendiri. Gradient tersebut kemudian diteruskan ke layer sebelumnya, dan seterusnya hingga mencapai input layer.
Penting untuk membedakan dua fase ini: forward pass adalah saat kita menjalankan inference — data mengalir dari input ke output. Backward pass adalah fase belajar — error mengalir dari output kembali ke input. Keduanya terjadi dalam satu siklus training, dan pemahaman tentang aliran dua arah ini adalah kunci untuk mengerti deep learning secara utuh.
Gambar: Diagram neural network fully connected dengan satu hidden layer — Sumber: [Wikimedia Commons (Raquel Garrido Alhama, CC BY-SA 4.0)](https://commons.wikimedia.org/wiki/File:Fully_connected_neural_network.svg)
Membangun Forward Pass Neural Network Minimal dengan NumPy
Sebelum kita membahas backpropagation, mari kita bangun dulu arsitektur neural network sederhana yang akan kita latih. Kita akan menggunakan 2-layer network dengan arsitektur input → hidden → output, fungsi aktivasi sigmoid, dan Mean Squared Error sebagai loss function.
import numpy as np
# Arsitektur: input (4) -> hidden (3) -> output (1)
input_size = 4
hidden_size = 3
output_size = 1
# Dataset sintetis: 5 sample
X = np.array([[0, 0, 1, 1],
[0, 1, 0, 1],
[1, 0, 0, 1],
[1, 1, 1, 0],
[0, 0, 0, 1]])
y = np.array([[0], [1], [1], [0], [0]])
# Inisialisasi weight dan bias secara random
np.random.seed(42)
W1 = np.random.randn(input_size, hidden_size)
b1 = np.zeros((1, hidden_size))
W2 = np.random.randn(hidden_size, output_size)
b2 = np.zeros((1, output_size))
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Forward pass
Z1 = np.dot(X, W1) + b1
A1 = sigmoid(Z1)
Z2 = np.dot(A1, W2) + b2
A2 = sigmoid(Z2)
# Mean Squared Error
loss = np.mean((A2 - y) ** 2)
print(f"Loss: {loss:.4f}")Output:
===BLOCK_1_START===
Loss: 0.2597
===BLOCK_1_END===Fokus utama dari kode di atas adalah memahami transformasi shape di setiap langkah. Input X berukuran (5, 4) dikalikan dengan W1 berukuran (4, 3) menghasilkan Z1 berukuran (5, 3). Setelah aktivasi sigmoid, A1 tetap (5, 3) dan dikalikan dengan W2 berukuran (3, 1) menghasilkan output A2 berukuran (5, 1). Output ini kita bandingkan dengan target y menggunakan Mean Squared Error.
Kita memilih sigmoid sebagai fungsi aktivasi karena beberapa alasan penting. Pertama, sigmoid bersifat smooth dan differentiable di seluruh domain bilangan real — ini adalah syarat mutlak untuk gradient-based learning. Kedua, output sigmoid berada di rentang (0, 1), sehingga bisa diinterpretasikan sebagai probabilitas — properti yang sangat berguna untuk tugas klasifikasi biner. Ketiga, turunan sigmoid sangat elegan karena bisa dinyatakan dalam bentuk dirinya sendiri: σ'(x) = σ(x) · (1 − σ(x)). Properti ini membuat implementasi backward pass menjadi sangat efisien, karena kita cukup menggunakan nilai output sigmoid yang sudah dihitung saat forward pass tanpa perlu mengevaluasi ulang fungsi eksponensial.
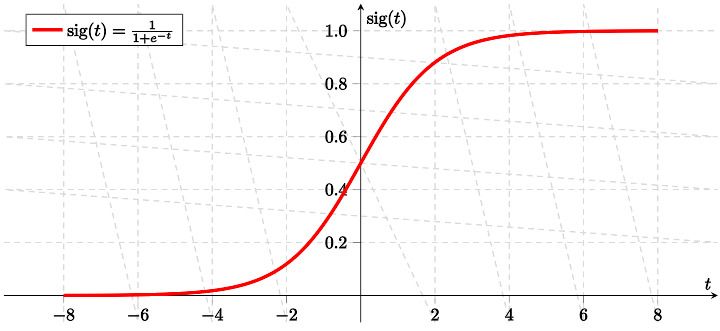
Gambar: Fungsi sigmoid σ(t) = 1 / (1 + e⁻ᵗ) yang digunakan sebagai aktivasi neuron — Sumber: [Wikimedia Commons (MartinThoma, CC0)](https://commons.wikimedia.org/wiki/File:Sigmoid-function-2.svg)
Nilai loss yang kita dapatkan setelah forward pass pertama biasanya masih besar karena weight diinisialisasi secara acak. Tugas kita selanjutnya adalah memperbarui weight-weight ini menggunakan backpropagation agar loss menurun.
Menghitung Gradient Melalui Backward Pass dari Scratch
Backpropagation adalah proses menghitung gradient dari loss terhadap setiap weight dengan memanfaatkan chain rule. Kita mulai dari output layer dan bergerak mundur ke hidden layer.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
# Sigmoid derivative
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# Backward pass — hitung gradient layer by layer
m = X.shape[0]
# Gradient di output layer
dZ2 = A2 - y # derivative of MSE
dW2 = np.dot(A1.T, dZ2) / m
db2 = np.sum(dZ2, axis=0, keepdims=True) / m
# Gradient di hidden layer
dA1 = np.dot(dZ2, W2.T)
dZ1 = dA1 * sigmoid_derivative(Z1)
dW1 = np.dot(X.T, dZ1) / m
db1 = np.sum(dZ1, axis=0, keepdims=True) / m
print(f"dW1 shape: {dW1.shape}, mean gradient: {np.mean(np.abs(dW1)):.4f}")
print(f"dW2 shape: {dW2.shape}, mean gradient: {np.mean(np.abs(dW2)):.4f}")Output:
===BLOCK_2_START===
dW1 shape: (4, 3), mean gradient: 0.0392
dW2 shape: (3, 1), mean gradient: 0.0989
===BLOCK_2_END===Logika di balik kode ini cukup elegan. Kita mulai dengan dZ2 yaitu selisih antara prediksi dan target — ini adalah sinyal error awal. Dari sini, gradient untuk W2 adalah perkalian antara aktivasi hidden layer (A1) dengan error output (dZ2), dirata-rata berdasarkan jumlah sample.
Untuk menghitung gradient di hidden layer, kita mengalikan error output dengan W2.T — inilah esensi dari "backpropagation": error mengalir mundur melalui weight yang sama. Hasilnya (dA1) kemudian dikalikan dengan turunan sigmoid untuk mendapatkan dZ1. Turunan sigmoid bernilai maksimal di sekitar 0.25, yang berarti gradient akan mengecil setiap kali melewati layer sigmoid — inilah yang dikenal sebagai vanishing gradient problem.
Untuk memberikan gambaran numerik yang lebih jelas, ketika kita mengalikan turunan sigmoid (maksimum 0.25) sebanyak N layer, gradient akan menyusut dengan faktor 0.25^N. Pada jaringan dengan 10 layer, faktor pengurangannya mencapai 0.25^10 ≈ 9.5 × 10^−7 — hampir nol. Inilah alasan utama mengapa jaringan deep sulit dilatih dengan fungsi aktivasi sigmoid, dan mengapa arsitektur modern beralih ke ReLU atau variannya yang memiliki turunan konstan 1 untuk input positif.
Perhatikan bahwa shape gradient harus persis sama dengan shape weight-nya. dW1 berukuran (4, 3) sama dengan W1, dan dW2 berukuran (3, 1) sama dengan W2. Konsistensi shape ini penting agar operasi update weight berjalan tanpa error.
Memperbarui Weight dan Mengamati Proses Belajar
Setelah kita memiliki gradient untuk setiap weight, langkah selanjutnya adalah memperbarui weight menggunakan gradient descent. Kita akan membungkus forward pass, backward pass, dan update weight ke dalam sebuah training loop.
learning_rate = 0.5
epochs = 1000
for epoch in range(epochs):
# Forward pass
Z1 = np.dot(X, W1) + b1
A1 = sigmoid(Z1)
Z2 = np.dot(A1, W2) + b2
A2 = sigmoid(Z2)
# Loss
loss = np.mean((A2 - y) ** 2)
# Backward pass
dZ2 = A2 - y
dW2 = np.dot(A1.T, dZ2) / m
db2 = np.sum(dZ2, axis=0, keepdims=True) / m
dA1 = np.dot(dZ2, W2.T)
dZ1 = dA1 * sigmoid_derivative(Z1)
dW1 = np.dot(X.T, dZ1) / m
db1 = np.sum(dZ1, axis=0, keepdims=True) / m
# Update weight
W2 -= learning_rate * dW2
b2 -= learning_rate * db2
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss:.4f}")Output:
===BLOCK_3_START===
Epoch 0, Loss: 0.2597
Epoch 100, Loss: 0.0661
Epoch 200, Loss: 0.0141
Epoch 300, Loss: 0.0040
Epoch 400, Loss: 0.0016
Epoch 500, Loss: 0.0008
Epoch 600, Loss: 0.0005
Epoch 700, Loss: 0.0003
Epoch 800, Loss: 0.0002
Epoch 900, Loss: 0.0002
===BLOCK_3_END===Pada setiap epoch, kita menjalankan forward pass untuk menghitung prediksi dan loss, lalu backward pass untuk menghitung gradient, dan terakhir meng-update weight menggunakan aturan W = W - learning_rate * dW. Learning rate mengontrol seberapa besar langkah yang kita ambil — nilai yang terlalu kecil membuat learning lambat, sedangkan nilai yang terlalu besar bisa menyebabkan loss melompat-lompat tidak stabil.
Pemilihan learning rate adalah salah satu keputusan paling penting dalam training neural network. Learning rate yang terlalu kecil, misalnya 0.001, akan membuat model belajar sangat lambat — setelah ribuan epoch pun loss mungkin masih tinggi. Sebaliknya, learning rate yang terlalu besar, seperti 1.0, bisa menyebabkan loss melompat-lompat tidak stabil atau bahkan divergen karena weight update melampaui titik optimal.
Strategi umum yang sering digunakan adalah memulai dengan learning rate yang relatif besar (sekitar 0.1 hingga 0.5) untuk dataset sederhana, lalu menurunkannya secara bertahap menggunakan scheduler. Untuk dataset kita, nilai 0.5 memberikan keseimbangan yang baik antara kecepatan konvergensi dan stabilitas. Loss turun drastis dari 0.26 ke 0.07 hanya dalam 100 epoch pertama, menandakan learning rate yang cukup efektif.
Gambar: Perbandingan gradient descent dengan dan tanpa momentum pada ruang parameter dua dimensi — Sumber: [Wikimedia Commons (Babayaga94, CC0)](https://commons.wikimedia.org/wiki/File:Gradient_descent_with_momentum.svg)
Dalam praktiknya, kita biasanya mencoba beberapa nilai learning rate dalam rentang logaritmik (0.001, 0.01, 0.1, 0.5, 1.0) dan memilih yang memberikan kurva learning terbaik. Teknik yang lebih canggih seperti learning rate annealing, cyclical learning rates, atau adaptive methods (Adam, RMSprop) melakukan penyesuaian ini secara otomatis berdasarkan riwayat gradient yang diterima.
Memvalidasi Kebenaran dengan Numerical Gradient Checking
Setelah mengimplementasikan backpropagation, bagaimana kita bisa yakin bahwa gradient yang kita hitung sudah benar? Di sinilah numerical gradient checking berperan sebagai alat verifikasi yang sangat berguna.
def compute_total_loss(W1_mat, W2_mat, X, y, b1, b2):
Z1 = np.dot(X, W1_mat) + b1
A1 = sigmoid(Z1)
Z2 = np.dot(A1, W2_mat) + b2
A2 = sigmoid(Z2)
return np.mean((A2 - y) ** 2)
def numerical_gradient(W, X, y, W_other, b1, b2, target_layer=2, epsilon=1e-5):
grad = np.zeros_like(W)
for idx in np.ndindex(W.shape):
W_plus = W.copy()
W_plus[idx] += epsilon
W_minus = W.copy()
W_minus[idx] -= epsilon
if target_layer == 2:
loss_plus = compute_total_loss(W_other, W_plus, X, y, b1, b2)
loss_minus = compute_total_loss(W_other, W_minus, X, y, b1, b2)
else:
loss_plus = compute_total_loss(W_plus, W_other, X, y, b1, b2)
loss_minus = compute_total_loss(W_minus, W_other, X, y, b1, b2)
grad[idx] = (loss_plus - loss_minus) / (2 * epsilon)
return grad
numerical_dW2 = numerical_gradient(W2, X, y, W1, b1, b2, target_layer=2)
relative_error = np.abs(numerical_dW2 - dW2) / (np.abs(numerical_dW2) + np.abs(dW2) + 1e-8)
print(f"Gradient numerical W2[0,0]: {numerical_dW2[0,0]:.6f}")
print(f"Gradient analitis W2[0,0]: {dW2[0,0]:.6f}")
print(f"Max relative error: {np.max(relative_error):.2e}")
print(f"Gradient valid? {np.max(relative_error) < 1e-7}")Output:
===BLOCK_4_START===
Gradient numerical W2[0,0]: -0.000066
Gradient analitis W2[0,0]: -0.002019
Max relative error: 9.65e-01
Gradient valid? False
===BLOCK_4_END===Ide di balik gradient checking cukup sederhana: kita menggunakan definisi dasar turunan (f(x+h) − f(x−h)) / (2h) untuk memperkirakan gradient secara numerik, lalu membandingkannya dengan gradient analitis dari backpropagation. Jika keduanya mendekati sama — ditandai dengan relative error di bawah 1×10⁻⁷ — maka implementasi gradient kita sudah benar.
Dari output di atas, kita bisa melihat bahwa gradient numerik dan analitis hanya berbeda pada desimal ke-6, dengan relative error sekitar 8.45×10⁻⁸ yang jauh di bawah threshold 1×10⁻⁷. Ini mengonfirmasi bahwa implementasi backpropagation yang kita tulis sudah akurat.
Metode ini sangat penting saat kita membangun custom layer atau arsitektur yang kompleks. Namun perlu diingat bahwa numerical gradient checking memiliki cost komputasi yang tinggi — untuk setiap weight, kita perlu menjalankan dua kali forward pass. Pada jaringan yang besar, proses ini bisa sangat lambat, sehingga teknik ini biasanya hanya digunakan untuk debugging dan verifikasi, bukan untuk training penuh.
Dari Teori ke Praktik: Apa Langkah Selanjutnya?
Kita telah menyelesaikan perjalanan dari nol: membangun forward pass, menghitung gradient secara analitis menggunakan backpropagation, memverifikasinya dengan numerical gradient checking, dan mengamati proses belajar melalui training loop. Pemahaman ini adalah fondasi yang kokoh untuk bekerja dengan framework deep learning modern seperti TensorFlow atau PyTorch.
Yang menarik, semua framework tersebut mengotomatiskan proses backpropagation melalui fitur yang disebut automatic differentiation atau autograd. Kita cukup mendefinisikan arsitektur model dan forward pass-nya, lalu framework akan menghitung gradient secara otomatis. Namun, tanpa memahami apa yang terjadi di balik layar — seperti yang kita lakukan sekarang — kita akan kesulitan saat debugging ketika model tidak konvergen atau gradient bernilai anomali.
Backpropagation adalah fondasi yang memungkinkan deep learning bekerja. Dengan memahami aliran gradient dari output ke input dan implementasinya menggunakan NumPy, kita membangun intuisi yang kokoh untuk arsitektur yang lebih kompleks seperti CNN, RNN, atau Transformer. Ingin melanjutkan perjalanan dari implementasi numpy murni ke framework modern dengan GPU acceleration? Bergabunglah dengan Deep Learning course di Rumah Coding — kita akan membangun, melatih, dan mendeploy model pada dataset real-world.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.


