Memahami Konsep Transformer dari Awal: Implementasi Scaled Dot-Product Attention dan Multi-Head Attention dengan PyTorch

Batasan Arsitektur Sekuensial dan Kebutuhan akan Mekanisme Baru
Sebelum Transformer diperkenalkan oleh Vaswani et al. pada tahun 2017, model sekuensial seperti RNN dan LSTM mendominasi tugas-tugas Natural Language Processing. Kedua arsitektur ini memiliki kelemahan struktural yang mendasar: pemrosesan dilakukan secara sekuensial token demi token. Model harus menunggu token ke-i selesai diproses sebelum melanjutkan ke token ke-i+1, yang membuat paralelisasi menjadi tidak mungkin dilakukan. Pada sekuens yang panjang, masalah vanishing gradient semakin parah karena gradien harus merambat melalui banyak langkah waktu.
Attention mechanism hadir sebagai solusi atas keterbatasan ini. Konsepnya sederhana namun revolusioner: alih-alih memampatkan seluruh informasi ke dalam satu context vector terakhir, model dapat melihat langsung ke seluruh posisi input dan secara dinamis menentukan bagian mana yang paling relevan. Bayangkan seperti sistem sorot yang secara dinamis menyesuaikan kecerahan di setiap bagian input — semakin terang pada bagian yang relevan.
Transformer mengadopsi arsitektur encoder-decoder, namun untuk artikel ini kita akan fokus pada sisi encoder. Encoder Transformer terdiri dari tumpukan blok identik, di mana setiap blok berisi mekanisme self-attention dan feed-forward network. Self-attention inilah yang memungkinkan setiap token berinteraksi langsung dengan semua token lain dalam satu langkah komputasi, tanpa melalui jalur recurrent. Keputusan untuk membuang recurrence sepenuhnya dan hanya mengandalkan attention terbukti menghasilkan model yang tidak lebih akurat tetapi juga jauh lebih efisien untuk dilatih.
Scaled Dot-Product Attention Menjadi Jantung Komputasi Transformer
Inti dari komputasi Transformer adalah mekanisme Scaled Dot-Product Attention. Setiap token dalam input diproyeksikan menjadi tiga vektor berbeda melalui linear projection: Query (Q), Key (K), dan Value (V). Query merepresentasikan "apa yang dicari" oleh token saat ini, Key merepresentasikan "identitas" dari setiap token, dan Value adalah "informasi aktual" yang akan diambil.
Rumus attention didefinisikan sebagai:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V $$
Perkalian matriks Q dengan K^T menghasilkan skor ketertarikan antara setiap pasangan token. Semakin tinggi skornya, semakin relevan token tersebut terhadap token yang sedang diproses. Fungsi scaling factor $\sqrt{d_k}$ sangat penting karena mencegah nilai dot product masuk ke region saturasi softmax. Tanpa scaling, untuk dimensi yang besar, nilai dot product bisa sangat tinggi sehingga gradien softmax mendekati nol dan proses pembelajaran terhenti.
Setelah scaling, kita menerapkan softmax untuk mengubah skor menjadi distribusi probabilitas, lalu mengalikannya dengan V. Hasilnya adalah representasi kontekstual setiap token yang sudah mempertimbangkan seluruh token lain dalam sequence. Diagram berikut menunjukkan alur komputasi Scaled Dot-Product Attention secara visual:
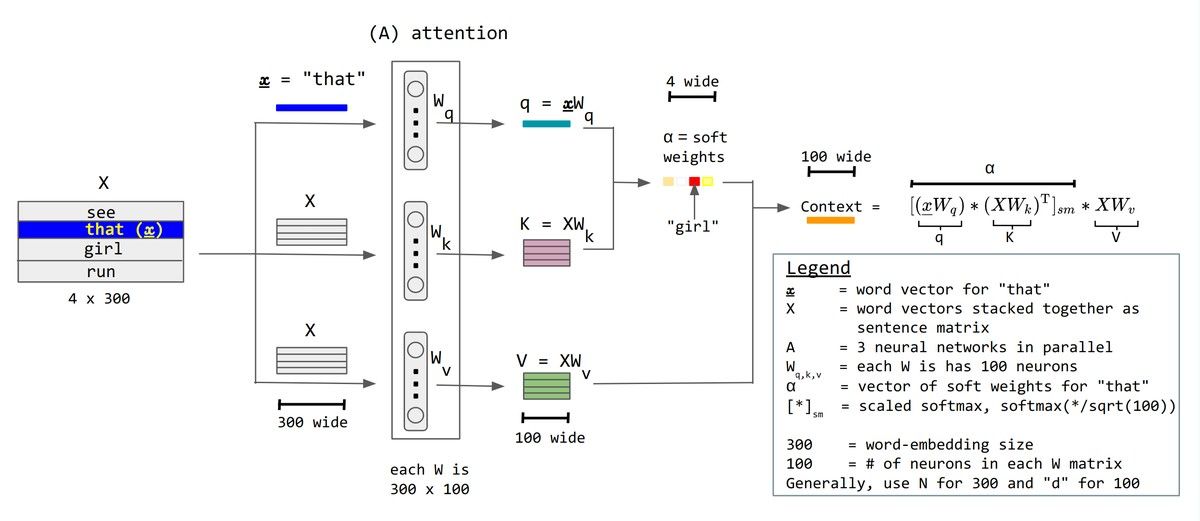
Gambar: Alur komputasi Scaled Dot-Product Attention melalui satu attention head — Sumber: [Wikimedia Commons (Numiri, CC BY-SA 4.0)](https://commons.wikimedia.org/wiki/File:Attention-qkv.png)
Mari kita implementasikan:
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Q: (batch, seq_len, d_k)
K: (batch, seq_len, d_k)
V: (batch, seq_len, d_v)
"""
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, V)
return output, attention_weights
# Contoh penggunaan
batch, seq_len, d_k = 2, 4, 8
Q = torch.randn(batch, seq_len, d_k)
K = torch.randn(batch, seq_len, d_k)
V = torch.randn(batch, seq_len, d_k)
output, weights = scaled_dot_product_attention(Q, K, V)
print(f"Output shape: {output.shape}")
print(f"Attention weights shape: {weights.shape}")
print(f"Sample attention weights:\n{weights[0]}")Output:
Output shape: torch.Size([2, 4, 8])
Attention weights shape: torch.Size([2, 4, 4])
Sample attention weights:
tensor([[0.5614, 0.0462, 0.2749, 0.1175],
[0.1243, 0.0117, 0.6092, 0.2549],
[0.2282, 0.0634, 0.4236, 0.2848],
[0.2599, 0.0661, 0.4040, 0.2700]])Perhatikan output attention weights berbentuk matriks 4x4 untuk setiap sample dalam batch. Baris ke-i menunjukkan seberapa besar token ke-i memperhatikan setiap token lain. Nilai yang lebih tinggi menunjukkan ketergantungan yang lebih kuat. Output akhir memiliki dimensi yang sama dengan input, tetapi setiap vektor sudah merupakan representasi kontekstual yang kaya informasi.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Multi-Head Attention Membantu Belajar dari Berbagai Subruang Representasi
Satu pasangan Q, K, V hanya mampu menangkap satu jenis pola relasi antar token. Dalam praktiknya, token dalam sebuah kalimat memiliki berbagai jenis hubungan: hubungan sintaksis (subjek-predikat), hubungan semantik (sinonim-antonim), dan hubungan posisional (jarak antar kata). Multi-Head Attention memungkinkan model menangkap semua jenis hubungan ini secara simultan.
Mekanisme kerjanya: kita membagi Q, K, V menjadi h buah head. Setiap head memiliki linear projection terpisah sehingga masing-masing belajar memproyeksikan input ke subruang representasi yang berbeda. Scaled Dot-Product Attention dijalankan secara paralel pada setiap head. Hasil dari semua head kemudian digabungkan (concatenate) dan diproyeksikan linear sekali lagi.
Hubungan antara dimensi model (d_model), jumlah head (h), dan dimensi per head (d_k) adalah: d_k = d_model / h. Ini memastikan total parameter tidak bertambah secara signifikan meskipun kita menambahkan lebih banyak head. Setiap head hanya melihat subruang yang lebih kecil, dan semuanya berjalan paralel.
Ilustrasi berikut dari paper asli "Attention Is All You Need" menunjukkan bagaimana Multi-Head Attention memproyeksikan Q, K, V secara paralel ke h buah head, lalu menggabungkan hasilnya:
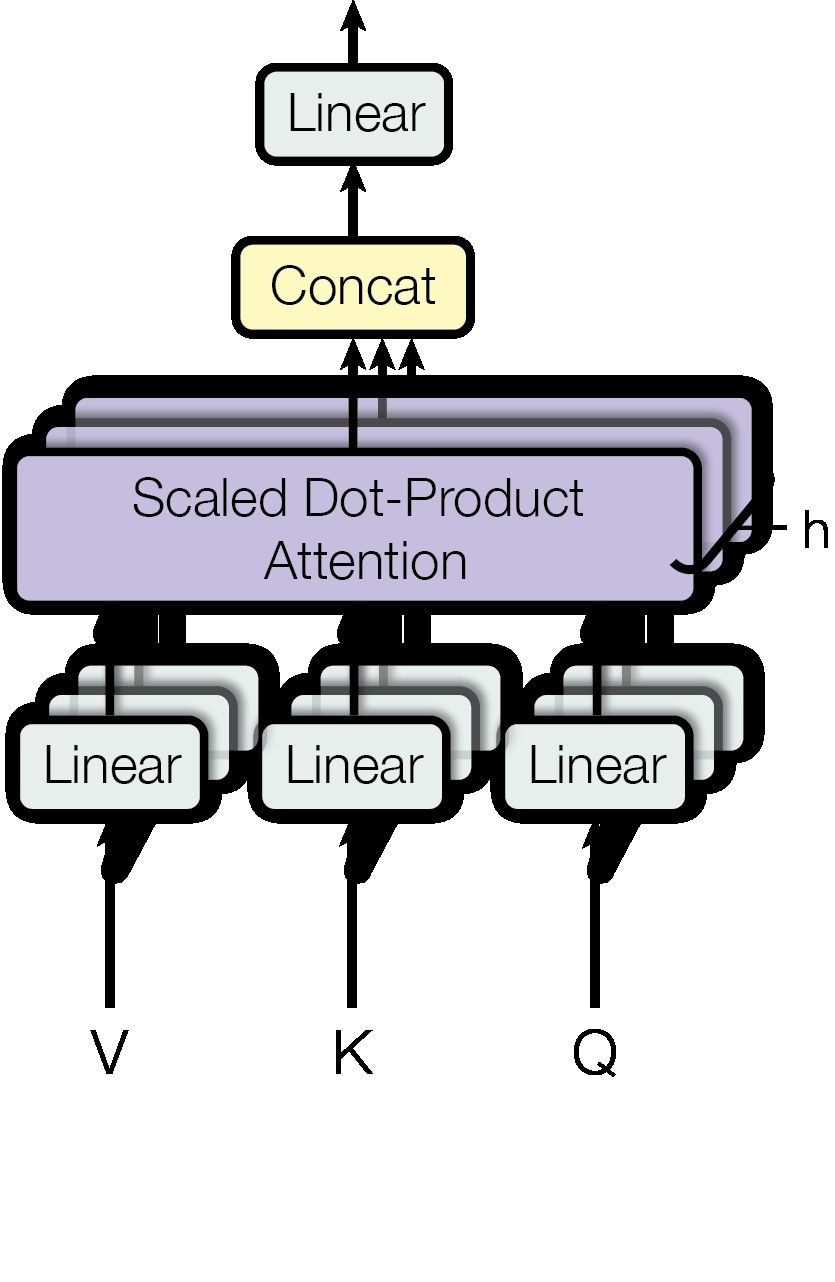
Gambar: Arsitektur Multi-Head Attention dengan parallel heads — Sumber: [Wikimedia Commons (Google, CC BY-SA 4.0)](https://commons.wikimedia.org/wiki/File:Attention_Is_All_You_Need_-_Multiheaded_Attention.png)
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h):
super().__init__()
self.h = h
self.d_k = d_model // h
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, mask=None):
batch = Q.size(0)
Q = self.W_q(Q).view(batch, -1, self.h, self.d_k).transpose(1, 2)
K = self.W_k(K).view(batch, -1, self.h, self.d_k).transpose(1, 2)
V = self.W_v(V).view(batch, -1, self.h, self.d_k).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attention_weights, V)
context = context.transpose(1, 2).contiguous().view(batch, -1, self.h * self.d_k)
output = self.W_o(context)
return output, attention_weights
# Contoh penggunaan
d_model, h = 64, 8
mha = MultiHeadAttention(d_model, h)
x = torch.randn(2, 4, d_model)
output, attn_weights = mha(x, x, x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
print(f"Attention weights shape: {attn_weights.shape}")Output:
Input shape: torch.Size([2, 4, 64])
Output shape: torch.Size([2, 4, 64])
Attention weights shape: torch.Size([2, 8, 4, 4])Perhatikan bahwa attention weights memiliki 4 dimensi: batch, 8 heads, seq_len_Q, seq_len_K. Setiap head menghasilkan matriks perhatian 4x4 yang unik, menunjukkan pola relasi yang berbeda. Output akhir tetap memiliki dimensi (batch, seq_len, d_model) setelah projection terakhir.
Arsitektur Encoder Block Menyatukan Semua Komponen
Encoder block adalah unit komputasi yang menggabungkan Multi-Head Attention dengan Feed-Forward Network melalui residual connections dan layer normalization. Setiap blok memiliki dua sub-layer utama.
Sub-layer pertama adalah Multi-Head Self-Attention, di mana Q, K, V semuanya berasal dari output layer sebelumnya. Output attention ditambahkan dengan input aslinya melalui residual connection, lalu dinormalisasi dengan layer normalization. Residual connection memungkinkan gradien mengalir langsung melalui jaringan, mengatasi masalah vanishing gradient pada model yang sangat dalam.
Sub-layer kedua adalah Feed-Forward Network (FFN) yang terdiri dari dua linear layer dengan aktivasi ReLU di antaranya. FFN memproses setiap posisi token secara independen — fungsinya adalah mentransformasi representasi hasil attention ke ruang yang lebih kaya secara non-linear. Peran kedua sub-layer ini berbeda: attention menangkap interaksi antar token, sementara FFN memproses representasi per-token.
Struktur lengkap encoder block adalah: Multi-Head Attention → Add & Norm → Feed-Forward → Add & Norm. Blok ini ditumpuk sebanyak N kali (biasanya 6 atau 12), yang memungkinkan model membangun representasi hierarkis secara bertahap.
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(F.relu(self.linear1(x)))
class EncoderBlock(nn.Module):
def __init__(self, d_model, h, d_ff, dropout=0.1):
super().__init__()
self.attention = MultiHeadAttention(d_model, h)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
attn_output, _ = self.attention(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x
# Contoh penggunaan encoder block
d_model, h, d_ff = 64, 8, 256
block = EncoderBlock(d_model, h, d_ff)
x = torch.randn(2, 4, d_model)
output = block(x)
print(f"Encoder block output shape: {output.shape}")
print(f"Sample output values:\n{output[0, 0, :8]}")Output:
Encoder block output shape: torch.Size([2, 4, 64])
Sample output values:
tensor([ 0.6553, 0.5239, 0.0766, -0.7535, 0.8251, 1.6547, -1.4267, -1.1746],
grad_fn=<SliceBackward0>)Dimensi output sama persis dengan input, yang memungkinkan encoder block ditumpuk secara sekuensial. Setiap blok tambahan memberikan kesempatan bagi model untuk menyempurnakan representasi berdasarkan konteks yang lebih luas.
Positional Encoding dan Hal-Hal Praktis Saat Training
Salah satu konsekuensi membuang recurrence adalah Transformer kehilangan informasi posisi token. Operasi self-attention bersifat permutation-invariant — menukar urutan dua token menghasilkan output yang sama persis. Untuk mengatasi ini, kita menambahkan positional encoding pada input embedding.
Sinusoidal positional encoding menggunakan fungsi sinus dan cosinus dengan frekuensi berbeda untuk setiap dimensi. Dimensi dengan frekuensi rendah menangkap pola jarak jauh, sementara frekuensi tinggi menangkap posisi relatif yang lebih pendek. Pendekatan ini memungkinkan model untuk belajar memanfaatkan informasi posisi tanpa menambah parameter yang bisa dipelajari. Ini seperti memberikan koordinat pada setiap kata — memungkinkan model membedakan "saya lihat dia" dan "dia lihat saya" meskipun kata-katanya sama.
Dalam praktik training, ada beberapa hal yang perlu diperhatikan. Padding mask diperlukan saat memproses batch dengan panjang sequence bervariasi — token padding harus diberi skor -inf agar tidak mempengaruhi attention. Untuk decoder, kita juga memerlukan look-ahead mask yang mencegah token melihat token di posisi setelahnya.
Learning rate scheduling dengan warmup adalah praktik standar untuk training Transformer. Pada awal training, learning rate dinaikkan secara linear dari nilai sangat kecil untuk menghindari gradien yang tidak stabil, lalu diturunkan secara bertahap. Dropout pada attention weights dan FFN membantu mencegah overfitting, terutama pada dataset yang lebih kecil.
Siap memperdalam pemahaman arsitektur transformer? Bootcamp Deep Learning Rumah Coding membahas BERT, GPT, dan fine-tuning untuk aplikasi nyata dengan bimbingan mentor industri.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.


