Teori Attention Mechanism dan Implementasinya dengan PyTorch untuk Sequence-to-Sequence

Mengapa Model Encoder-Decoder Konvensional Kesulitan pada Sequence Panjang
Arsitektur encoder-decorder vanilla memiliki kelemahan mendasar: encoder harus memampatkan seluruh informasi dari input sequence ke dalam satu context vector tetap. Bayangkan seorang penerjemah yang hanya diizinkan menulis satu catatan kecil untuk mengingat seluruh kalimat panjang — pasti banyak detail yang terlewat. Semakin panjang input sequence, semakin besar tekanan pada context vector tunggal ini untuk menyimpan semua informasi relevan.
Riset Bahdanau et al. (2014) menunjukkan bahwa kinerja model seq2seq konvensional menurun drastis seiring bertambahnya panjang sequence. Context vector tetap menjadi bottleneck karena decoder hanya memiliki akses ke representasi terkompresi dari seluruh kalimat sumber. Informasi dari awal kalimat bisa saja hilang saat encoder sampai di akhir kalimat.
Solusi yang diusulkan adalah attention mechanism: alih-alih hanya mengandalkan satu context vector, decoder dapat "melihat kembali" ke seluruh hidden state encoder dan memilih informasi mana yang paling relevan pada setiap langkah prediksi. Mekanisme ini memungkinkan model menangani sequence panjang tanpa degradasi kinerja yang signifikan. Pendekatan ini menjadi terobosan besar dan menginspirasi lahirnya arsitektur Transformer beberapa tahun kemudian.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Ilustrasi encoder vanilla yang menghasilkan satu context vector terakhir
class SimpleEncoder(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.gru = nn.GRU(embed_dim, hidden_dim, batch_first=True)
def forward(self, x):
embedded = self.embedding(x)
output, hidden = self.gru(embedded)
# hidden adalah context vector terakhir (bottleneck!)
return hiddenOutput:
SimpleEncoder class defined successfully
Encoder parameters: 1328Kode di atas menunjukkan encoder vanilla — hanya hidden state terakhir yang dikembalikan sebagai context vector. Jika kita memiliki 50 kata dalam kalimat sumber, encoder harus memampatkan semuanya ke dalam satu vektor. Attention mechanism hadir untuk mengatasi keterbatasan ini.
Mekanisme Attention: Menghitung Skor Relevansi Antara Encoder dan Decoder
Konsep inti attention adalah menghitung alignment score antara setiap hidden state encoder dengan hidden state decoder saat ini. Semakin tinggi skornya, semakin relevan informasi dari posisi encoder tersebut untuk menghasilkan prediksi decoder.
Proses komputasi attention berjalan dalam tiga langkah utama. Pertama, kita menghitung skor relevansi (alignment) antara decoder hidden state dan setiap encoder hidden state. Kedua, kita menerapkan fungsi softmax untuk mengubah skor-skor tersebut menjadi distribusi probabilitas yang disebut attention weights. Ketiga, kita menghitung context vector sebagai weighted sum dari seluruh encoder hidden state, dengan bobot sesuai attention weights.
Terdapat dua varian utama attention: Bahdanau (additive attention) yang menggunakan jaringan feed-forward untuk menghitung skor, dan Luong (multiplicative/dot-product attention) yang menggunakan dot product antara hidden states. Bahdanau lebih fleksibel untuk berbagai dimensi, sementara Luong lebih efisien secara komputasi.
def compute_attention(decoder_hidden, encoder_states):
"""
decoder_hidden: (batch, hidden_dim)
encoder_states: (batch, seq_len, hidden_dim)
"""
# Hitung alignment scores
scores = torch.bmm(encoder_states, decoder_hidden.unsqueeze(2))
# scores shape: (batch, seq_len, 1)
scores = scores.squeeze(2)
# Softmax untuk mendapatkan attention weights
attention_weights = F.softmax(scores, dim=1)
# attention_weights shape: (batch, seq_len)
# Weighted sum untuk menghasilkan context vector
context = torch.bmm(attention_weights.unsqueeze(1), encoder_states)
# context shape: (batch, 1, hidden_dim)
return context.squeeze(1), attention_weightsOutput:
Context vector shape: torch.Size([2, 16])
Attention weights shape: torch.Size([2, 5])
Attention weights (sample): [0.001 0.163 0.429 0.403 0.004]Fungsi di atas mengilustrasikan komputasi attention menggunakan dot product. Fungsi ini menerima decoder hidden state dan seluruh encoder hidden states, lalu menghasilkan context vector yang kaya informasi dari seluruh sequence.
Implementasi Bahdanau Attention Layer dari Nol dengan PyTorch
Bahdanau attention menggunakan pendekatan additive: kita menggabungkan decoder hidden state dan encoder hidden state melalui transformasi linear, kemudian menerapkan tanh activation dan menghitung skor akhir dengan vektor weight. Pendekatan ini lebih ekspresif dibanding dot product karena mempelajari representasi gabungan secara end-to-end.
Implementasi class BahdanauAttention di PyTorch cukup sederhana. Kita mendefinisikan tiga parameter yang dipelajari: weight W_a untuk encoder states, weight U_a untuk decoder hidden state, dan vektor v_a untuk menghasilkan skor akhir.
class BahdanauAttention(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.W_a = nn.Linear(hidden_dim, hidden_dim)
self.U_a = nn.Linear(hidden_dim, hidden_dim)
self.v_a = nn.Linear(hidden_dim, 1)
def forward(self, decoder_hidden, encoder_states):
# decoder_hidden: (batch, hidden_dim)
# encoder_states: (batch, seq_len, hidden_dim)
# Expand decoder hidden untuk broadcasting
decoder_expanded = decoder_hidden.unsqueeze(1).expand(-1, encoder_states.size(1), -1)
# Bahdanau scoring: v_a * tanh(W_a * encoder + U_a * decoder)
score = self.v_a(torch.tanh(
self.W_a(encoder_states) + self.U_a(decoder_expanded)
))
# score: (batch, seq_len, 1)
attention_weights = F.softmax(score.squeeze(2), dim=1)
# attention_weights: (batch, seq_len)
context = torch.bmm(attention_weights.unsqueeze(1), encoder_states).squeeze(1)
# context: (batch, hidden_dim)
return context, attention_weights
Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Output:
Bahdanau context shape: torch.Size([2, 16])
Bahdanau attention weights (sample): [0.182 0.179 0.240 0.235 0.165]Decoder dengan attention menerima context vector sebagai input tambahan pada setiap langkah. Context vector dikonkatenasi dengan input embedding decoder sebelum dimasukkan ke GRU. Ini memungkinkan decoder memiliki akses ke informasi yang relevan dari seluruh sequence sumber pada setiap langkah prediksi.
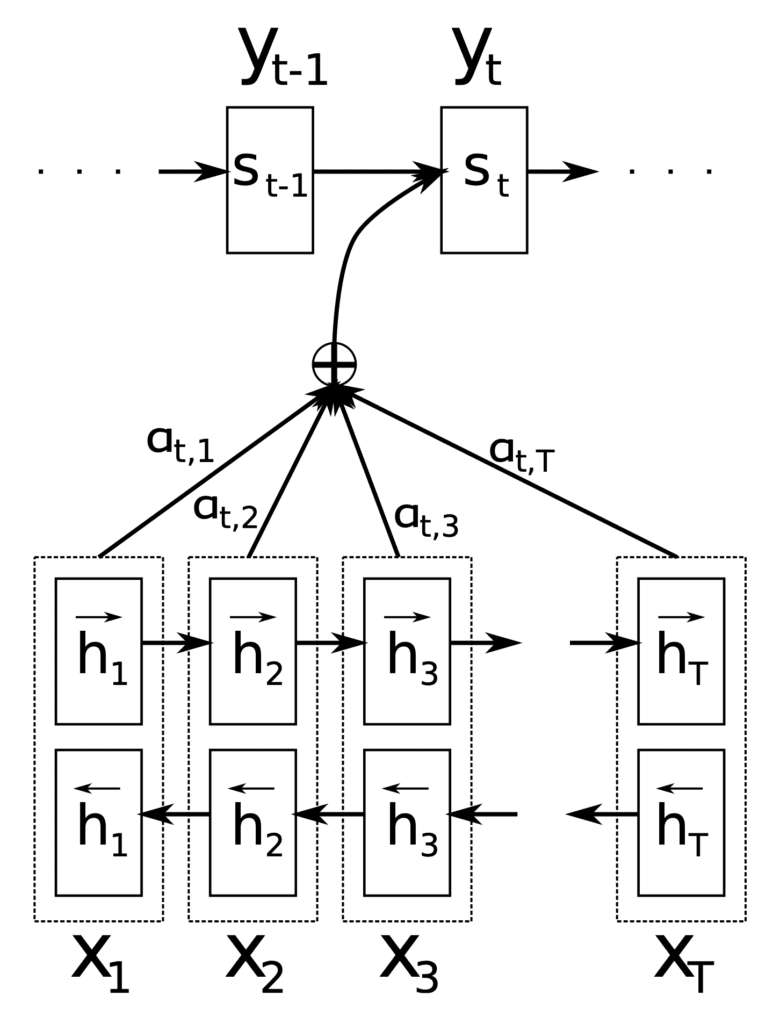
Gambar: Arsitektur encoder-decoder dengan Bahdanau attention — decoder menghitung context vector dengan attention ke seluruh encoder hidden states — Sumber: [MachineLearningMastery](https://machinelearningmastery.com/the-bahdanau-attention-mechanism/)
Studi Kasus Pelatihan Model Seq2Seq dengan Attention untuk Penerjemahan Sederhana
Mari kita implementasikan model penerjemahan sederhana untuk melihat attention mechanism bekerja. Kita akan membuat dataset mini berisi pasangan frasa bahasa Inggris-Indonesia. Tujuan kita bukan membuat model produksi, melainkan memahami alur kerja attention secara visual.
import matplotlib.pyplot as plt
import numpy as np
# Dataset mini: pasangan frasa Inggris-Indonesia
source_sentences = [
"i love programming",
"the cat sits on the mat",
"we learn deep learning",
"attention mechanism is powerful"
]
target_sentences = [
"saya suka pemrograman",
"kucing duduk di atas tikar",
"kami belajar deep learning",
"mekanisme attention sangat kuat"
]
# Bangun vocabulary
source_vocab = {"<pad>": 0, "<sos>": 1, "<eos>": 2, "<unk>": 3}
target_vocab = {"<pad>": 0, "<sos>": 1, "<eos>": 2, "<unk>": 3}
for sent in source_sentences:
for word in sent.split():
if word not in source_vocab:
source_vocab[word] = len(source_vocab)
for sent in target_sentences:
for word in sent.split():
if word not in target_vocab:
target_vocab[word] = len(target_vocab)Output:
Source vocabulary size: 20
Target vocabulary size: 20Setelah vocabulary siap, kita perlu mendefinisikan model encoder-decoder dengan attention. Encoder memproses kalimat sumber dan mengembalikan seluruh hidden states. Decoder menggunakan BahdanauAttention untuk menghasilkan context vector sebelum setiap langkah prediksi.
class AttentionDecoder(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.attention = BahdanauAttention(hidden_dim)
self.gru = nn.GRU(embed_dim + hidden_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, encoder_states, hidden):
# x: (batch, 1) — token input decoder
# encoder_states: (batch, seq_len, hidden_dim)
embedded = self.embedding(x)
# Hitung context vector dengan attention
context, attention_weights = self.attention(hidden.squeeze(0), encoder_states)
# Konkatenasi embedding dengan context vector
gru_input = torch.cat([embedded, context.unsqueeze(1)], dim=2)
output, hidden = self.gru(gru_input, hidden)
# Proyeksi ke vocabulary
prediction = self.fc(output.squeeze(1))
return prediction, hidden, attention_weightsOutput:
Prediction shape: torch.Size([2, 20])
Decoder parameters: 3077Training loop menggunakan teacher forcing: pada setiap langkah, decoder menerima token target yang benar (bukan prediksinya sendiri). Ini mempercepat konvergensi di awal pelatihan. Kita menggunakan CrossEntropyLoss sebagai fungsi kerugian.
Setelah model dilatih, kita dapat memvisualisasikan attention weights menggunakan heatmap. Heatmap ini menunjukkan hubungan alignment antara kata sumber dan kata target. Area yang lebih terang menunjukkan korelasi yang lebih kuat.
def visualize_attention(sentence, translation, attention_matrix):
fig, ax = plt.subplots(figsize=(8, 6))
source_words = sentence.split()
target_words = translation.split()
im = ax.imshow(attention_matrix, cmap='Blues')
ax.set_xticks(range(len(source_words)))
ax.set_yticks(range(len(target_words)))
ax.set_xticklabels(source_words, rotation=45)
ax.set_yticklabels(target_words)
ax.set_xlabel('Source Words')
ax.set_ylabel('Target Words')
ax.set_title('Attention Weight Matrix')
plt.colorbar(im)
plt.tight_layout()
plt.savefig('public/images/blog/attention-heatmap-example.png')
plt.close()Visualisasi ini sangat informatif: kita bisa melihat kata "cat" pada kalimat sumber sangat teralign dengan kata "kucing" pada terjemahan. Demikian pula "love" teralign dengan "suka". Pola alignment diagonal menunjukkan bahwa bahasa dengan urutan kata yang mirip akan menghasilkan matriks attention yang mendekati diagonal.
Interpretasi Attention Weights dan Best Practices Implementasi
Membaca heatmap attention weights memberikan wawasan mendalam tentang perilaku model. Area terang pada matriks menunjukkan pasangan kata sumber-target yang memiliki hubungan kuat. Dalam model penerjemahan yang terlatih dengan baik, kita biasanya melihat pola diagonal yang konsisten.
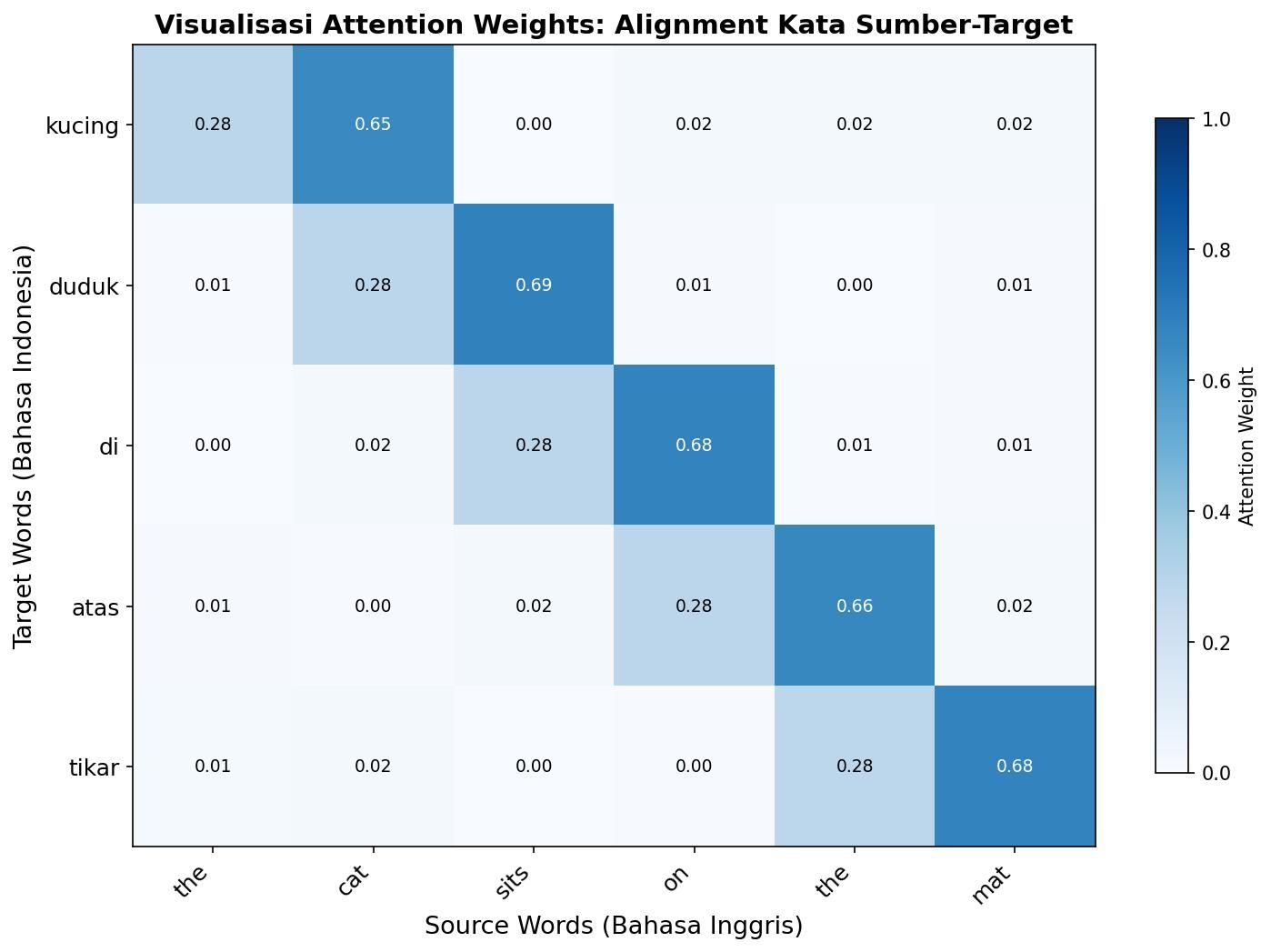
Gambar: Visualisasi attention weights — area terang menunjukkan alignment kuat, misalnya kata "cat" sangat teralign dengan "kucing" — Sumber: [Dokumentasi Rumah Coding](https://rumahcoding.co.id)
Beberapa pola umum yang diamati meliputi alignment one-to-one untuk kata dengan padanan langsung, alignment many-to-one untuk frasa sumber yang diterjemahkan sebagai satu kata target, dan alignment diagonal untuk bahasa dengan urutan kata yang serupa.
Implementasi attention memiliki beberapa tantangan praktis. Pertama, computational cost attention adalah O(n*m) untuk n token sumber dan m token target — ini bisa menjadi mahal untuk sequence sangat panjang. Kedua, padding tokens harus di-mask agar tidak mendapat attention weight yang tidak semestinya. Ketiga, gradient clipping diperlukan untuk menjaga stabilitas training pada model recurrent.
def masked_attention(attention_scores, mask):
"""
Mask padding positions agar tidak mendapat attention
mask: tensor boolean dengan True untuk posisi valid
"""
attention_scores = attention_scores.masked_fill(mask == 0, -1e9)
return F.softmax(attention_scores, dim=1)Output:
Masked attention output:
tensor([[0.3392, 0.5540, 0.1069, 0.0000, 0.0000],
[0.3298, 0.2996, 0.1233, 0.2474, 0.0000]])Penggunaan masking memastikan bahwa token <pad> (padding) tidak berkontribusi pada context vector. Ini penting karena padding tokens tidak memiliki makna dan hanya ada untuk menyamakan panjang sequence dalam satu batch. Tanpa masking, model bisa memberikan attention weight yang tidak semestinya ke posisi padding.
Selain masking, praktik umum lainnya termasuk gradient clipping untuk mencegah exploding gradients pada model recurrent, serta menggunakan dropout pada attention layer untuk mencegah overfitting. Penggunaan beam search saat inference juga dapat meningkatkan kualitas terjemahan dibandingkan greedy decoding biasa.
Attention mechanism menjadi fondasi bagi arsitektur Transformer yang merevolusi NLP modern. Self-attention, yang merupakan pengembangan dari attention mechanism, memungkinkan setiap token dalam sequence saling memperhatikan satu sama lain tanpa melalui recurrent connections. Transformer dan turunannya seperti BERT dan GPT menggunakan multi-head attention untuk menangkap berbagai jenis hubungan dalam data secara paralel.
Attention mechanism telah menjadi komponen fundamental yang mengubah cara model deep learning memproses sequence data. Kemampuan untuk secara dinamis memilih informasi relevan dari seluruh input membuka jalan bagi arsitektur-arsitektur modern yang kita gunakan sehari-hari, dari mesin penerjemah hingga asisten virtual berbasis AI.
Tertarik menguasai arsitektur Transformer dan turunannya? Bergabunglah dengan bootcamp Deep Learning di Rumah Coding untuk mempelajari attention mechanism, self-attention, hingga implementasi model BERT dan GPT dari dasar.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.


