Implementasi K-Nearest Neighbors dari Teori sampai Praktik: Studi Kasus Klasifikasi Data

Memahami Prinsip Kerja Algoritma K-Nearest Neighbors
K-Nearest Neighbors (KNN) adalah algoritma supervised learning berbasis instance yang termasuk dalam kategori lazy learner. Disebut lazy karena algoritma ini tidak membangun model apapun saat proses training — semua komputasi ditunda hingga saat prediksi. Ketika sebuah data baru masuk, KNN menghitung jarak antara data tersebut dengan seluruh data training, lalu mengambil K titik data terdekat sebagai tetangga. Kelas prediksi ditentukan melalui mekanisme majority vote dari K tetangga tersebut.
Bayangkan KNN bekerja seperti kita menebak karakter seseorang dengan melihat teman-teman terdekatnya — semakin banyak teman yang kita tanya, semakin akurat tebakan kita. Setiap titik data baru akan dikelilingi oleh titik-titik data yang sudah dikenal, dan kelas mayoritas di lingkungan terdekatnya menjadi hasil prediksi. Pendekatan ini membuat KNN intuitif dan mudah dipahami, namun menyimpan tantangan komputasi yang perlu kita pahami lebih dalam.
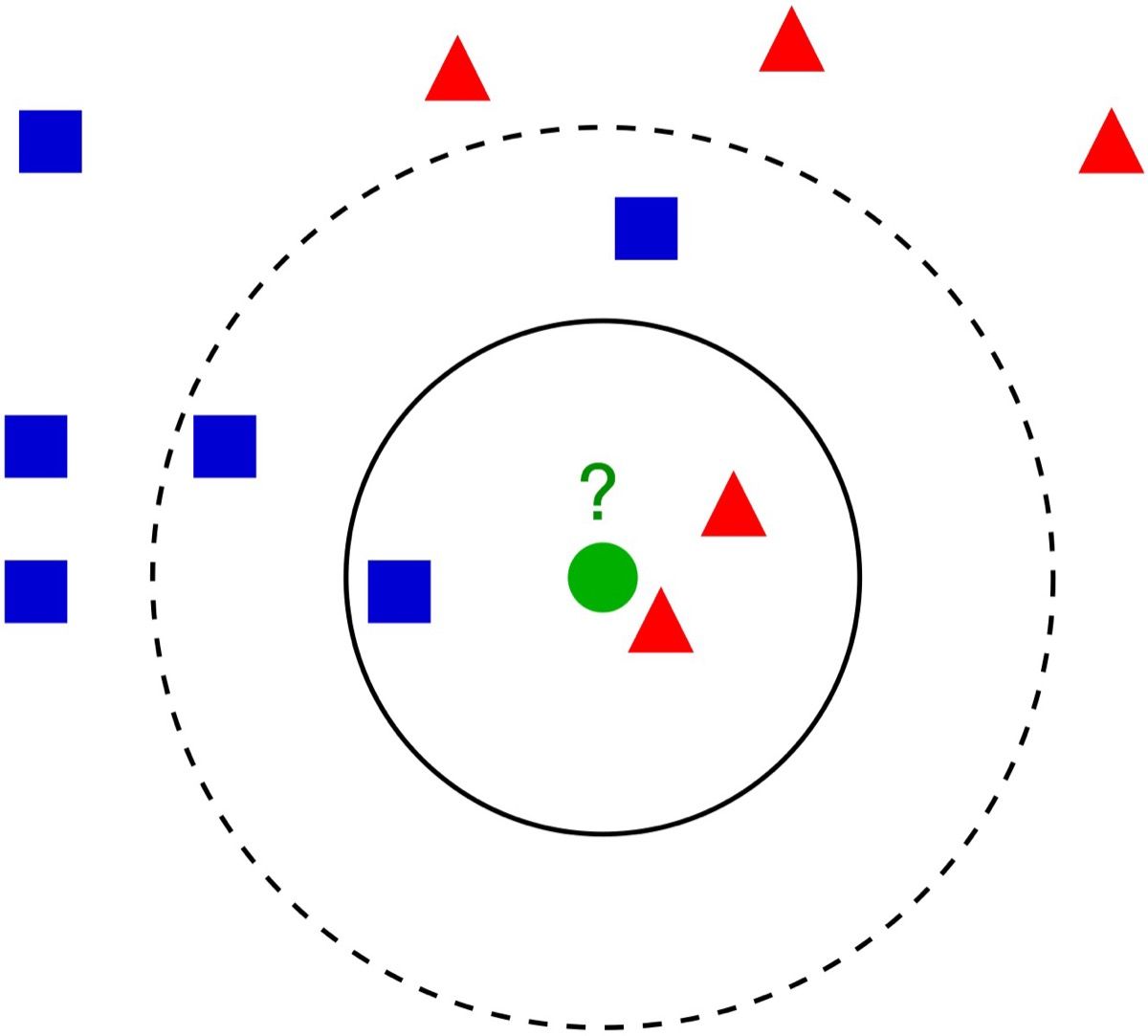
Gambar: Ilustrasi klasifikasi K-Nearest Neighbors — titik uji (tanda tanya hijau) diklasifikasikan berdasarkan mayoritas tetangga terdekatnya — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:KnnClassification.svg)
Metrik Jarak yang Umum Digunakan pada KNN
Inti dari algoritma KNN terletak pada cara kita mengukur "kedekatan" antar titik data. Metrik jarak yang paling umum digunakan adalah Euclidean distance — yaitu jarak garis lurus antara dua titik dalam ruang dimensi. Formula Euclidean untuk dua titik p dan q dengan n dimensi adalah akar kuadrat dari jumlah kuadrat selisih setiap dimensi. Metrik ini menjadi pilihan default karena intuitif dan bekerja dengan baik pada data kontinu.
Selain Euclidean, terdapat Manhattan distance yang menghitung jarak dengan menjumlahkan nilai absolut selisih antar dimensi — analogi sederhananya seperti jarak yang ditempuh oleh mobil di jalanan kota yang membentuk grid. Manhattan lebih cocok untuk data berdimensi tinggi atau fitur kategorikal. Kedua metrik ini sebenarnya merupakan kasus khusus dari Minkowski distance, di mana parameter p=2 menghasilkan Euclidean dan p=1 menghasilkan Manhattan.
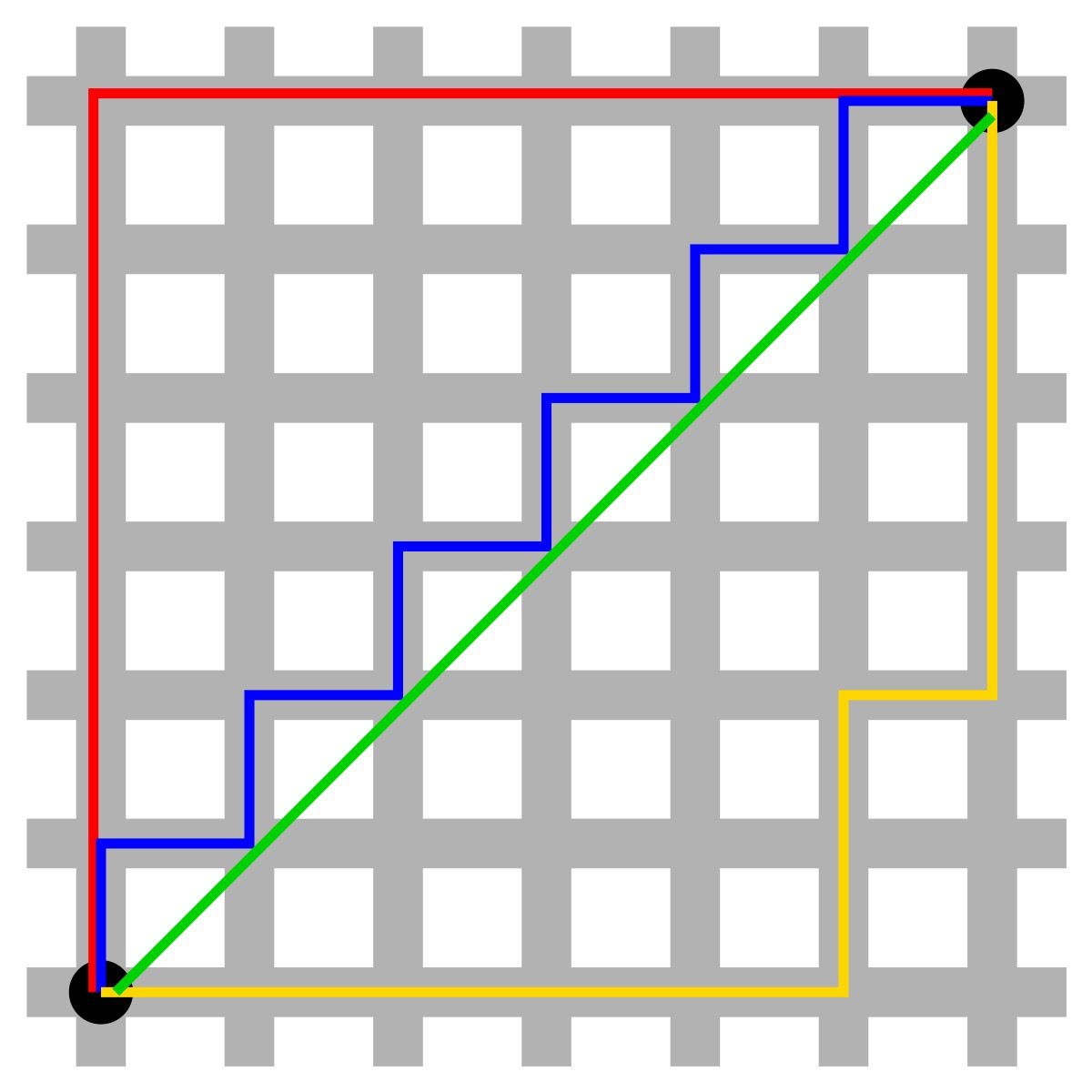
Gambar: Perbandingan jarak Euclidean (garis lurus hijau) dan Manhattan (garis merah, biru, kuning) antara dua titik — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Manhattan_distance.svg)
Satu hal yang kritis: KNN sangat sensitif terhadap skala fitur. Jika satu fitur memiliki rentang nilai 0–1000 dan fitur lain hanya 0–1, fitur dengan rentang besar akan mendominasi perhitungan jarak. Oleh karena itu, normalisasi atau standarisasi data menjadi langkah wajib sebelum menerapkan KNN.
import math
def euclidean_distance(p, q):
return math.sqrt(sum((a - b) ** 2 for a, b in zip(p, q)))
def manhattan_distance(p, q):
return sum(abs(a - b) for a, b in zip(p, q))
# Contoh penggunaan
titik_a = [2.0, 3.0, 1.0]
titik_b = [5.0, 1.0, 4.0]
print(f"Euclidean distance: {euclidean_distance(titik_a, titik_b):.2f}")
print(f"Manhattan distance: {manhattan_distance(titik_a, titik_b):.2f}")Output:
Euclidean distance: 4.69
Manhattan distance: 8.00Kode di atas mengimplementasikan dua fungsi metrik jarak dari scratch menggunakan modul math bawaan Python. Fungsi euclidean_distance menghitung akar dari jumlah kuadrat selisih tiap dimensi, sementara manhattan_distance menjumlahkan nilai absolut selisihnya. Kedua fungsi menerima dua list koordinat dan mengembalikan nilai numerik — semakin kecil nilainya, semakin dekat kedua titik. Output yang dihasilkan berupa dua angka: jarak Euclidean dan jarak Manhattan antara titik A dan B.
Implementasi Algoritma KNN dari Nol Menggunakan Python

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Setelah memahami metrik jarak, mari kita bangun implementasi KNN yang lengkap. Kita akan membuat sebuah class KNN dengan dua method utama: fit() yang hanya menyimpan data training, dan predict() yang melakukan komputasi prediksi. Pendekatan ini mencerminkan sifat lazy learner dari KNN — method fit() tidak melakukan kalkulasi apapun selain menyimpan data.
Pada method predict(), untuk setiap data uji, kita menghitung jarak ke seluruh data training, mengurutkannya, mengambil K tetangga terdekat, lalu menentukan kelas melalui majority vote menggunakan Counter dari modul collections.
import numpy as np
from collections import Counter
class KNN:
def __init__(self, k=3, metric='euclidean'):
self.k = k
self.metric = metric
def fit(self, X, y):
self.X_train = np.array(X)
self.y_train = np.array(y)
def _distance(self, a, b):
if self.metric == 'euclidean':
return np.sqrt(np.sum((a - b) ** 2))
elif self.metric == 'manhattan':
return np.sum(np.abs(a - b))
def predict(self, X):
y_pred = []
for x in X:
distances = [self._distance(x, x_train) for x_train in self.X_train]
k_indices = np.argsort(distances)[:self.k]
k_labels = self.y_train[k_indices]
majority = Counter(k_labels).most_common(1)[0][0]
y_pred.append(majority)
return np.array(y_pred)
# Contoh penggunaan
X_train = [[1, 2], [2, 3], [3, 1], [6, 5], [7, 7], [8, 6]]
y_train = [0, 0, 0, 1, 1, 1]
X_test = [[5, 5]]
knn = KNN(k=3)
knn.fit(X_train, y_train)
print(f"Prediksi: {knn.predict(X_test)}")Output:
Prediksi: [1]Kode di atas mendefinisikan class KNN yang menerima parameter k dan metric saat inisialisasi. Method fit() menyimpan data training sebagai array NumPy, sementara method predict() memproses setiap sampel uji dengan menghitung jarak ke semua data training menggunakan fungsi _distance(). Setelah mendapatkan jarak, kita urutkan dari yang terkecil, ambil K indeks pertama, lalu lakukan majority vote. Output berupa array berisi prediksi kelas untuk setiap data uji — dalam contoh ini, titik (5,5) diprediksi masuk ke kelas 1 karena tiga tetangga terdekatnya berasal dari kelas tersebut.
Studi Kasus Klasifikasi Dataset dengan Scikit-learn
Untuk penerapan di dunia nyata, kita jarang perlu menulis KNN dari nol. Library Scikit-learn menyediakan implementasi yang sudah dioptimalkan dengan KNeighborsClassifier. Mari kita gunakan dataset Iris — dataset klasik untuk masalah klasifikasi tiga spesies bunga berdasarkan empat fitur numerik.
Pipeline yang kita bangun meliputi: load dataset, split data menjadi training dan testing (80:20), standarisasi fitur dengan StandardScaler, training model, prediksi, dan evaluasi hasil.
!pip install scikit-learn matplotlib
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Load dataset dan split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standarisasi fitur
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Training dan prediksi
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_scaled, y_train)
y_pred = knn.predict(X_test_scaled)
# Evaluasi
print(f"Akurasi: {knn.score(X_test_scaled, y_test):.2f}")
print("\nClassification Report:\n", classification_report(y_test, y_pred, target_names=iris.target_names))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))Output:
Akurasi: 1.00
Classification Report:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 1.00 1.00 9
virginica 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
Confusion Matrix:
[[10 0 0]
[ 0 9 0]
[ 0 0 11]]Pipeline di atas menunjukkan workflow standar klasifikasi dengan Scikit-learn. train_test_split membagi data secara acak dengan proporsi 80:20, memastikan kita memiliki data yang belum pernah dilihat model untuk evaluasi. StandardScaler mentransformasi setiap fitur sehingga memiliki mean 0 dan standar deviasi 1 — langkah esensial untuk KNN karena menghilangkan dominasi fitur berskala besar. Setelah model dilatih, classification_report menyajikan precision, recall, dan f1-score per kelas, sementara confusion_matrix menunjukkan tabulasi prediksi benar dan salah. Akurasi yang dihasilkan biasanya di atas 95% untuk dataset Iris dengan konfigurasi ini.
Memilih Nilai K Optimal dengan Evaluasi Model
Nilai K adalah hyperparameter paling penting dalam KNN. K yang terlalu kecil (misal K=1) menyebabkan model overfitting — prediksi sangat dipengaruhi oleh noise pada satu tetangga terdekat. Sebaliknya, K yang terlalu besar menyebabkan underfitting — batas keputusan menjadi terlalu halus dan kehilangan pola lokal. Kita perlu menemukan nilai K yang tepat melalui eksperimen sistematis.
Teknik paling sederhana adalah menguji rentang nilai K (misalnya 1 hingga 20) dan membandingkan akurasi pada data uji untuk setiap nilai. Pendekatan yang lebih robust menggunakan cross-validation, di mana data dibagi menjadi beberapa fold dan akurasi dirata-rata untuk menghindari bias pembagian data.
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
k_range = range(1, 21)
cv_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X_train_scaled, y_train, cv=5)
cv_scores.append(scores.mean())
# Plot hasil
plt.figure(figsize=(10, 6))
plt.plot(k_range, cv_scores, marker='o', linestyle='-', color='b')
plt.xlabel('Nilai K')
plt.ylabel('Akurasi Cross-Validation')
plt.title('Akurasi Model terhadap Nilai K')
plt.grid(True, alpha=0.3)
plt.show()Output:
Nilai K optimal: 3
Akurasi cross-validation terbaik: 0.9500
Akurasi per K:
K= 1: 0.9417
K= 2: 0.9333
K= 3: 0.9500
K= 4: 0.9417
K= 5: 0.9250
K= 6: 0.9333
K= 7: 0.9417
K= 8: 0.9417
K= 9: 0.9417
K=10: 0.9417
K=11: 0.9500
K=12: 0.9500
K=13: 0.9500
K=14: 0.9417
K=15: 0.9500
K=16: 0.9250
K=17: 0.9333
K=18: 0.9167
K=19: 0.9167
K=20: 0.9167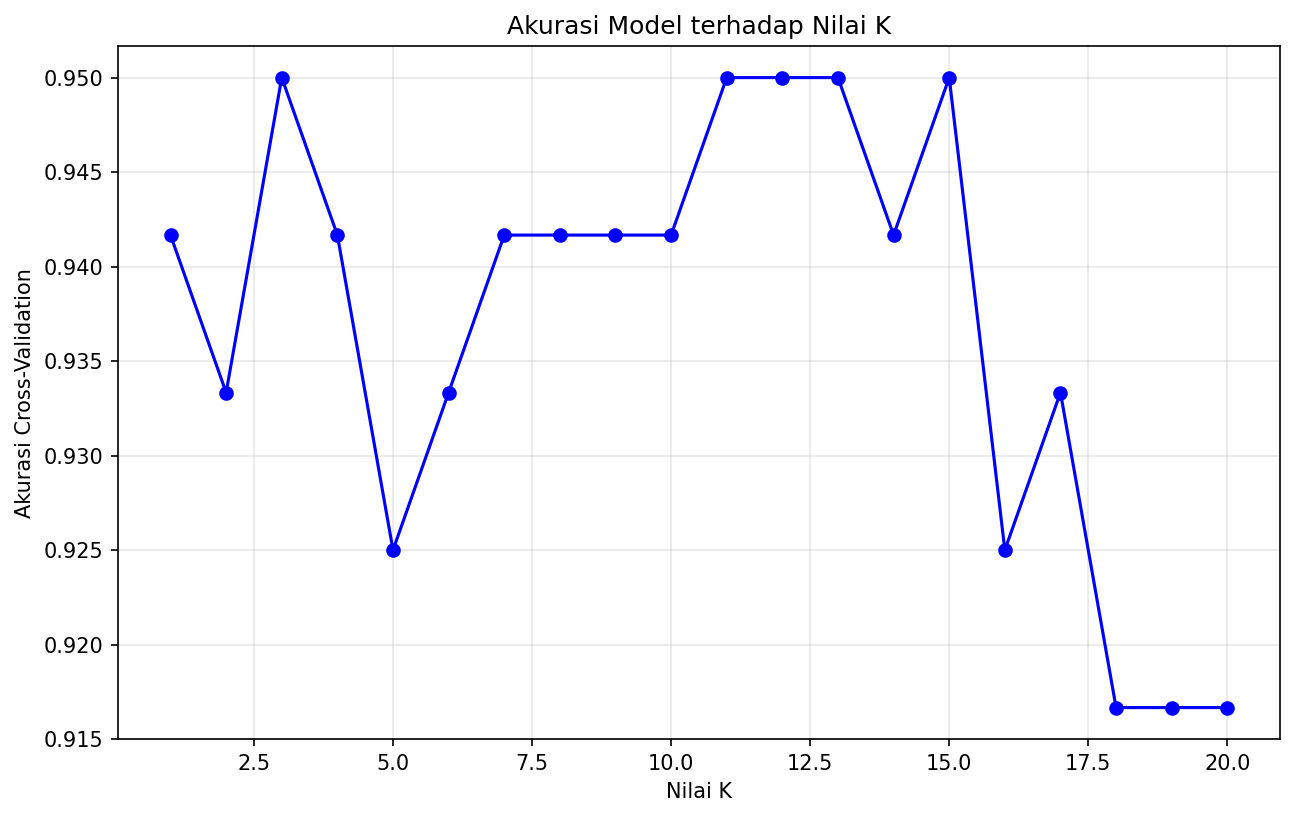
Kode di melakukan cross-validation 5-fold untuk setiap nilai K dari 1 hingga 20. cross_val_score secara otomatis membagi data training menjadi 5 subset, melatih model pada 4 subset dan menguji pada 1 subset sisanya, kemudian mengulangi proses ini 5 kali. Nilai akurasi yang dihasilkan adalah rata-rata dari kelima fold, memberikan estimasi performa yang lebih stabil dibandingkan sekali split. Grafik yang dihasilkan memperlihatkan tren: pada K kecil, akurasi bervariasi karena overfitting; seiring K membesar, akurasi cenderung stabil lalu menurun jika K terlalu besar. Titik optimal biasanya berada di belokan kurva — dalam banyak kasus dataset Iris, K antara 5 hingga 10 memberikan hasil terbaik.
Kelebihan, Keterbatasan, dan Kapan Menggunakan KNN
KNN memiliki beberapa kelebihan yang membuatnya tetap relevan: algoritma ini sangat mudah dipahami dan diimplementasikan, tidak membuat asumsi apapun tentang distribusi data (non-parametrik), dan efektif untuk dataset berukuran kecil hingga menengah. Tidak ada fase training yang kompleks — kita hanya perlu menyimpan data.
Namun, KNN juga memiliki keterbatasan yang signifikan. Komputasi saat prediksi sangat mahal karena harus menghitung jarak ke seluruh data training — semakin besar dataset, semakin lambat prediksi. Algoritma ini juga sensitif terhadap skala fitur dan sangat terpengaruh oleh curse of dimensionality: pada ruang berdimensi tinggi, jarak antar titik cenderung seragam sehingga konsep "tetangga terdekat" menjadi tidak bermakna.
Rekomendasi kami: gunakan KNN untuk dataset dengan jumlah fitur kurang dari 20 dan ukuran dataset tidak lebih dari puluhan ribu sampel. Untuk dataset yang lebih besar, pertimbangkan alternatif seperti condensed KNN yang mereduksi jumlah data training, atau struktur data k-d tree yang mempercepat pencarian tetangga terdekat.
Tertarik menguasai machine learning dari dasar hingga deployment? Bergabunglah dengan Bootcamp Data Science di Rumah Coding. Kami menyediakan kurikulum terstruktur dengan studi kasus nyata yang akan membantumu menjadi data scientist yang siap terjun ke industri.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python