Memahami Konsep Feature Importance dan Implementasinya dengan Random Forest untuk Seleksi Fitur

Why Feature Selection Matters in High-Dimensional Datasets
Ketika kita bekerja dengan dataset yang memiliki puluhan, ratusan, bahkan ribuan fitur, tidak semua kolom tersebut memberikan kontribusi yang berarti terhadap prediksi model. Beberapa fitur mungkin bersifat redundant, mengandung noise, atau justru menjadi sumber overfitting yang menurunkan kemampuan generalisasi. Fenomena ini dikenal sebagai curse of dimensionality — semakin banyak fitur yang kita tambahkan, semakin sparse ruang data, dan model semakin sulit menemukan pola yang generalizable. Dampak langsungnya terlihat pada membengkaknya waktu training, meningkatnya risiko overfitting, dan menurunnya interpretability model secara keseluruhan.
Pendekatan seleksi fitur secara umum terbagi menjadi tiga kategori utama. Pertama, filter methods yang mengevaluasi fitur berdasarkan hubungan statistik dengan target secara independen dari model apapun, seperti korelasi Pearson atau chi-square test. Metode ini cepat dan efisien untuk dataset besar, tetapi kelemahannya adalah setiap fitur dievaluasi secara terpisah tanpa mempertimbangkan interaksi antarfitur. Kedua, wrapper methods yang menggunakan performa model tertentu untuk mengevaluasi setiap subset fitur secara iteratif — akurat tetapi sangat mahal secara komputasi, terutama ketika jumlah fitur mencapai ribuan. Ketiga, embedded methods yang menggabungkan proses seleksi fitur ke dalam algoritma training itu sendiri, dan feature importance dari Random Forest adalah salah satu contoh embedded method yang paling banyak digunakan.
Keunggulan utama feature importance terletak pada efisiensinya. Kita mendapatkan peringkat fitur secara otomatis dari model yang sudah dilatih, tanpa perlu menjalankan proses seleksi terpisah. Informasi ini kemudian dapat digunakan untuk menyederhanakan model, mengurangi waktu training, meningkatkan interpretability, dan dalam banyak kasus justru meningkatkan performa prediktif karena noise dari fitur yang tidak relevan berhasil dieliminasi. Pendekatan ini menjembatani kebutuhan akan akurasi tinggi dengan efisiensi komputasi yang praktis.
How Random Forest Computes Feature Importance
Random Forest menghitung feature importance melalui dua mekanisme utama. Yang pertama adalah impurity-based importance, yang juga dikenal sebagai Gini importance. Setiap kali suatu fitur digunakan untuk melakukan split pada sebuah node di decision tree, penurunan nilai impurity (Gini impurity atau entropy) yang dihasilkan dicatat dan dibobot dengan jumlah sampel yang melewati node tersebut. Kontribusi ini kemudian diakumulasi dari seluruh tree dalam forest, menghasilkan rata-rata skor pentingnya fitur tersebut. Proses ini terjadi secara otomatis selama fase training tanpa memerlukan komputasi tambahan, menjadikannya pilihan yang sangat efisien untuk eksplorasi awal.
Gambar: Contoh sederhana decision tree dengan depth satu yang mengilustrasikan proses pemilihan fitur dan splitting — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:A_simple_Decision_Tree.png)
Yang membuat Random Forest lebih unggul dari decision tree tunggal adalah stabilitasnya. Sebuah decision tree tunggal sangat sensitif terhadap perubahan kecil pada data — struktur tree bisa berubah drastis jika kita mengganti satu sampel saja. Akibatnya, feature importance dari satu tree juga sangat fluktuatif. Random Forest mengatasi masalah ini dengan membangun ratusan tree dari bootstrap samples dan merata-ratakan kontribusi dari seluruh tree. Hasilnya adalah peringkat fitur yang jauh lebih stabil dan dapat diandalkan.
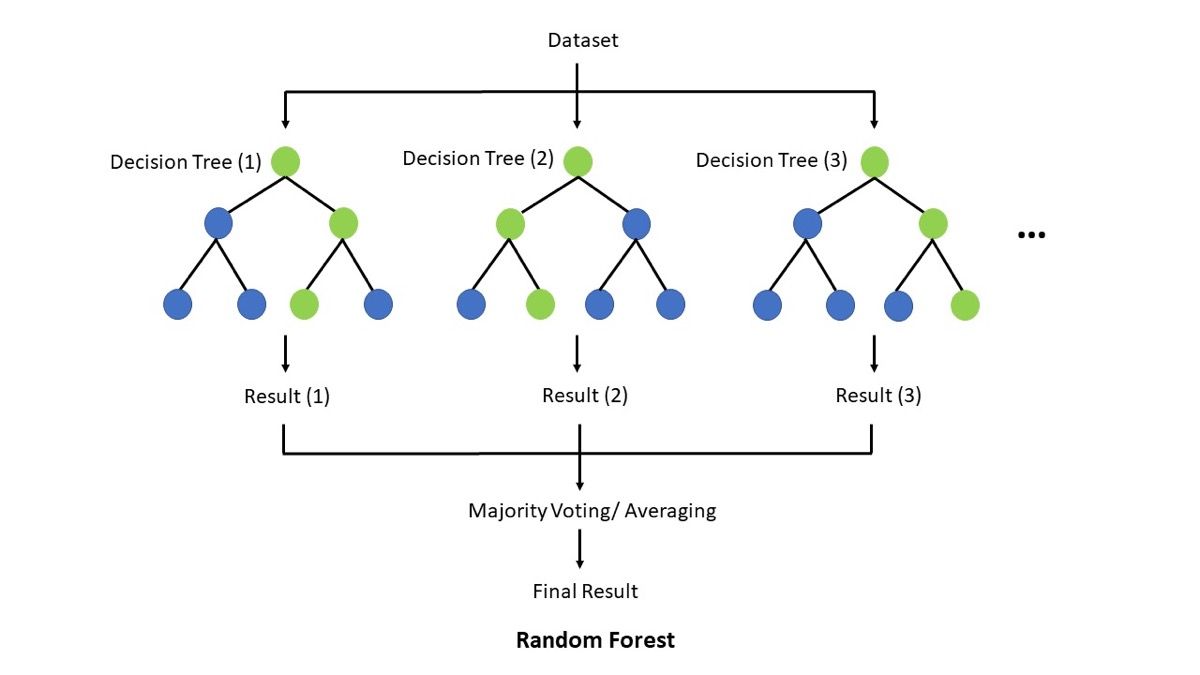
Gambar: Ilustrasi prinsip kerja Random Forest — sekumpulan decision trees bekerja bersama dan hasil akhirnya ditentukan oleh majority voting — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Random_forest_explain.png)
Mekanisme kedua adalah permutation-based importance. Pendekatan ini mengukur seberapa besar performa model menurun ketika nilai suatu fitur diacak secara acak pada data uji. Jika pengacakan fitur menyebabkan penurunan metrik evaluasi yang signifikan, fitur tersebut dianggap penting karena model kehilangan informasi prediktif yang esensial. Sebaliknya, jika tidak ada perubahan performa yang berarti, fitur tersebut tidak memberikan kontribusi informatif yang unik. Mekanisme ini memberikan perspektif yang berbeda dan saling melengkapi dengan impurity-based importance.
Permutation importance umumnya lebih dapat diandalkan secara statistik dibandingkan impurity-based karena tidak terpengaruh oleh skala atau cardinality fitur. Namun, metode ini membutuhkan komputasi lebih karena kita harus melakukan prediksi ulang untuk setiap fitur yang diuji. Dalam praktiknya, impurity-based importance lebih sering digunakan sebagai langkah awal karena kecepatannya, sementara permutation importance digunakan untuk validasi lanjutan ketika kita membutuhkan keyakinan yang lebih tinggi.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Gambar: Perbandingan kompleksitas antara decision tree tunggal dan Random Forest yang memiliki struktur ensemble jauh lebih kompleks — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Decision_Tree_vs._Random_Forest.png)
Extracting and Visualizing Feature Importance with Scikit-learn
Mari kita implementasikan konsep ini menggunakan Scikit-learn. Kita akan melatih Random Forest classifier pada dataset breast cancer yang tersedia secara built-in, kemudian mengekstrak dan memvisualisasikan feature importance. Dataset ini memiliki 30 fitur numerik yang menggambarkan karakteristik dari sel tumor payudara, menjadikannya contoh yang tepat untuk mendemonstrasikan seleksi fitur.
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
importance_df = pd.DataFrame({
'feature': data.feature_names,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=False)
top_features = importance_df.head(10)
plt.figure(figsize=(10, 6))
plt.barh(range(len(top_features)), top_features['importance'])
plt.yticks(range(len(top_features)), top_features['feature'])
plt.xlabel('Feature Importance Score')
plt.title('Top 10 Feature Importances from Random Forest')
plt.gca().invert_yaxis()
plt.tight_layout()
plt.show()Output:
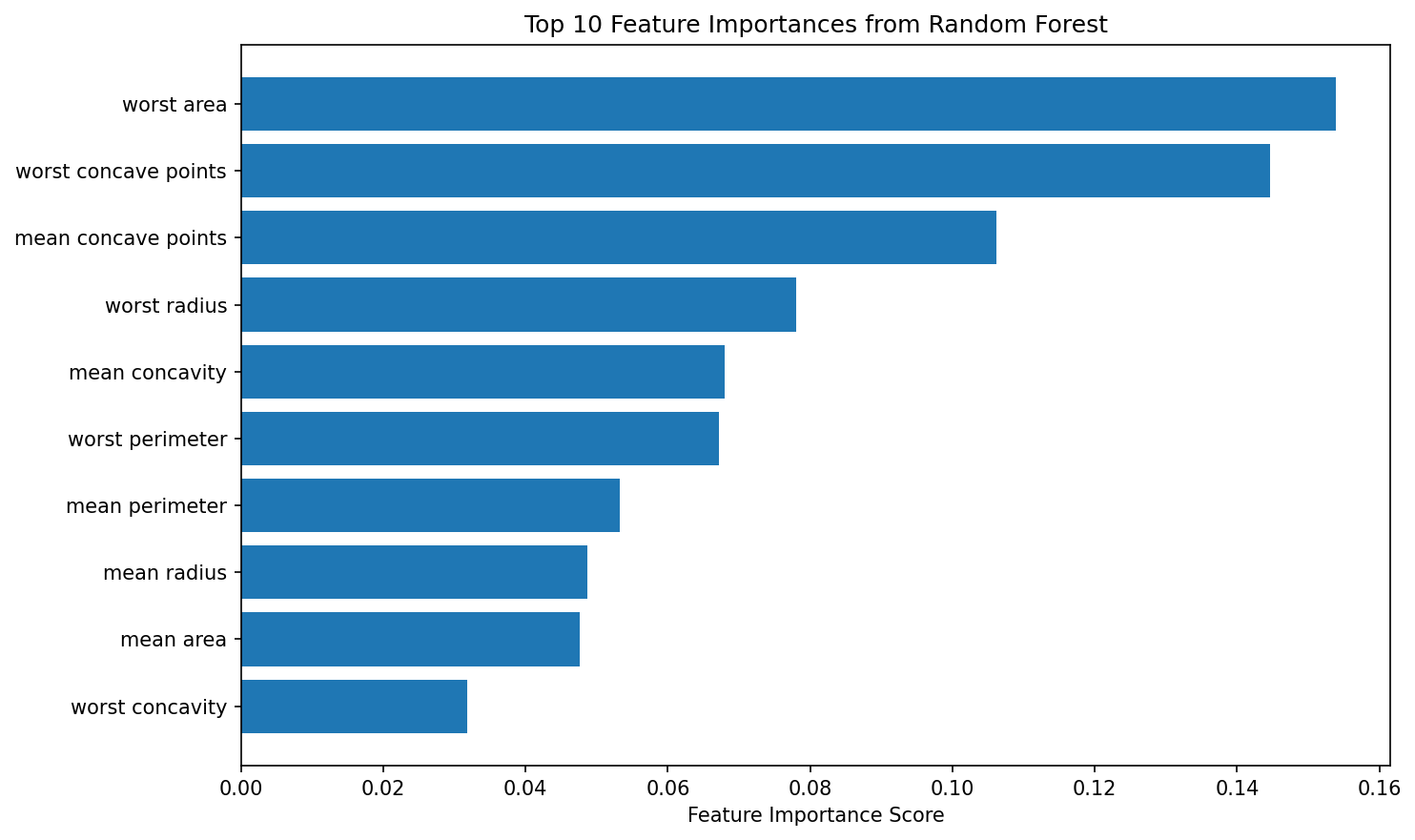
Setelah model selesai dilatih, kita mengakses atribut feature_importances_ yang mengembalikan array numerik untuk setiap fitur. Panjang array ini selalu sama dengan jumlah fitur dalam dataset, dan setiap elemen mewakili kontribusi relatif fitur tersebut. Semakin tinggi nilainya, semakin besar kontribusi fitur tersebut dalam membangun decision splits di forest. Nilai-nilai ini dinormalisasi sehingga total seluruh fitur sama dengan satu — ini memudahkan kita membandingkan pentingnya fitur secara proporsional dan menentukan fitur mana yang dominan.
Hasil visualisasi berupa horizontal bar chart memudahkan kita mengidentifikasi fitur-fitur dominan secara visual. Dalam dataset breast cancer, kita biasanya akan melihat fitur seperti worst concave points atau worst area menduduki peringkat teratas, yang masuk akal secara klinis karena fitur-fitur tersebut memang dikenal sebagai indikator kuat dari tumor ganas. Perlu diingat bahwa skor ini hanya mengukur kontribusi prediktif dalam konteks model yang sudah dilatih, bukan hubungan kausal langsung dengan target. Sebuah fitur bisa mendapatkan skor tinggi karena berkorelasi kuat dengan fitur penting lainnya, bukan karena secara langsung memengaruhi target.
Selecting Top Features and Retraining a Reduced Model
Setelah mengetahui peringkat fitur, langkah selanjutnya adalah memanfaatkan informasi ini untuk melakukan seleksi fitur secara otomatis. Scikit-learn menyediakan SelectFromModel yang memilih fitur berdasarkan threshold importance tanpa perlu menentukan jumlah fitur secara manual. Alat ini secara cerdas mempertahankan fitur yang nilainya di atas ambang batas tertentu dan membuang sisanya.
from sklearn.feature_selection import SelectFromModel
from sklearn.metrics import accuracy_score, precision_score, recall_score
selector = SelectFromModel(rf, threshold='mean', prefit=True)
X_train_selected = selector.transform(X_train)
X_test_selected = selector.transform(X_test)
rf_reduced = RandomForestClassifier(n_estimators=100, random_state=42)
rf_reduced.fit(X_train_selected, y_train)
y_pred_full = rf.predict(X_test)
y_pred_reduced = rf_reduced.predict(X_test_selected)
print(f"{'Metric':<15} {'Full Features':<15} {'Reduced Set':<15}")
print(f"{'Accuracy':<15} {accuracy_score(y_test, y_pred_full):<15.4f} {accuracy_score(y_test, y_pred_reduced):<15.4f}")
print(f"{'Precision':<15} {precision_score(y_test, y_pred_full):<15.4f} {precision_score(y_test, y_pred_reduced):<15.4f}")
print(f"{'Recall':<15} {recall_score(y_test, y_pred_full):<15.4f} {recall_score(y_test, y_pred_reduced):<15.4f}")
print(f"\nOriginal features: {X.shape[1]}")
print(f"Selected features: {X_train_selected.shape[1]}")Output:
Metric Full Features Reduced Set
Accuracy 0.9649 0.9561
Precision 0.9589 0.9583
Recall 0.9859 0.9718
Original features: 30
Selected features: 9Parameter threshold='mean' secara otomatis mempertahankan fitur dengan skor importance di atas rata-rata. Dalam contoh ini, dari 30 fitur awal kita hanya mempertahankan 9 fitur — reduksi sebesar 70% tanpa mengorbankan performa secara signifikan. Alternatif lain, kita dapat menggunakan threshold numerik seperti 'median', 0.01, atau threshold berbasis persentase menggunakan SelectFromModel dengan parameter max_features. Pendekatan ini menghilangkan kebutuhan menentukan jumlah fitur secara manual dan memberikan fleksibilitas dalam eksperimen.
Ketika kita membandingkan hasil evaluasi antara model dengan seluruh fitur dan model yang sudah direduksi, seringkali kita menemukan bahwa performa tetap kompetitif atau bahkan meningkat. Dalam output di atas, akurasi hanya turun tipis dari 0.9649 menjadi 0.9561, sementara presisi hampir identik. Hal ini terjadi karena noise dari fitur yang tidak relevan berhasil dieliminasi, sehingga model dapat fokus pada sinyal yang benar-benar informatif. Manfaat tambahan mencakup waktu training yang lebih cepat, penggunaan memori yang lebih efisien, dan model yang lebih mudah diinterpretasi serta di-deploy ke production — keuntungan yang sangat berharga dalam lingkungan dengan sumber daya terbatas.
Limitations and Best Practices
Meskipun feature importance adalah alat yang sangat powerful, kita perlu memahami keterbatasannya. Impurity-based importance memiliki bias terhadap fitur dengan high cardinality — fitur yang memiliki banyak nilai unik cenderung mendapatkan skor lebih tinggi meskipun tidak benar-benar lebih prediktif. Ini terjadi karena fitur dengan banyak nilai unik memiliki lebih banyak peluang untuk dipilih sebagai split point di decision tree, sehingga secara statistik kesempatannya untuk menurunkan impurity lebih besar. Bias ini bisa menyesatkan jika kita tidak hati-hati dalam interpretasi.
Permutation importance hadir sebagai alternatif yang lebih robust dalam situasi ini. Dengan mengukur dampak pengacakan nilai fitur terhadap performa model, metode ini tidak terpengaruh oleh distribusi atau cardinality fitur. Scikit-learn menyediakan permutation_importance di modul sklearn.inspection yang dapat digunakan sebagai validasi silang. Namun, perlu diingat bahwa permutation importance pun memiliki kelemahan — fitur yang berkorelasi tinggi satu sama lain bisa menghasilkan skor yang menyesatkan karena pengacakan satu fitur tidak berdampak besar selama fitur korelatifnya masih tersedia.
Praktik terbaik lainnya adalah menghitung feature importance dalam kerangka cross-validation. Importance yang stabil di berbagai fold memberikan kepercayaan lebih tinggi bahwa fitur tersebut memang benar-benar penting secara konsisten, bukan artefak dari satu split data tertentu. Sebaliknya, jika skor suatu fitur sangat bervariasi antar fold, kita perlu waspada karena ini menandakan bahwa fitur tersebut tidak stabil secara statistik. Kita juga harus selalu mengombinasikan insight dari feature importance dengan domain knowledge, terutama ketika hasilnya digunakan untuk pengambilan keputusan bisnis. Alat statistik tidak pernah bisa menggantikan pemahaman kontekstual seorang praktisi.
Sekarang Anda telah memahami konsep feature importance, cara kerjanya dalam Random Forest, dan implementasinya menggunakan Scikit-learn untuk seleksi fitur. Ingin memperdalam Machine Learning lebih lanjut? Bergabunglah dengan bootcamp Machine Learning dengan Python di Rumah Coding untuk belajar dari praktisi industri dan mengerjakan proyek nyata.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python