Memahami Konsep Korelasi dan Regresi Linear: Implementasi dengan Statsmodels untuk Analisis Hubungan Variabel

Dalam analisis data, memahami hubungan antar variabel adalah langkah fundamental sebelum membangun model prediktif. Dua teknik yang paling sering digunakan adalah korelasi untuk mengukur kekuatan hubungan, dan regresi linear untuk memodelkan hubungan tersebut secara matematis. Kali ini kita akan membahas kedua konsep tersebut secara mendalam dengan implementasi menggunakan library Statsmodels di Python.
Mengukur Hubungan Antar Variabel dengan Koefisien Korelasi
Sebelum membangun model regresi, kita perlu tahu apakah variabel-variabel yang kita miliki benar-benar saling berhubungan. Koefisien korelasi adalah metrik yang mengukur seberapa kuat hubungan linear antara dua variabel.
Terdapat dua jenis koefisien korelasi yang umum digunakan. Pearson correlation mengasumsikan hubungan linear antara dua variabel yang berdistribusi normal, sementara Spearman correlation bekerja dengan hubungan monotonik dan tidak memerlukan asumsi distribusi. Nilai koefisien korelasi berkisar antara -1 hingga +1, di mana nilai mendekati +1 menandakan hubungan positif yang kuat, nilai mendekati -1 menandakan hubungan negatif yang kuat, dan nilai mendekati 0 menandakan tidak ada hubungan linear.
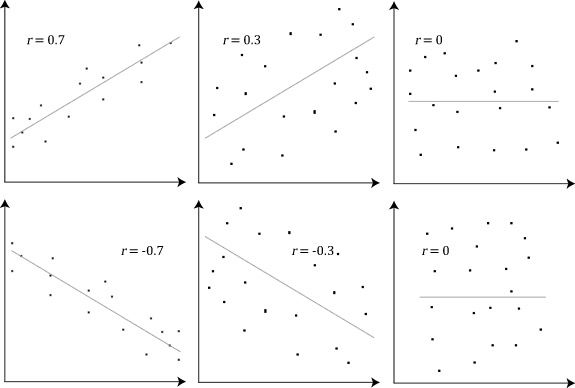
Gambar: Contoh scatter plot untuk berbagai nilai koefisien korelasi (ρ) — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Pearson_Correlation_Coefficient_and_associated_scatterplots.png)
Matriks korelasi menjadi alat ringkas untuk melihat hubungan antar banyak variabel sekaligus dalam satu tabel. Dengan pandas, kita bisa menghitung matriks ini hanya dengan satu metode .corr(). Namun penting untuk diingat: korelasi tidak sama dengan kausalitas. Dua variabel yang berkorelasi tinggi belum tentu memiliki hubungan sebab-akibat, karena bisa ada variabel ketiga yang memengaruhi keduanya.
!pip install pandas seaborn statsmodels matplotlib scipy
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Load dataset tips dari seaborn
tips = sns.load_dataset('tips')
# Pilih kolom numerik untuk analisis korelasi
numeric_cols = ['total_bill', 'tip', 'size']
corr_matrix = tips[numeric_cols].corr()
# Visualisasi heatmap matriks korelasi
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0,
fmt='.2f', linewidths=0.5)
plt.title('Matriks Korelasi Dataset Tips', fontsize=14)
plt.show()Output:
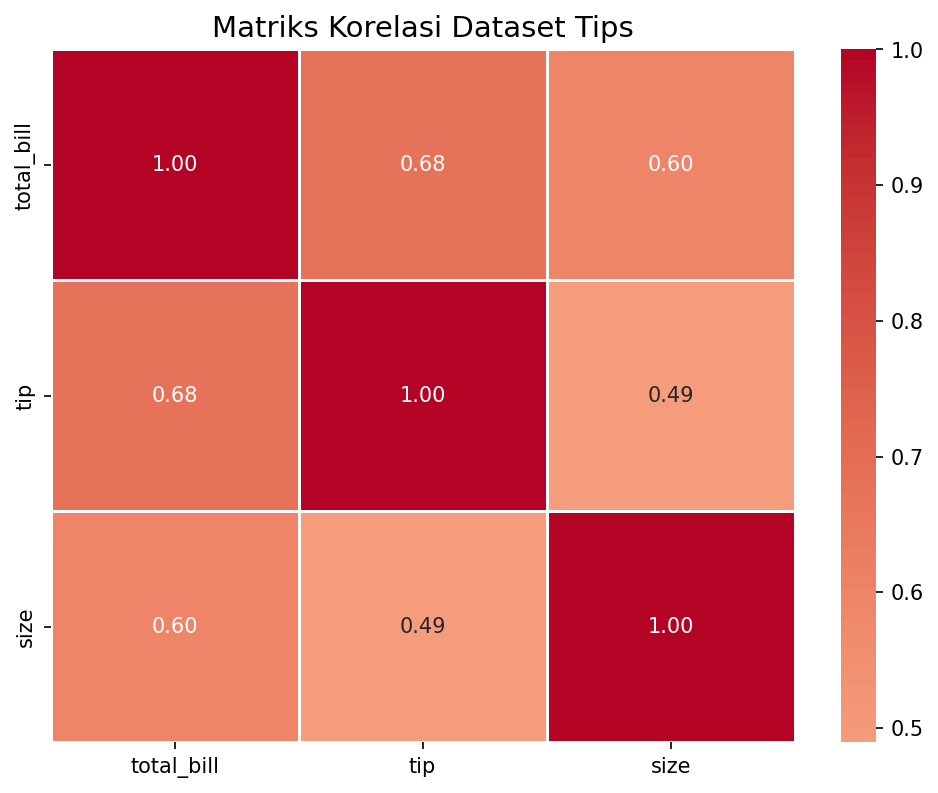
Dari heatmap yang dihasilkan, kita bisa langsung melihat bahwa total_bill dan tip memiliki korelasi positif yang cukup tinggi, sementara size menunjukkan korelasi yang lebih lemah terhadap kedua variabel lainnya.
Regresi Linear Sederhana dengan Ordinary Least Squares
Setelah mengetahui bahwa dua variabel memiliki hubungan linear, langkah selanjutnya adalah memodelkan hubungan tersebut secara kuantitatif menggunakan regresi linear. Regresi linear sederhana melibatkan satu variabel independen (X) dan satu variabel dependen (Y) dengan persamaan:
Y = β₀ + β₁X + ε
Di sini, β₀ adalah intercept (nilai Y saat X = 0), β₁ adalah slope (perubahan Y untuk setiap perubahan satu unit X), dan ε adalah error term. Metode Ordinary Least Squares (OLS) bekerja dengan mencari garis regresi yang meminimalkan jumlah kuadrat residual — yaitu selisih antara nilai aktual dan nilai prediksi.
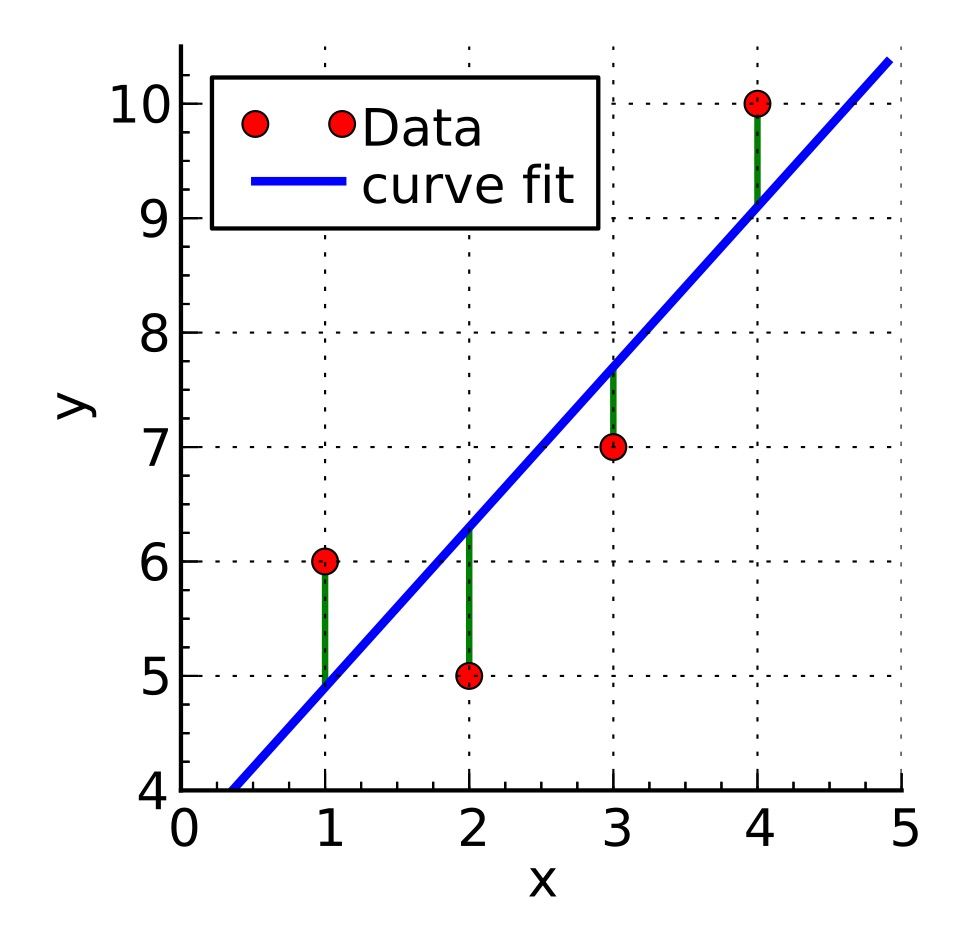
Gambar: Ilustrasi Ordinary Least Squares — garis biru adalah garis regresi terbaik, garis vertikal hijau menunjukkan residual yang diminimalkan jumlah kuadratnya — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Linear_least_squares_example2.svg)
Interpretasi koefisien sangat penting dalam regresi. Misalnya, jika koefisien total_bill adalah 0.1, artinya setiap kenaikan satu unit total bill akan meningkatkan tip sebesar 0.1 unit. Selain koefisien, kita juga melihat R-squared yang mengukur proporsi variansi pada Y yang dapat dijelaskan oleh X. Semakin tinggi R-squared, semakin baik model kita dalam menjelaskan data.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
import statsmodels.api as sm
# Definisikan variabel independen dan dependen
X = tips['total_bill']
y = tips['tip']
# Tambahkan konstanta untuk intercept
X = sm.add_constant(X)
# Fit model OLS dan tampilkan summary
model = sm.OLS(y, X).fit()
print(model.summary())Output:
OLS Regression Results
==============================================================================
Dep. Variable: tip R-squared: 0.457
Model: OLS Adj. R-squared: 0.454
Method: Least Squares F-statistic: 203.4
Date: Mon, 29 Jun 2026 Prob (F-statistic): 6.69e-34
Time: 08:19:24 Log-Likelihood: -350.54
No. Observations: 244 AIC: 705.1
Df Residuals: 242 BIC: 712.1
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.9203 0.160 5.761 0.000 0.606 1.235
total_bill 0.1050 0.007 14.260 0.000 0.091 0.120
==============================================================================
Omnibus: 20.185 Durbin-Watson: 2.151
Prob(Omnibus): 0.000 Jarque-Bera (JB): 37.750
Skew: 0.443 Prob(JB): 6.35e-09
Kurtosis: 4.711 Cond. No. 53.0
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.Output dari model.summary() menampilkan tabel lengkap berisi koefisien, standard error, p-value, confidence interval, R-squared, dan F-statistic. Perhatikan kolom P>|t| — jika nilai ini kurang dari 0.05, maka variabel independen berpengaruh signifikan secara statistik terhadap variabel dependen.
Regresi Linear Berganda dan Seleksi Variabel
Dalam skenario nyata, kita jarang hanya memiliki satu faktor yang memengaruhi variabel target. Regresi linear berganda memungkinkan kita menambahkan beberapa variabel prediktor sekaligus. Persamaannya menjadi:
Y = β₀ + β₁X₁ + β₂X₂ + ... + βₖXₖ + ε
Ketika kita menambahkan lebih banyak prediktor, R-squared cenderung meningkat meskipun prediktor tersebut tidak relevan. Karena itu kita menggunakan Adjusted R-squared yang memberikan penalti untuk setiap tambahan prediktor, sehingga lebih adil dalam membandingkan model dengan jumlah variabel yang berbeda.
Salah satu masalah yang sering muncul dalam regresi berganda adalah multikolinearitas — yaitu ketika dua atau lebih prediktor saling berkorelasi tinggi. Dampaknya adalah standard error koefisien menjadi besar dan interpretasi menjadi tidak stabil. Kita mendeteksi multikolinearitas menggunakan Variance Inflation Factor (VIF). Nilai VIF di atas 5 atau 10 menandakan adanya multikolinearitas serius.
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Multiple regression dengan total_bill dan size
X_multi = tips[['total_bill', 'size']]
X_multi = sm.add_constant(X_multi)
model_multi = sm.OLS(tips['tip'], X_multi).fit()
print("=== SUMMARY REGRESI BERGANDA ===")
print(model_multi.summary())
# Hitung VIF untuk setiap variabel
vif_data = pd.DataFrame()
vif_data['feature'] = X_multi.columns
vif_data['VIF'] = [
variance_inflation_factor(X_multi.values, i)
for i in range(X_multi.shape[1])
]
print("\n=== TABEL VIF ===")
print(vif_data)Output:
=== SUMMARY REGRESI BERGANDA ===
OLS Regression Results
==============================================================================
Dep. Variable: tip R-squared: 0.468
Model: OLS Adj. R-squared: 0.463
Method: Least Squares F-statistic: 105.9
Date: Mon, 29 Jun 2026 Prob (F-statistic): 9.67e-34
Time: 08:19:24 Log-Likelihood: -347.99
No. Observations: 244 AIC: 702.0
Df Residuals: 241 BIC: 712.5
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.6689 0.194 3.455 0.001 0.288 1.050
total_bill 0.0927 0.009 10.172 0.000 0.075 0.111
size 0.1926 0.085 2.258 0.025 0.025 0.361
==============================================================================
Omnibus: 24.753 Durbin-Watson: 2.100
Prob(Omnibus): 0.000 Jarque-Bera (JB): 46.169
Skew: 0.545 Prob(JB): 9.43e-11
Kurtosis: 4.831 Cond. No. 67.6
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
=== TABEL VIF ===
feature VIF
0 const 8.904095
1 total_bill 1.557586
2 size 1.557586Perhatikan bahwa nilai VIF untuk const biasanya tinggi dan itu wajar. Yang perlu diperiksa adalah VIF untuk variabel prediktor seperti total_bill dan size. Nilai VIF yang rendah menandakan tidak ada masalah multikolinearitas yang serius. Namun pemilihan prediktor tidak boleh hanya berdasarkan angka — domain knowledge tetap menjadi faktor paling penting dalam menentukan variabel mana yang layak masuk ke dalam model.
Memvalidasi Asumsi Klasik Regresi Linear
Model regresi linear OLS memiliki empat asumsi utama yang harus dipenuhi agar hasil estimasi bersifat BLUE (Best Linear Unbiased Estimator). Keempat asumsi tersebut adalah linearitas hubungan antara prediktor dan respons, independensi residual (tidak ada autokorelasi), homoskedastisitas (varians residual konstan), dan normalitas residual.
Gambar: Empat asumsi OLS yang dikenal dengan akronim LINE — Sumber: [Beyond Multiple Linear Regression](https://bookdown.org/roback/bookdown-BeyondMLR/) oleh Roback & Legler (CC BY-NC-SA 4.0)
Memvalidasi asumsi regresi seperti memeriksa fondasi sebelum membangun bangunan — jika fondasi retak, hasilnya tidak bisa dipercaya. Dua alat diagnostik yang paling berguna adalah Q-Q plot untuk memeriksa normalitas residual dan residual vs fitted plot untuk memeriksa homoskedastisitas.
import scipy.stats as stats
# Ambil residual dan fitted values dari model
residuals = model_multi.resid
fitted = model_multi.fittedvalues
plt.figure(figsize=(12, 5))
# Residual vs Fitted Plot
plt.subplot(1, 2, 1)
plt.scatter(fitted, residuals, alpha=0.6, edgecolors='k', linewidth=0.5)
plt.axhline(y=0, color='red', linestyle='--', linewidth=1)
plt.xlabel('Fitted Values')
plt.ylabel('Residuals')
plt.title('Residual vs Fitted Plot')
# Q-Q Plot untuk normalitas residual
plt.subplot(1, 2, 2)
stats.probplot(residuals, dist="norm", plot=plt)
plt.title('Q-Q Plot')
plt.tight_layout()
plt.show()Output:
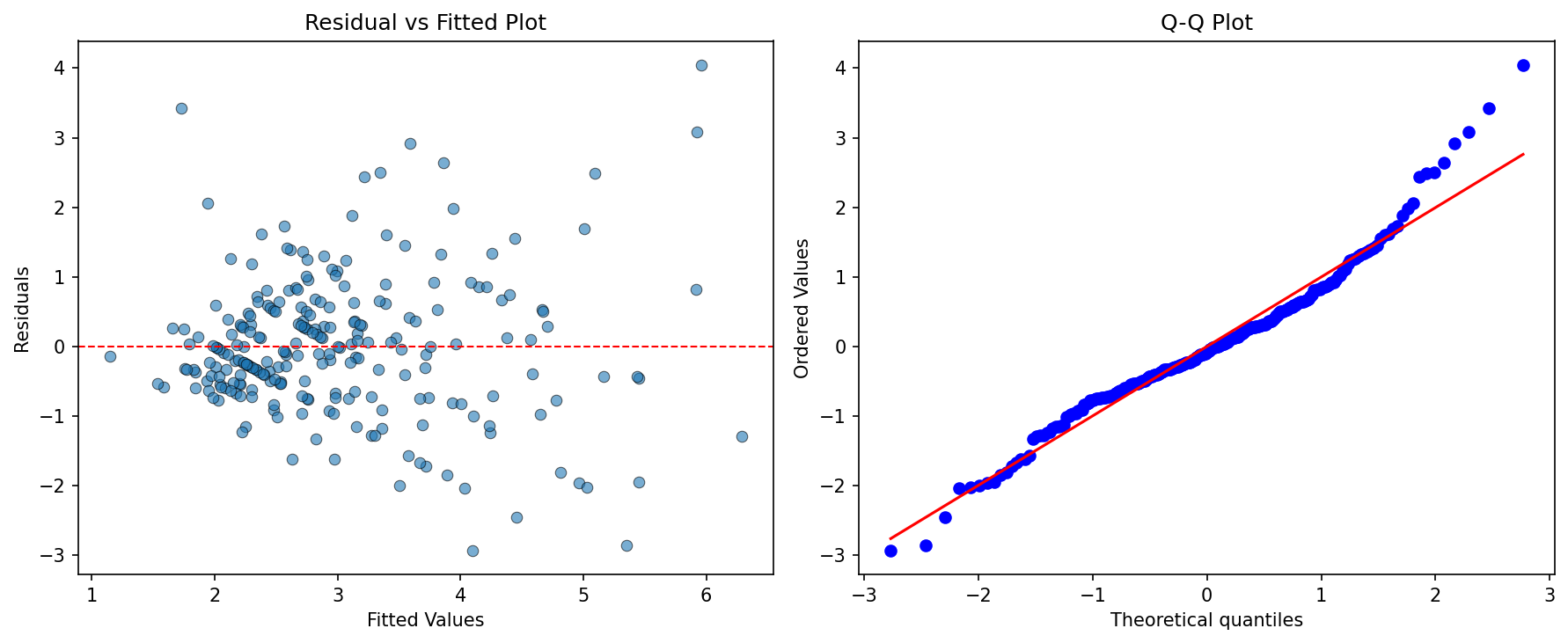
Pada residual vs fitted plot, kita ingin melihat titik-titik tersebar acak di sekitar garis horizontal nol tanpa pola tertentu. Pola berbentuk corong (melebar) menandakan heteroskedastisitas, sementara pola melengkung menandakan hubungan yang tidak linear. Pada Q-Q plot, titik-titik yang mengikuti garis diagonal menandakan residual berdistribusi normal.
Jika asumsi dilanggar, ada beberapa langkah mitigasi yang bisa dilakukan. Transformasi log atau Box-Cox pada variabel dependen dapat mengatasi heteroskedastisitas dan non-normalitas. Robust standard errors (seperti HC3) dapat digunakan untuk memperbaiki standard error tanpa mengubah koefisien. Jika hubungan jelas tidak linear, kita bisa mempertimbangkan regresi polinomial atau metode non-parametrik.
Best Practices dalam Melaporkan Hasil Regresi
Laporan hasil regresi yang baik harus mencakup beberapa komponen esensial: koefisien regresi beserta standard error-nya, p-value atau confidence interval untuk setiap koefisien, R-squared atau Adjusted R-squared, dan jumlah observasi yang digunakan. Informasi ini memungkinkan pembaca untuk menilai sendiri signifikansi dan kekuatan model.
Beberapa kesalahan umum yang harus dihindari. Pertama, overfitting dengan menambahkan terlalu banyak prediktor tanpa justifikasi yang jelas. Kedua, mengabaikan outliers yang dapat mendistorsi garis regresi secara signifikan. Ketiga, menyimpulkan kausalitas dari data observasional — ingat bahwa korelasi tinggi tidak membuktikan hubungan sebab-akibat.
Untuk situasi tertentu, regresi linear OLS bukanlah pilihan terbaik. Jika variabel dependen bersifat biner (0/1), gunakan logistic regression. Jika data menunjukkan tren waktu, pertimbangkan time series models seperti ARIMA. Dan jika asumsi linearitas tidak terpenuhi, cobalah regresi polinomial atau tree-based models sebagai alternatif.
Regresi linear adalah fondasi penting dalam statistika dan machine learning. Menguasai konsep korelasi, OLS, diagnostik asumsi, dan interpretasi koefisien akan membekali kita dengan kemampuan analisis yang kokoh. Untuk pendalaman lebih lanjut tentang statistika dan machine learning, ikuti program Data Science Bootcamp di Rumah Coding — dari dasar statistika sampai model prediktif siap produksi.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner
Memahami Algoritma Random Forest dari Teori sampai Implementasi dengan Scikit-learn untuk Klasifikasi dan Regresi
