Memahami Konsep Statistik Deskriptif dan Implementasinya dengan Python untuk Analisis Data

Setiap proyek data science dimulai dengan langkah yang sama: memahami dataset. Sebelum membangun model machine learning atau menarik kesimpulan inferensial, kita harus tahu karakteristik dasar data yang kita miliki. Statistik deskriptif menyediakan alat untuk merangkum, mendeskripsikan, dan mengidentifikasi pola dalam dataset melalui ukuran numerik dan visualisasi.
Tujuan utama statistik deskriptif adalah menyajikan data dalam bentuk yang mudah dicerna. Berbeda dengan statistik inferensial yang berusaha menarik kesimpulan umum dari sampel, statistik deskriptif fokus pada apa yang bisa diamati langsung dari data yang tersedia. Dengan memahami teknik ini, kita bisa mendeteksi outlier, memahami sebaran nilai, dan memutuskan preprocessing apa yang diperlukan sebelum analisis lanjutan.
Sepanjang artikel ini, kita akan menggunakan dataset tips dari Seaborn sebagai studi kasus. Dataset ini mencatat informasi transaksi di restoran termasuk total tagihan, jumlah tip, jenis kelamin pelanggan, dan hari kunjungan.
!pip install pandas numpy matplotlib seabornimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('tips')
df.head()Output:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4Dataset ini relatif kecil (244 baris) dan bersih, membuatnya ideal untuk mempelajari statistik deskriptif tanpa gangguan data kotor.
Mengenal Ukuran Pemusatan Data — Mean, Median, dan Modus
Ukuran pemusatan data menjawab pertanyaan paling dasar: di manakah pusat dari dataset kita? Tiga metrik utama yang digunakan adalah mean (rata-rata), median (nilai tengah), dan modus (nilai yang paling sering muncul).
Mean dihitung dengan menjumlahkan semua nilai lalu membaginya dengan jumlah observasi. Metrik ini sangat intuitif dan banyak digunakan, tetapi memiliki kelemahan signifikan: sensitif terhadap outlier. Satu nilai yang sangat besar atau sangat kecil bisa menarik mean menjauh dari representasi data yang sebenarnya.
Median adalah nilai tengah setelah data diurutkan. Jika jumlah data genap, median adalah rata-rata dari dua nilai tengah. Median tidak terpengaruh oleh outlier karena posisinya di tengah urutan, bukan hasil perhitungan aritmetika. Ketika distribusi data menceng (skewed), median sering menjadi representasi yang lebih akurat untuk "nilai tipikal" dibandingkan mean.
Modus adalah nilai yang paling sering muncul dalam dataset. Metrik ini sangat berguna untuk data kategorikal, seperti hari apa pelanggan paling sering datang atau metode pembayaran apa yang paling populer.
mean_total = df['total_bill'].mean()
median_total = df['total_bill'].median()
mode_total = df['total_bill'].mode()[0]
print(f"Mean total bill: ${mean_total:.2f}")
print(f"Median total bill: ${median_total:.2f}")
print(f"Mode total bill: ${mode_total:.2f}")Output:
Mean total bill: $19.79
Median total bill: $17.80
Mode total bill: $13.42Dari output di atas, kita melihat bahwa mean total bill berada di $19.79 sedangkan median sekitar $17.80. Perbedaan ini mengindikasikan distribusi yang menceng ke kanan (right-skewed), artinya ada beberapa transaksi dengan tagihan sangat tinggi yang menarik mean ke atas. Modus menunjukkan nilai total bill yang paling sering muncul, yang bisa berbeda jauh dari mean dan median tergantung distribusi data.
Memahami Ukuran Penyebaran Data — Range, Varians, dan Standar Deviasi
Ukuran pemusatan saja tidak cukup untuk memahami dataset secara utuh. Dua dataset bisa memiliki mean yang identik tetapi karakteristik yang sangat berbeda karena sebaran nilainya tidak sama. Di sinilah ukuran penyebaran data berperan.
Range adalah selisih antara nilai maksimum dan minimum. Ini adalah ukuran penyebaran yang paling sederhana, tetapi sangat rentan terhadap outlier. Satu nilai ekstrem bisa membuat range terlihat sangat lebar meskipun sebagian besar data mengelompok di area sempit.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Varians mengukur rata-rata kuadrat selisih setiap nilai dari mean. Semakin besar varians, semakin tersebar data dari pusatnya. Namun, karena satuannya kuadrat dari unit data asli (misalnya dollar kuadrat), varians agak sulit diinterpretasikan secara langsung.
Standar deviasi adalah akar kuadrat dari varians, mengembalikan satuan ke unit asli data. Dalam distribusi normal, sekitar 68% data berada dalam satu standar deviasi dari mean, 95% dalam dua standar deviasi, dan 99.7% dalam tiga standar deviasi. Aturan 68-95-99.7 ini sangat berguna untuk mengidentifikasi outlier dan memahami sebaran data secara intuitif.
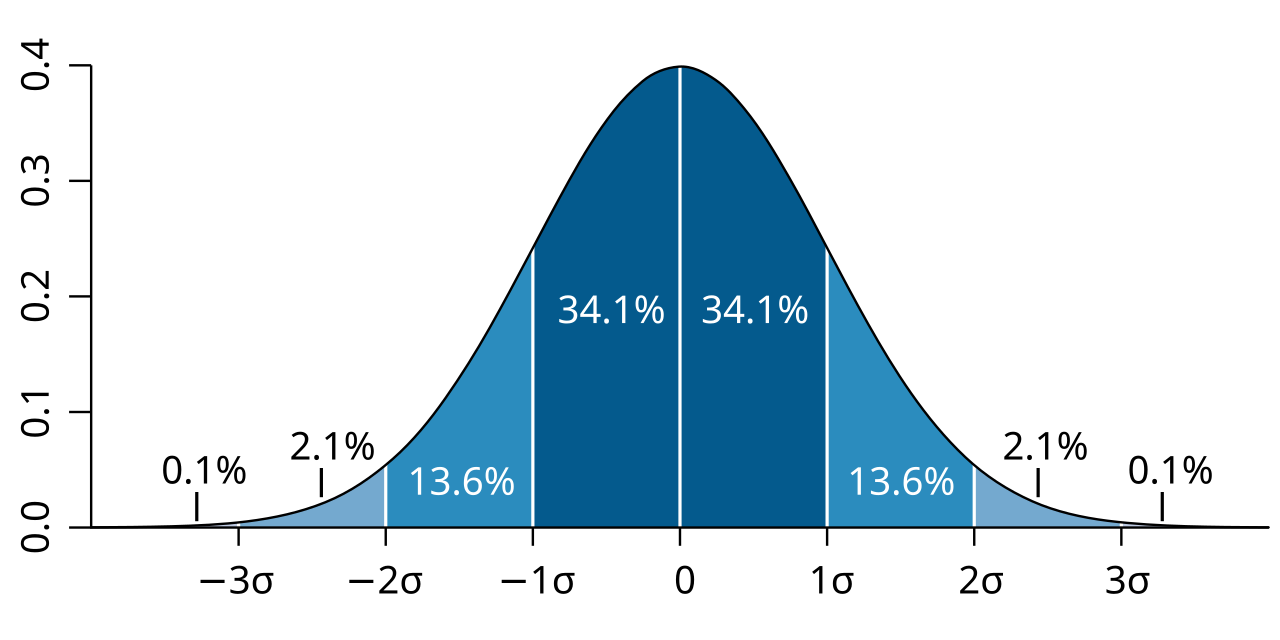
Gambar: Diagram standar deviasi pada distribusi normal — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Standard_deviation_diagram.svg)
range_total = df['total_bill'].max() - df['total_bill'].min()
variance_total = df['total_bill'].var()
std_total = df['total_bill'].std()
print(f"Range: ${range_total:.2f}")
print(f"Variance: {variance_total:.2f}")
print(f"Standard Deviation: ${std_total:.2f}")
# Visualisasi: histogram dengan anotasi mean dan std
plt.figure(figsize=(10, 6))
sns.histplot(df['total_bill'], bins=20, kde=True)
plt.axvline(mean_total, color='red', linestyle='--', label=f'Mean: ${mean_total:.2f}')
plt.axvline(mean_total + std_total, color='green', linestyle=':', label=f'+1 Std: ${mean_total + std_total:.2f}')
plt.axvline(mean_total - std_total, color='green', linestyle=':', label=f'-1 Std: ${mean_total - std_total:.2f}')
plt.title('Distribusi Total Bill dengan Mean dan Standar Deviasi')
plt.xlabel('Total Bill ($)')
plt.ylabel('Frekuensi')
plt.legend()
plt.show()Output:
Range: $47.74
Variance: 79.25
Standard Deviation: $8.90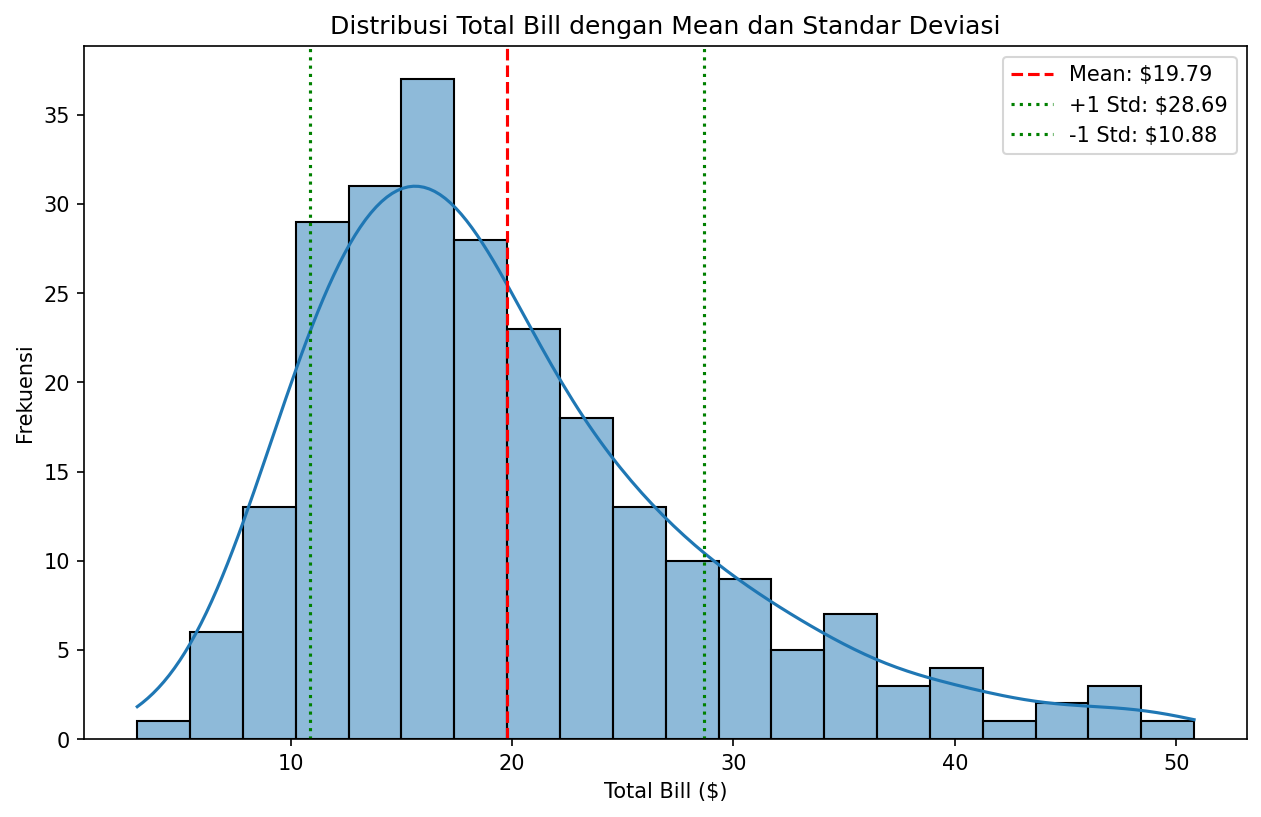
Histogram di atas menunjukkan distribusi total bill dengan garis vertikal untuk mean dan satu standar deviasi di atas dan di bawahnya. Kita bisa melihat secara visual bahwa distribusi menceng ke kanan — ekor kanan lebih panjang dengan beberapa nilai tinggi yang jarang terjadi.
Visualisasi Statistik Deskriptif — Box Plot dan Distribusi
Visualisasi adalah jembatan antara angka mentah dan insight yang bisa ditindaklanjuti. Box plot dan histogram adalah dua alat visual paling informatif dalam statistik deskriptif.
Box plot menampilkan ringkasan lima angka: minimum, kuartil pertama (Q1), median (Q2), kuartil ketiga (Q3), dan maksimum. Outlier ditampilkan sebagai titik-titik di luar "kumis" box plot. Dalam satu gambar, kita bisa melihat pusat data (median), penyebaran (IQR = Q3 - Q1), dan potensi outlier sekaligus.
Histogram menunjukkan distribusi frekuensi data dalam bentuk batang. Dengan menambahkan KDE (Kernel Density Estimation), kita mendapatkan kurva distribusi yang halus yang memudahkan identifikasi bentuk distribusi: simetris, menceng ke kiri, menceng ke kanan, atau multimodal.
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Box plot
sns.boxplot(y=df['total_bill'], ax=axes[0], color='steelblue')
axes[0].set_title('Box Plot Total Bill')
axes[0].set_ylabel('Total Bill ($)')
# Histogram dengan KDE
sns.histplot(df['total_bill'], bins=20, kde=True, ax=axes[1], color='steelblue')
axes[1].axvline(mean_total, color='red', linestyle='--', label=f'Mean: ${mean_total:.2f}')
axes[1].axvline(median_total, color='orange', linestyle='--', label=f'Median: ${median_total:.2f}')
axes[1].set_title('Histogram Total Bill dengan KDE')
axes[1].set_xlabel('Total Bill ($)')
axes[1].set_ylabel('Frekuensi')
axes[1].legend()
plt.tight_layout()
plt.show()Output:
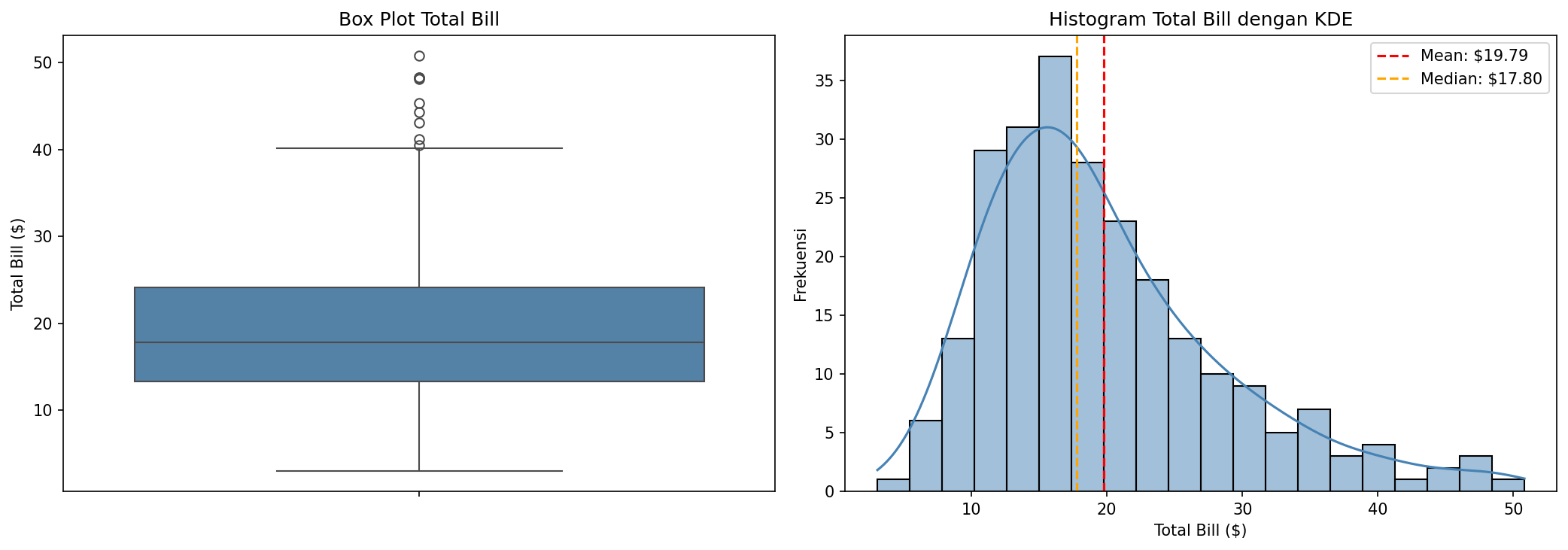
Box plot akan memperjelas posisi median, rentang interkuartil, dan titik-titik outlier yang berada di atas Q3 + 1.5*IQR. Sementara itu, histogram dengan KDE dan anotasi mean serta median memperkuat observasi kita sebelumnya tentang distribusi yang menceng ke kanan. Kombinasi kedua visual ini memberikan pemahaman yang jauh lebih kaya dibandingkan angka-angka statistik saja.
Menyusun Ringkasan Statistik dan Insight Awal
Pandas menyediakan metode .describe() yang menghasilkan ringkasan statistik dalam satu baris kode. Metode ini menghitung count, mean, std, min, kuartil (25%, 50%, 75%), dan max untuk setiap kolom numerik secara otomatis.
df.describe()Output:
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000Output dari .describe() di atas sangat informatif. Kolom count menunjukkan jumlah data non-null, yang berguna untuk deteksi missing value. Kolom mean dan std memberikan gambaran pusat dan sebaran data. Kuartil membantu kita memahami distribusi secara lebih granular: 25% data berada di bawah Q1, 50% di bawah median, dan 75% di bawah Q3.
Menggabungkan insight dari semua teknik yang telah kita pelajari, kita bisa menyusun profil dataset yang komprehensif. Untuk dataset tips, misalnya:
- Rata-rata total bill sekitar $19.79, tetapi median $17.80 mengindikasikan distribusi menceng
- Standar deviasi $8.90 menunjukkan variasi yang cukup lebar
- Ada outlier dengan total bill di atas $40 yang perlu diinvestigasi lebih lanjut
- Kolom
size(jumlah orang per meja) memiliki median 2, yang masuk akal untuk restoran
Profil ini menjadi dasar untuk keputusan preprocessing dan analisis selanjutnya. Misalnya, kita mungkin ingin menangani outlier sebelum membangun model regresi, atau membuat segmen pelanggan berdasarkan rentang total bill.
Statistik deskriptif adalah fondasi yang tidak boleh dilewatkan dalam setiap proyek data science. Teknik-teknik yang telah kita praktikkan — ukuran pemusatan, ukuran penyebaran, dan visualisasi — memberikan pemahaman awal yang esensial sebelum melangkah ke analisis yang lebih kompleks. Ingin memperdalam keterampilan data science Anda? Bergabunglah dengan bootcamp Rumah Coding untuk pembelajaran terstruktur dari dasar hingga mahir, mencakup statistik, Python, machine learning, dan studi kasus dunia nyata.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner
Memahami Algoritma Random Forest dari Teori sampai Implementasi dengan Scikit-learn untuk Klasifikasi dan Regresi
