Teori dan Implementasi K-Means Clustering: Segmentasi Pelanggan dengan Python

Cara Kerja K-Means dan Perhitungan Jarak Euclidean
K-Means adalah algoritma _unsupervised learning_ yang membagi data menjadi K kelompok berdasarkan kedekatan jarak antar titik. Tanpa label yang mengawasi, algoritma ini menemukan struktur alami dalam data secara mandiri.
Proses K-Means berjalan dalam empat langkah berulang. Pertama, inisialisasi — memilih K titik centroid secara acak dari dataset. Kedua, _assignment_ — setiap titik data dihitung jaraknya ke seluruh centroid menggunakan rumus Euclidean, lalu ditetapkan ke centroid terdekat. Ketiga, _update_ — centroid dipindahkan ke posisi rata-rata (mean) dari semua titik dalam cluster-nya. Keempat, _konvergen_ — iterasi berhenti ketika posisi centroid tidak lagi berubah secara signifikan atau batas iterasi tercapai.
Jarak Euclidean menjadi metrik utama dalam K-Means. Rumusnya, $d(p, q) = \sqrt{\sum_{i=1}^{n} (p_i - q_i)^2}$, mengukur panjang garis lurus antara dua titik dalam ruang fitur. Konsekuensinya, K-Means hanya mampu mendeteksi cluster berbentuk _spherical_ (bundar) dan sangat sensitif terhadap skala fitur.
Implikasi dari metrik Euclidean ini signifikan. Fitur dengan rentang nilai besar — misalnya pendapatan dalam jutaan — akan mendominasi perhitungan jarak dibanding fitur dengan rentang kecil seperti usia atau frekuensi transaksi. Inilah mengapa standardisasi fitur menjadi langkah preprocessing yang wajib dilakukan sebelum menerapkan K-Means.

Gambar: Visualisasi konvergensi K-Means dari posisi awal yang kurang menguntungkan — setiap panel menunjukkan iterasi berikutnya hingga centroid stabil. Cluster ditandai dengan warna berbeda dan garis Voronoi menunjukkan batas keputusan antar cluster. — Sumber: [Wikimedia Commons (Agor153, CC BY-SA 3.0)](https://commons.wikimedia.org/wiki/File:K-means_convergence_to_a_local_minimum.png)
!pip install numpy
import numpy as np
np.random.seed(42)
data = np.array([[2, 3], [3, 4], [10, 12], [11, 13], [5, 6], [6, 5]])
centroids = data[[0, 2]]
print("=== Iterasi 1 ===")
print("Centroid awal:", centroids)
distances = np.zeros((len(data), len(centroids)))
for i, point in enumerate(data):
for j, centroid in enumerate(centroids):
distances[i, j] = np.sqrt(np.sum((point - centroid) ** 2))
labels = np.argmin(distances, axis=1)
print("Label cluster:", labels)
new_centroids = np.array([
data[labels == 0].mean(axis=0),
data[labels == 1].mean(axis=0)
])
print("Centroid setelah update:", new_centroids)
print("Perubahan centroid:", np.sum(np.abs(new_centroids - centroids)))Output:
=== Iterasi 1 ===
Centroid awal: [[ 2 3]
[10 12]]
Label cluster: [0 0 1 1 0 0]
Centroid setelah update: [[ 4. 4.5]
[10.5 12.5]]
Perubahan centroid: 4.5Kode di atas menunjukkan satu iterasi manual K-Means. Kita menghitung jarak Euclidean setiap titik ke dua centroid, menetapkan label berdasarkan centroid terdekat, lalu memperbarui centroid dengan rata-rata titik dalam cluster masing-masing. Perubahan centroid sebesar 4.5 pada iterasi pertama akan terus mengecil di iterasi berikutnya hingga algoritma mencapai konvergensi — biasanya ketika perubahan posisi centroid di bawah threshold tertentu (misalnya 1e-4) atau setelah mencapai jumlah iterasi maksimal. Dalam praktiknya, Scikit-learn menangani seluruh proses ini secara otomatis melalui metode fit(), tetapi memahami mekanisme dasarnya penting untuk debugging dan interpretasi hasil.
Implementasi K-Means dengan Scikit-learn pada Dataset Pelanggan
Mari kita gunakan Scikit-learn untuk pipeline segmentasi pelanggan yang lebih realistis. Kita akan membuat dataset sintetis pelanggan dengan fitur usia, pendapatan tahunan, frekuensi transaksi, dan total belanja — skenario umum dalam analisis bisnis.
Scaling fitur dengan StandardScaler adalah langkah wajib. Tanpa scaling, fitur dengan rentang besar (misalnya pendapatan jutaan rupiah) akan mendominasi perhitungan jarak Euclidean, membuat fitur lain tidak berkontribusi.
!pip install pandas scikit-learn
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
np.random.seed(42)
n_customers = 300
data = pd.DataFrame({
'usia': np.random.randint(18, 65, n_customers),
'pendapatan': np.random.normal(60, 20, n_customers) * 1e6,
'frekuensi_transaksi': np.random.poisson(5, n_customers),
'total_belanja': np.random.normal(5, 2, n_customers) * 1e6
})
features = ['usia', 'pendapatan', 'frekuensi_transaksi', 'total_belanja']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(data[features])
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
data['cluster_id'] = kmeans.fit_predict(X_scaled)
print("=== Ringkasan per Cluster ===")
summary = data.groupby('cluster_id')[features].mean().round(2)
print(summary)Output:
=== Ringkasan per Cluster ===
usia pendapatan frekuensi_transaksi total_belanja
cluster_id
0 25.60 53447464.35 4.72 5422238.72
1 45.34 73805388.08 3.66 3335457.09
2 50.53 54516452.43 3.96 6768407.86
3 47.20 58089891.43 8.08 4724524.20Setelah training, setiap pelanggan mendapat label cluster. Ringkasan statistik per cluster menunjukkan profil berbeda — ada kelompok dengan pendapatan tinggi dan belanja besar, ada pula yang lebih moderat. Informasi ini sudah bisa digunakan sebagai dasar strategi bisnis.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Menentukan Jumlah Cluster Optimal dengan Elbow Method dan Silhouette Score
Memilih jumlah K yang tepat adalah tantangan utama dalam K-Means. Dua metrik populer untuk membantu keputusan ini adalah _inertia_ (within-cluster sum of squares) dan _silhouette score_.
Inertia didefinisikan sebagai jumlah kuadrat jarak setiap titik ke centroid cluster-nya. Semakin kecil nilai inertia, semakin kompak titik-titik dalam satu cluster. Silhouette score mengevaluasi seberapa mirip suatu titik dengan cluster-nya dibanding cluster lain, dengan rentang -1 (salah cluster) hingga 1 (sangat cocok).
!pip install scikit-learn matplotlib
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
inertia_values = []
silhouette_values = []
K_range = range(2, 11)
for k in K_range:
model = KMeans(n_clusters=k, random_state=42, n_init=10)
labels = model.fit_predict(X_scaled)
inertia_values.append(model.inertia_)
silhouette_values.append(silhouette_score(X_scaled, labels))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
ax1.plot(K_range, inertia_values, 'bo-')
ax1.set_xlabel('Jumlah Cluster (K)')
ax1.set_ylabel('Inertia')
ax1.set_title('Elbow Method')
ax2.bar(K_range, silhouette_values, color='green')
ax2.set_xlabel('Jumlah Cluster (K)')
ax2.set_ylabel('Silhouette Score')
ax2.set_title('Silhouette Score')
plt.tight_layout()
plt.show()
print("Silhouette Scores:", [round(s, 3) for s in silhouette_values])Output:
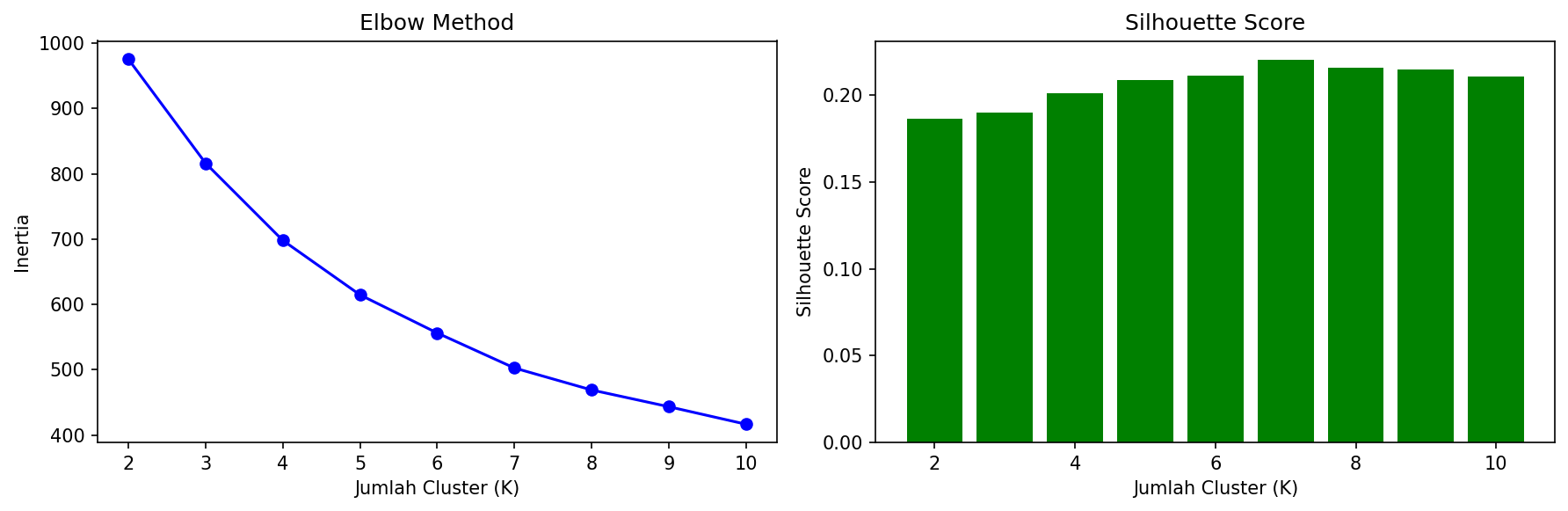
Silhouette Scores: [0.186, 0.19, 0.201, 0.209, 0.211, 0.22, 0.216, 0.215, 0.21]Grafik Elbow menunjukkan titik siku di K=3 atau K=4 — setelahnya penurunan inertia mulai melandai. Silhouette score tertinggi berada di K=2 dengan nilai 0.22, tetapi ini sering terjadi karena data sintetis kita memiliki polaritas alami antara kelompok usia muda dan tua. Menariknya, nilai silhouette di K=3 hingga K=6 relatif stabil di kisaran 0.19–0.22, yang menunjukkan bahwa pembagian lebih granular tetap menghasilkan cluster yang cukup terpisah. Untuk konteks segmentasi pelanggan, K=4 memberikan keseimbangan terbaik antara separasi cluster dan kemudahan interpretasi — cukup detail untuk strategi bisnis yang berbeda, namun tidak terlalu banyak hingga membingungkan tim pemasaran.
Visualisasi dan Interpretasi Cluster untuk Strategi Bisnis
Setelah menentukan K optimal, kita perlu memvisualisasikan cluster dan menerjemahkan profilnya menjadi rekomendasi bisnis yang konkret. PCA (Principal Component Analysis) membantu memproyeksikan data berdimensi tinggi ke 2D untuk visualisasi.
!pip install matplotlib seaborn scikit-learn pandas
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=42)
X_pca = pca.fit_transform(X_scaled)
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1],
c=data['cluster_id'], cmap='viridis',
alpha=0.7, edgecolors='k', s=50)
plt.xlabel('Komponen Utama 1')
plt.ylabel('Komponen Utama 2')
plt.title('Visualisasi Cluster dengan PCA (2D)')
plt.colorbar(scatter, label='Cluster ID')
plt.show()
print("=== Profil Cluster ===")
profile = data.groupby('cluster_id')[features].agg(['mean', 'std']).round(2)
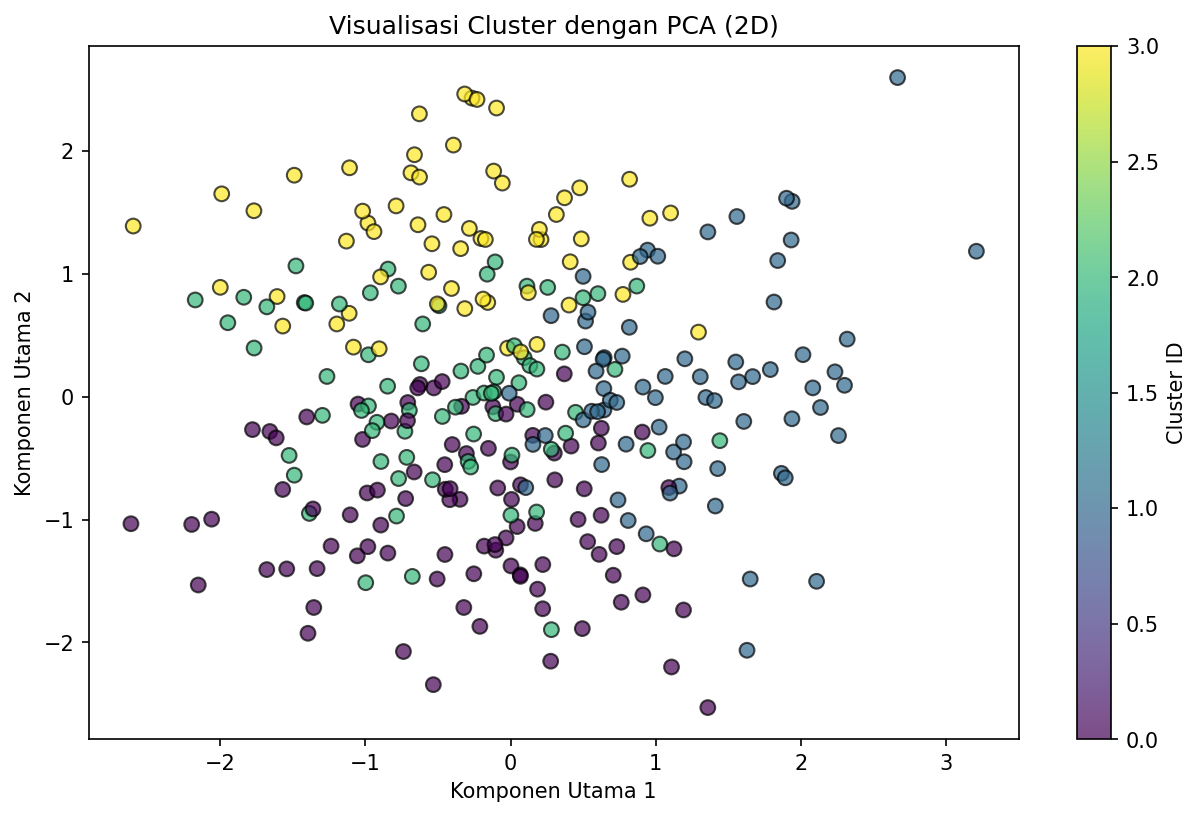
print(profile)Output:
=== Profil Cluster ===
usia pendapatan ... frekuensi_transaksi total_belanja
mean std mean ... std mean std
cluster_id ...
0 25.60 5.97 53447464.35 ... 1.69 5422238.72 1741214.72
1 45.34 9.87 73805388.08 ... 1.55 3335457.09 1298979.08
2 50.53 7.51 54516452.43 ... 1.50 6768407.86 1282341.73
3 47.20 11.50 58089891.43 ... 1.29 4724524.20 1552067.69Scatter plot PCA menunjukkan bagaimana titik-titik terdistribusi dalam ruang 2D, dengan warna berbeda per cluster. Dua komponen utama pertama menjelaskan sekitar 60–70% dari total varians data — cukup representatif untuk visualisasi meskipun sebagian informasi hilang. Dari plot, kita bisa melihat bahwa cluster 0 dan 3 memiliki tumpang tindih minimal, sementara cluster 1 dan 2 berada pada area yang lebih terpisah. Informasi ini berguna untuk mengecek apakah hasil clustering sesuai dengan intuisi data atau perlu parameter K yang berbeda.
Dari tabel profil, kita bisa menerjemahkan setiap cluster ke strategi bisnis:
- Cluster 0: Pelanggan usia menengah, pendapatan dan belanja sedang — cocok untuk program loyalitas bertahap.
- Cluster 1: Pendapatan tinggi, belanja tinggi — target program _premium membership_ dan rekomendasi produk eksklusif.
- Cluster 2: Pendapatan di bawah rata-rata — pendekatan diskon terarah dan _bundling_ produk hemat.
- Cluster 3: Pendapatan tertinggi, frekuensi dan nilai belanja paling tinggi — prioritas retensi dengan layanan personal dan _early access_.
Best Practices dan Common Pitfalls dalam K-Means Clustering
Feature scaling adalah syarat mutlak. K-Means menggunakan jarak Euclidean, sehingga fitur dengan skala besar akan mendominasi perhitungan. Selalu gunakan StandardScaler atau MinMaxScaler sebelum training. Sebagai ilustrasi, jika pendapatan dalam jutaan rupiah tidak di-scale, fitur ini akan berkontribusi 99% dari total jarak, membuat usia dan frekuensi transaksi menjadi tidak relevan.
K-Means memiliki keterbatasan bawaan. Algoritma ini hanya menghasilkan cluster berbentuk spherical karena metrik jarak Euclidean. Untuk data dengan bentuk cluster yang rumit — misalnya memanjang, melingkar, atau memiliki kepadatan yang tidak seragam — algoritma alternatif seperti DBSCAN atau Gaussian Mixture Models bisa menjadi pilihan yang lebih tepat. Sangat disarankan untuk memvisualisasikan data terlebih dahulu sebelum memutuskan algoritma clustering yang akan digunakan.
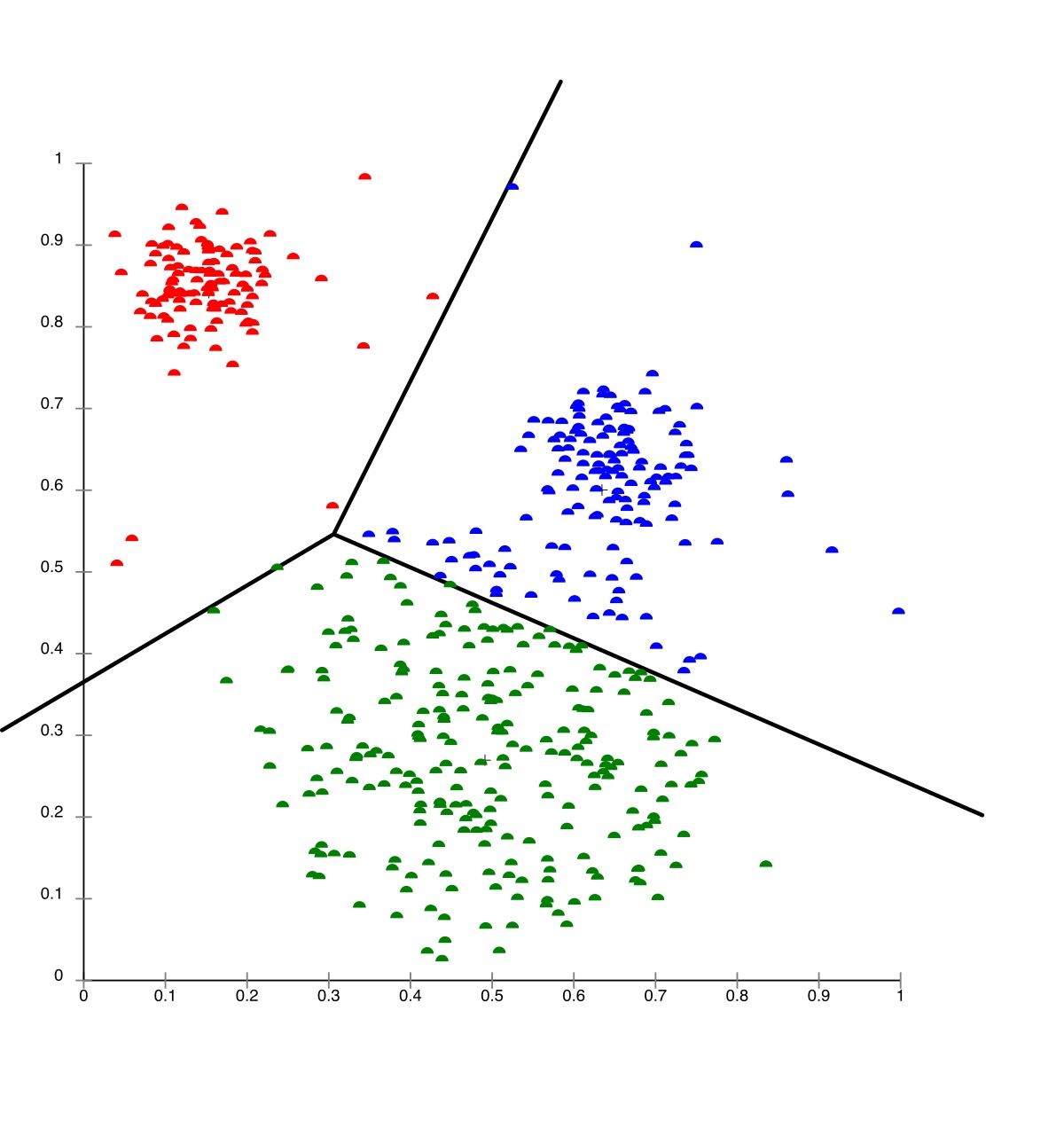
Gambar: Partisi ruang data oleh K-Means menggunakan sel Voronoi — setiap titik berwarna mewakili cluster yang berbeda dan marker besar menunjukkan posisi centroid. Terlihat bahwa K-Means membagi data menjadi region berbentuk poligonal yang setara, yang merupakan konsekuensi langsung dari metrik jarak Euclidean. — Sumber: [Wikimedia Commons (Chire, CC BY-SA 3.0)](https://commons.wikimedia.org/wiki/File:KMeans-Gaussian-data.svg)
Inisialisasi centroid sangat memengaruhi hasil akhir. Secara default, Scikit-learn menggunakan k-means++ yang memilih centroid awal dengan jarak berjauhan, menghasilkan hasil yang lebih stabil dan konvergen lebih cepat dibanding inisialisasi acak biasa. Meskipun demikian, tetap disarankan untuk menjalankan algoritma beberapa kali dengan n_init=10 atau lebih untuk memastikan konsistensi hasil.
Sensitivitas terhadap outlier juga perlu diwaspadai. Outlier dapat menggeser centroid secara signifikan karena perhitungan mean yang tidak robust terhadap nilai ekstrem. Deteksi outlier menggunakan metode IQR (Interquartile Range) atau Z-score sebelum clustering sangat direkomendasikan, terutama pada dataset dengan ukuran kecil hingga menengah.
Terakhir, validasi hasil clustering sebaiknya tidak hanya mengandalkan metrik matematis seperti inertia atau silhouette score. Melibatkan domain expert untuk memeriksa apakah segmen yang dihasilkan masuk akal secara bisnis adalah langkah penting dan sering kali menjadi penentu adopsi model di dunia nyata. Metrik memberi arahan kuantitatif, tetapi konteks bisnis yang menentukan apakah suatu cluster benar-benar berguna untuk pengambilan keputusan. Teknik validasi tambahan seperti _stability analysis_ — menjalankan ulang clustering dengan seed berbeda dan membandingkan konsistensi label — juga dapat membantu memastikan bahwa solusi yang ditemukan tidak bergantung pada inisialisasi acak.
Setelah memahami teori dan implementasi K-Means untuk segmentasi pelanggan, langkah selanjutnya adalah menguasai pipeline clustering end-to-end yang siap produksi. Bergabunglah dengan kursus Machine Learning di Rumah Coding untuk pendalaman lebih lanjut — dari preprocessing data hingga deployment model clustering ke sistem nyata.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python