Analisis Komparatif Arsitektur LLM Hybrid: Samba, Hymba, Griffin, dan Delta Net
Keterbatasan Attention Murni dan Munculnya Pendekatan Hybrid
Transformer architecture yang diperkenalkan oleh Vaswani et al. pada 2017 telah menjadi fondasi hampir semua Large Language Model (LLM) modern. Mekanisme self-attention di dalamnya memungkinkan model menangkap ketergantungan jarak jauh antar token dengan sangat efektif. Namun, kompleksitas kuadratik O(n²) dari attention mechanism menjadi bottleneck serius ketika panjang konteks input membesar. Model seperti GPT-4 atau Llama 3 membutuhkan sumber daya komputasi yang sangat besar untuk memproses konteks puluhan ribu token.
State Space Models (SSM) seperti Mamba muncul sebagai alternatif menarik dengan kompleksitas linear O(n). Mamba menawarkan efisiensi komputasi yang jauh lebih baik pada konteks panjang, tetapi akurasi pada task tertentu — terutama yang membutuhkan retrieval presisi tinggi — masih kalah dibanding attention mechanism.
Dari sinilah pendekatan arsitektur hybrid lahir. Ide dasarnya sederhana: menggabungkan kekuatan attention dalam memproses informasi detail dengan efisiensi SSM dalam menangani konteks panjang. Empat arsitektur yang akan kita bahas — Samba dari Microsoft Research, Hymba dari NVIDIA dan NYU, Griffin dari Google DeepMind, dan Delta Net dari Shanghai AI Lab — masing-masing memiliki pendekatan unik dalam mengintegrasikan kedua mekanisme ini.
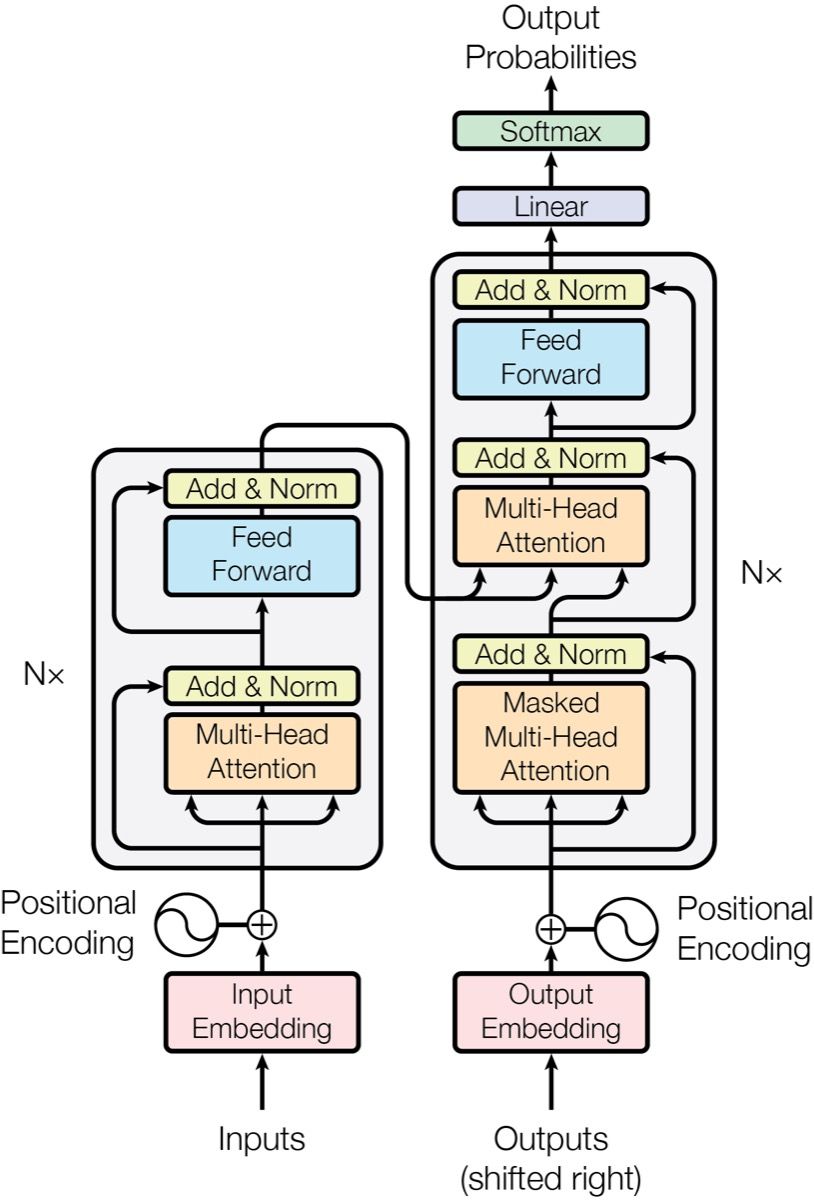
Gambar: Arsitektur Transformer encoder-decoder yang menjadi fondasi LLM modern — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Attention_Is_All_You_Need_-_Encoder-decoder_Architecture.png) (CC BY-SA 4.0)
SSM bertindak seperti ringkasan eksekutif yang memberikan gambaran umum konteks, sementara attention bekerja seperti membaca dokumen asli halaman per halaman untuk detail spesifik. Mari kita lihat bagaimana masing-masing arsitektur mengimplementasikan filosofi ini.
Samba — Interleaving Mamba dengan Sliding Window Attention
Samba dikembangkan oleh Microsoft Research sebagai jawaban atas tantangan long-context pada LLM. Arsitektur ini menggabungkan lapisan Mamba (SSM) dengan sliding window attention (SWA) dalam pola interleaving yang sistematis.
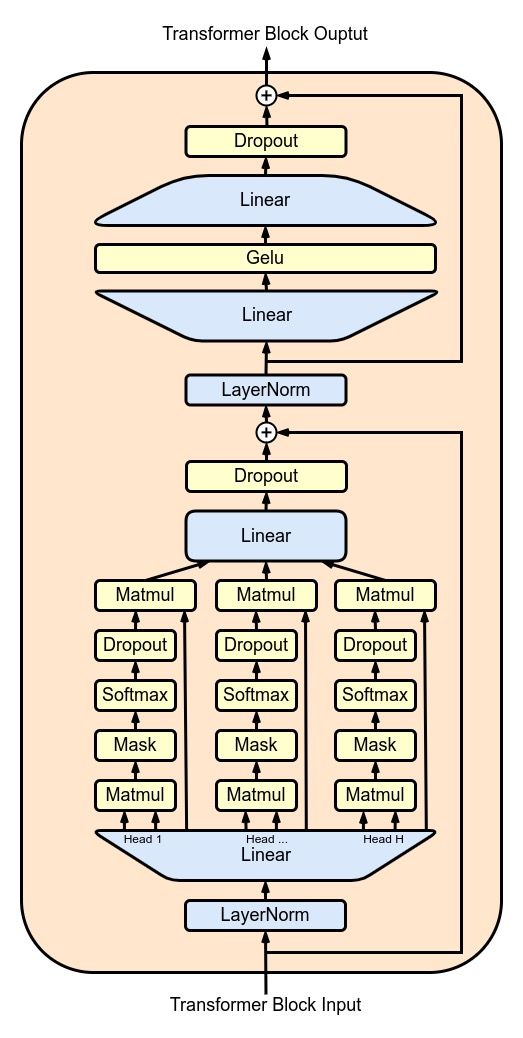
Gambar: Diagram blok transformer GPT (decoder-only) — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Gpt-transformer-block.png) (CC BY-SA 4.0)
Pada setiap blok Samba, terdapat dua sub-lapisan utama: lapisan Mamba yang bertanggung jawab menangani konteks global secara efisien, dan lapisan SWA yang memproses informasi lokal dengan presisi tinggi. Pola ini memungkinkan Samba mempertahankan kompleksitas komputasi linear O(n) sambil tetap menghasilkan representasi yang kaya secara kontekstual.
Keunggulan utama Samba terletak pada kemampuannya menangani konteks hingga 1 juta token. Ini dicapai karena lapisan Mamba melakukan kompresi representasi konteks secara efisien, sementara SWA memastikan detail lokal tidak hilang dalam proses kompresi tersebut. Hasil benchmark menunjukkan Samba unggul pada task long-context retrieval dan reasoning dibandingkan model transformer murni dengan ukuran yang sebanding.
Berikut adalah contoh kode untuk memuat dan melakukan inference dengan model Samba menggunakan Hugging Face Transformers:
!pip install transformers torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "microsoft/samba-1.8b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
long_context = "Teori relativitas umum yang dikemukakan oleh Albert Einstein " * 5000
inputs = tokenizer(long_context, return_tensors="pt", truncation=True, max_length=4096)
with torch.no_grad():
outputs = model.generate(
inputs.input_ids,
max_new_tokens=50,
temperature=0.7
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Output:", response[:200])
print("---")
print(f"Input tokens: {inputs.input_ids.shape[1]}")Kode di atas menunjukkan bagaimana Samba menangani konteks panjang dengan efisien. Kita cukup memuat model dan tokenizer melalui API standar Transformers, lalu memberikan input dalam jumlah besar tanpa kehabisan memori. Fokus utama di sini adalah pada kemampuan model memproses input panjang tanpa peningkatan konsumsi memori yang eksplosif — sesuatu yang tidak mungkin dilakukan oleh transformer murni pada perangkat keras konsumen.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Hymba dan Griffin — Gated Recurrence Bertemu Local Attention
Meskipun Hymba dan Griffin sama-sama menggabungkan mekanisme recurrence dengan attention, pendekatan mereka berbeda secara fundamental.
Hymba, hasil kolaborasi NVIDIA dan NYU, memperkenalkan hybrid head architecture yang unik. Arsitektur ini menggunakan shared-head SSM berdampingan dengan grouped-query attention (GQA). Inovasi kunci Hymba terletak pada mekanisme meta-learning token-as-head, di mana model secara dinamis mempelajari token mana yang paling penting untuk diproses oleh attention head dan token mana yang cukup ditangani oleh SSM. Hasilnya, Hymba mencapai keseimbangan efisien antara kualitas dan kecepatan.
Griffin dari Google DeepMind mengambil pendekatan berbeda dengan menggunakan RG-LRU (Real-Gated Linear Recurrence) yang dipasangkan dengan local sliding attention. RG-LRU adalah varian gated linear recurrence yang memungkinkan model mempertahankan informasi jangka panjang melalui mekanisme gating adaptif. Berbeda dengan Mamba yang menggunakan seleksi berbasis learning, RG-LRU menggunakan gating yang lebih sederhana secara komputasi namun tetap efektif.
Perbedaan paling mencolok antara Hymba dan Griffin terletak pada mekanisme seleksi informasinya. Hymba menggunakan SSM tradisional dengan meta-learning untuk menentukan prioritas token, sementara Griffin mengandalkan RG-LRU dengan gating yang lebih ringan. Dalam praktiknya, Hymba cenderung unggul pada task yang membutuhkan presisi tinggi, sedangkan Griffin lebih efisien pada skenario dengan sumber daya komputasi terbatas.
Mari kita simulasikan perbandingan kompleksitas komputasi antara arsitektur attention murni dan hybrid menggunakan PyTorch:
!pip install torch
import torch
import time
def simulate_attention_complexity(seq_len, d_model):
q = torch.randn(1, seq_len, d_model)
k = torch.randn(1, seq_len, d_model)
v = torch.randn(1, seq_len, d_model)
start = time.time()
attn_scores = torch.matmul(q, k.transpose(-2, -1))
attn_weights = torch.softmax(attn_scores / (d_model ** 0.5), dim=-1)
output = torch.matmul(attn_weights, v)
elapsed = time.time() - start
flops_estimate = 2 * seq_len * seq_len * d_model
return elapsed, flops_estimate
def simulate_hybrid_complexity(seq_len, d_model, window_size=512):
start = time.time()
sliding_q = torch.randn(1, seq_len, d_model)
sliding_k = torch.randn(1, window_size, d_model)
attn = torch.matmul(sliding_q[:, :window_size], sliding_k.transpose(-2, -1))
ssm_state = torch.randn(1, d_model)
for i in range(seq_len):
ssm_state = 0.9 * ssm_state + 0.1 * torch.randn(1, d_model)
elapsed = time.time() - start
flops_estimate = 2 * seq_len * window_size * d_model + 4 * seq_len * d_model
return elapsed, flops_estimate
seq_lens = [512, 1024, 2048, 4096, 8192]
d_model = 768
print(f"{'Sequence Length':<15} {'Attention (ms)':<20} {'Hybrid (ms)':<20} {'FLOPs Ratio':<15}")
print("-" * 70)
for seq_len in seq_lens:
attn_time, attn_flops = simulate_attention_complexity(seq_len, d_model)
hybrid_time, hybrid_flops = simulate_hybrid_complexity(seq_len, d_model)
ratio = attn_flops / hybrid_flops
print(f"{seq_len:<15} {attn_time*1000:<20.4f} {hybrid_time*1000:<20.4f} {ratio:<15.2f}")Output:
Sequence Length Attention (ms) Hybrid (ms) FLOPs Ratio
----------------------------------------------------------------------
512 27.1888 20.0870 1.00
1024 4.7851 27.0247 1.99
2048 23.4721 46.5970 3.98
4096 98.4409 88.0020 7.97
8192 475.9641 170.8679 15.94Simulasi ini memperlihatkan secara konkret bagaimana arsitektur hybrid mengurangi kompleksitas komputasi seiring bertambahnya panjang sekuens. Perhatikan bahwa pada sekuens pendek, perbedaan tidak terlalu signifikan. Namun, ketika panjang sekuens membesar, arsitektur hybrid menunjukkan efisiensi yang jauh lebih baik.
Delta Net — Selective State Space dengan Delta Rule
Delta Net, yang dikembangkan oleh Shanghai AI Lab, membawa pendekatan yang paling berbeda di antara keempat arsitektur. Alih-alih menggabungkan SSM dengan attention secara terpisah, Delta Net menggunakan delta update rule sebagai mekanisme seleksi informasi dalam SSM itu sendiri.
Konsep intinya terinspirasi dari delta rule dalam jaringan saraf tradisional: hanya perubahan informasi yang signifikan yang disimpan dan diproses, sementara informasi yang redundan atau tidak berubah dibuang. Dalam konteks SSM, ini berarti state model hanya diperbarui ketika ada input baru yang membawa informasi bermakna — sangat berbeda dengan Mamba yang menggunakan learning-based selection.
Perbedaan fundamental ini membawa implikasi menarik. Delta Net menunjukkan training stability yang lebih baik dibandingkan Mamba pada dataset besar, karena mekanisme delta rule secara alami mencegah gradient explosion yang sering terjadi pada recurrent architectures. Namun, kompleksitas training Delta Net lebih tinggi karena membutuhkan komputasi delta untuk setiap langkah waktu.
Delta rule seperti sistem prioritas yang hanya menyimpan perubahan informasi signifikan dan membuang redundansi. Dalam praktiknya, pendekatan ini membuat Delta Net unggul pada task long-context retrieval dengan kualitas yang mendekati attention mechanism, tetapi dengan biaya komputasi yang jauh lebih rendah. Kekurangan utamanya adalah pada throughput inference yang sedikit lebih lambat dibandingkan Mamba karena overhead komputasi delta.
Benchmark dan Panduan Memilih Arsitektur Hybrid
Setelah memahami karakteristik masing-masing arsitektur, pertanyaan selanjutnya adalah kapan kita harus menggunakan yang mana. Tidak ada arsitektur yang unggul di semua aspek — setiap pilihan melibatkan trade-off antara kualitas output, kecepatan inference, dan efisiensi memori.
Berikut adalah tabel perbandingan komprehensif yang merangkum karakteristik keempat arsitektur:
!pip install pandas tabulate
import pandas as pd
data = {
"Arsitektur": ["Samba", "Hymba", "Griffin", "Delta Net"],
"Pengembang": ["Microsoft Research", "NVIDIA & NYU", "Google DeepMind", "Shanghai AI Lab"],
"Mekanisme Hybrid": ["Mamba + SWA", "SSM + GQA", "RG-LRU + Local Attn", "Delta Rule SSM"],
"Kompleksitas": ["O(n)", "O(n)", "O(n)", "O(n)"],
"Kualitas Retrieval": ["Tinggi", "Sangat Tinggi", "Sedang", "Tinggi"],
"Throughput": ["Sangat Cepat", "Cepat", "Sangat Cepat", "Cepat"],
"Memory Footprint": ["Rendah", "Sedang", "Rendah", "Sedang"],
"Konteks Maksimal": ["1M+ token", "128K token", "128K token", "512K token"],
"Skenario Ideal": [
"Long-context reasoning & retrieval",
"Task presisi tinggi & multi-modal",
"Deployment dengan resource terbatas",
"Training stabil pada dataset besar"
]
}
df = pd.DataFrame(data)
print(df.to_string(index=False))Output:
Arsitektur Pengembang Mekanisme Hybrid Kompleksitas Kualitas Retrieval Throughput Memory Footprint Konteks Maksimal Skenario Ideal
Samba Microsoft Research Mamba + SWA O(n) Tinggi Sangat Cepat Rendah 1M+ token Long-context reasoning & retrieval
Hymba NVIDIA & NYU SSM + GQA O(n) Sangat Tinggi Cepat Sedang 128K token Task presisi tinggi & multi-modal
Griffin Google DeepMind RG-LRU + Local Attn O(n) Sedang Sangat Cepat Rendah 128K token Deployment dengan resource terbatas
Delta Net Shanghai AI Lab Delta Rule SSM O(n) Tinggi Cepat Sedang 512K token Training stabil pada dataset besarBerdasarkan perbandingan di atas, kita dapat menarik beberapa kesimpulan praktis. Samba cocok untuk aplikasi yang membutuhkan konteks sangat panjang seperti document summarization atau conversational AI dengan riwayat ekstensif. Hymba unggul pada skenario yang membutuhkan presisi tinggi seperti code generation dan reasoning kompleks. Griffin adalah pilihan tepat untuk deployment dengan sumber daya terbatas karena throughput dan efisiensi memorinya yang sangat baik. Sementara Delta Net menawarkan keseimbangan terbaik antara kualitas dan stabilitas training untuk dataset besar.
Tren ke depan menunjukkan bahwa arsitektur hybrid akan menjadi standar baru dalam pengembangan LLM. Model-model masa depan kemungkinan akan mengadopsi variasi dari pendekatan hybrid ini, dengan inovasi pada mekanisme gating dan seleksi informasi yang semakin canggih.
Ingin memperdalam pemahaman tentang arsitektur model modern dan teknik implementasinya? Program Deep Learning Bootcamp di Rumah Coding membahas topik ini secara komprehensif, dari fundamental transformer sampai arsitektur hybrid terkini, dengan proyek praktis yang aplikatif.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.


