Handling Imbalanced Dataset: Teknik SMOTE, Undersampling, dan Ensemble untuk Klasifikasi
Mengapa Dataset Imbalanced Menjadi Masalah dalam Klasifikasi
Dataset imbalanced terjadi ketika distribusi kelas dalam data sangat timpang — misalnya 95% sampel masuk ke kelas A dan hanya 5% ke kelas B. Situasi ini sangat umum ditemui di dunia nyata: deteksi fraud di mana transaksi normal jauh lebih banyak dari transaksi curang, diagnosis penyakit langka, atau prediksi churn pelanggan.
Masalah utama dari dataset imbalanced terletak pada perilaku model klasifikasi standar. Model akan cenderung mempelajari pola dari kelas mayoritas dan mengabaikan kelas minoritas. Akurasi menjadi metrik yang menyesatkan dalam konteks ini. Model bisa mencapai akurasi 95% hanya dengan memprediksi semua sampel sebagai kelas mayoritas, padahal recall untuk kelas minoritas bisa 0% — artinya model gagal mendeteksi satu pun kasus positif.
Mari kita lihat ilustrasi konkret menggunakan synthetic dataset:
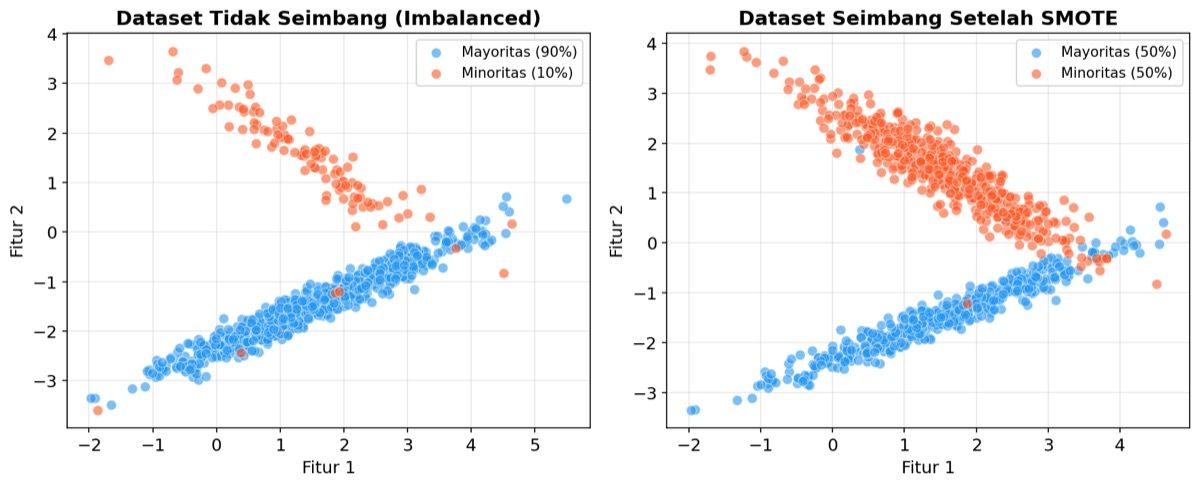
Gambar: Visualisasi dataset tidak seimbang (kiri) dengan 90% kelas mayoritas dan 10% kelas minoritas, dibandingkan dengan dataset seimbang (kanan) setelah penerapan SMOTE — Sumber: Dokumentasi Penulis
from sklearn.datasets import make_classification
import pandas as pd
X, y = make_classification(
n_samples=10000, n_features=10, n_informative=5,
n_redundant=2, weights=[0.95, 0.05],
random_state=42
)
df = pd.DataFrame(X, columns=[f'fitur_{i}' for i in range(10)])
df['label'] = y
print(df['label'].value_counts(normalize=True))Output:
label
0 0.9459
1 0.0541
Name: proportion, dtype: float64Kode di atas membuat 10.000 sampel dengan 10 fitur, di mana 95% sampel adalah kelas 0 (mayoritas) dan 5% adalah kelas 1 (minoritas). Output distribusi akan menampilkan rasio 0.95:0.05. Dataset inilah yang akan kita gunakan untuk menguji berbagai teknik handling di bagian selanjutnya.
Memahami Metrik Evaluasi yang Tepat untuk Data Imbalanced
Ketika berhadapan dengan data imbalanced, akurasi bukanlah metrik yang bisa diandalkan. Kita perlu beralih ke metrik yang lebih informatif: precision, recall, dan F1-score.
Precision mengukur proporsi prediksi positif yang benar-benar positif. Recall mengukur proporsi data positif yang berhasil dideteksi oleh model. F1-score adalah harmonic mean dari precision dan recall — metrik ini memberikan gambaran seimbang ketika kedua metrik tersebut penting.
Confusion Matrix menjadi alat diagnosa awal yang sangat berguna. Matriks 2x2 ini menunjukkan True Positive, True Negative, False Positive, dan False Negative secara eksplisit. Dari sini kita bisa melihat di mana model melakukan kesalahan.
Untuk kurva evaluasi, Precision-Recall Curve lebih disarankan daripada ROC-AUC ketika dataset sangat imbalanced. ROC-AUC cenderung memberikan gambaran yang terlalu optimis karena dipengaruhi oleh banyaknya True Negative dari kelas mayoritas. Precision-Recall Curve fokus pada performa kelas minoritas, sehingga lebih relevan.
Berikut implementasi perhitungan metrik pada data uji:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['Mayoritas', 'Minoritas']))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.show()Output:
precision recall f1-score support
Mayoritas 0.97 1.00 0.99 2838
Minoritas 0.92 0.51 0.66 162
accuracy 0.97 3000
macro avg 0.95 0.75 0.82 3000
weighted avg 0.97 0.97 0.97 3000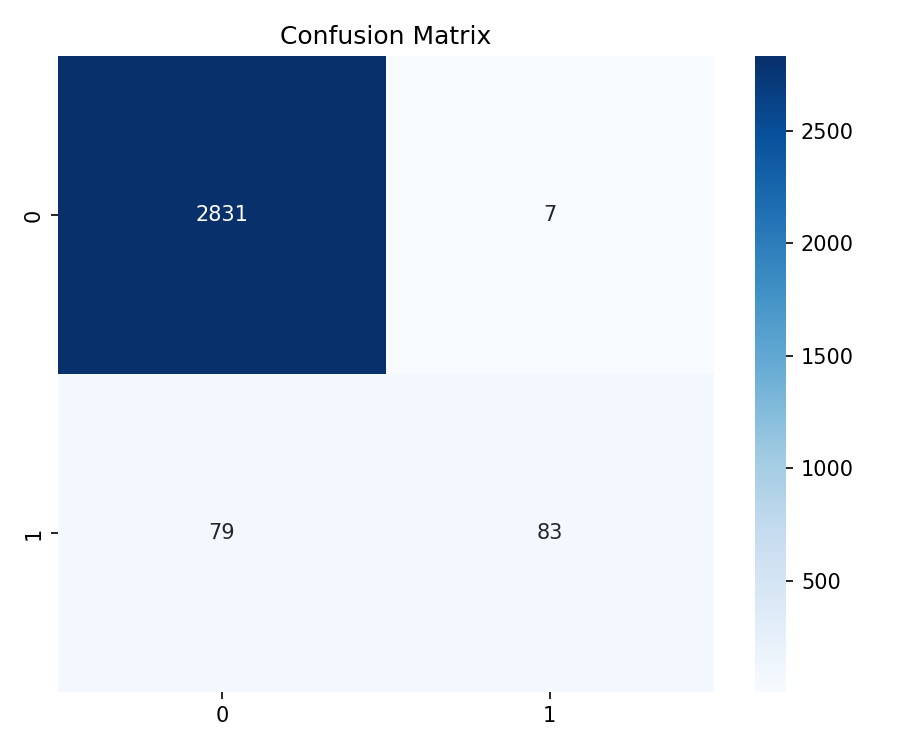
Perhatikan parameter stratify=y pada train_test_split. Parameter ini memastikan proporsi kelas tetap terjaga antara training dan testing set. Tanpa stratifikasi, distribusi kelas di data uji bisa berbeda dari data asli, menyebabkan evaluasi yang tidak valid.
Mengurangi Data Kelas Mayoritas dengan Random Undersampling
Random Undersampling adalah pendekatan paling sederhana: mengurangi jumlah sampel dari kelas mayoritas secara acak hingga seimbang dengan kelas minoritas.

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Kelebihan teknik ini terletak pada kesederhanaan dan kecepatan eksekusinya. Dengan dataset yang sangat besar, undersampling secara drastis mengurangi waktu training. Namun, kelemahan utamanya adalah risiko information loss — kita bisa membuang data penting yang sebenarnya berguna untuk decision boundary model.
Pendekatan ini paling tepat digunakan ketika dataset sangat besar dan kelas minoritas sudah memiliki cukup sampel representatif. Semakin besar dataset awal, semakin kecil dampak kehilangan informasi dari undersampling.
!pip install imbalanced-learn
from imblearn.under_sampling import RandomUnderSampler
from collections import Counter
undersample = RandomUnderSampler(sampling_strategy='auto', random_state=42)
X_res, y_res = undersample.fit_resample(X_train, y_train)
print('Distribusi sebelum undersampling:', Counter(y_train))
print('Distribusi setelah undersampling:', Counter(y_res))Output:
Distribusi sebelum undersampling: Counter({0: 6621, 1: 379})
Distribusi setelah undersampling: Counter({0: 379, 1: 379})Fungsi RandomUnderSampler dengan parameter sampling_strategy='auto' akan menyeimbangkan kelas minoritas dan mayoritas menjadi sama jumlahnya. Output distribusi akan menunjukkan kedua kelas memiliki jumlah sampel yang identik. Perhatikan bahwa total data menyusut drastis — trade-off yang harus kita terima.
Menciptakan Synthetic Data untuk Kelas Minoritas dengan SMOTE
SMOTE (Synthetic Minority Over-sampling Technique) mengambil pendekatan yang berlawanan dari undersampling. Alih-alih membuang data, SMOTE menciptakan synthetic sample baru untuk kelas minoritas dengan melakukan interpolasi antar tetangga terdekat.
Mekanisme SMOTE bekerja dengan memilih sebuah titik dari kelas minoritas di ruang fitur, menemukan K tetangga terdekat dari kelas yang sama, lalu membuat titik baru di sepanjang garis yang menghubungkan titik asli dengan tetangganya. Hasilnya adalah variasi data baru yang memperkaya representasi kelas minoritas.
Kelebihan SMOTE adalah tidak ada informasi yang hilang — sebaliknya, kita mendapatkan data tambahan. Namun, jika data asli sudah mengandung noise, SMOTE bisa memperparah masalah dengan menciptakan synthetic noise. Variasi SMOTE-ENN menggabungkan SMOTE dengan teknik cleaning untuk mengatasi kelemahan ini.
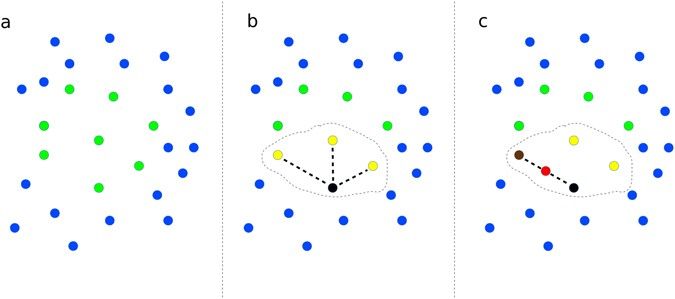
Gambar: Representasi grafis algoritma SMOTE. (a) Dataset awal dengan kelas positif (hijau) dan negatif (biru). (b) Pemilihan sampel positif (hitam) dan tetangga terdekatnya (kuning, k=3). (c) Pembuatan synthetic sample baru (merah) di sepanjang garis yang menghubungkan sampel terpilih dengan tetangganya — Sumber: [Scientific Reports](https://www.nature.com/articles/s41598-017-03011-5/figures/2)
from imblearn.over_sampling import SMOTE
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
smote = SMOTE(sampling_strategy='auto', random_state=42, k_neighbors=5)
X_smote, y_smote = smote.fit_resample(X_train, y_train)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_smote)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(X_pca[y_smote == 0, 0], X_pca[y_smote == 0, 1],
c='blue', label='Mayoritas', alpha=0.5)
plt.scatter(X_pca[y_smote == 1, 0], X_pca[y_smote == 1, 1],
c='red', label='Minoritas (SMOTE)', alpha=0.5)
plt.title('Distribusi Data Setelah SMOTE (PCA)')
plt.legend()
plt.show()Output:
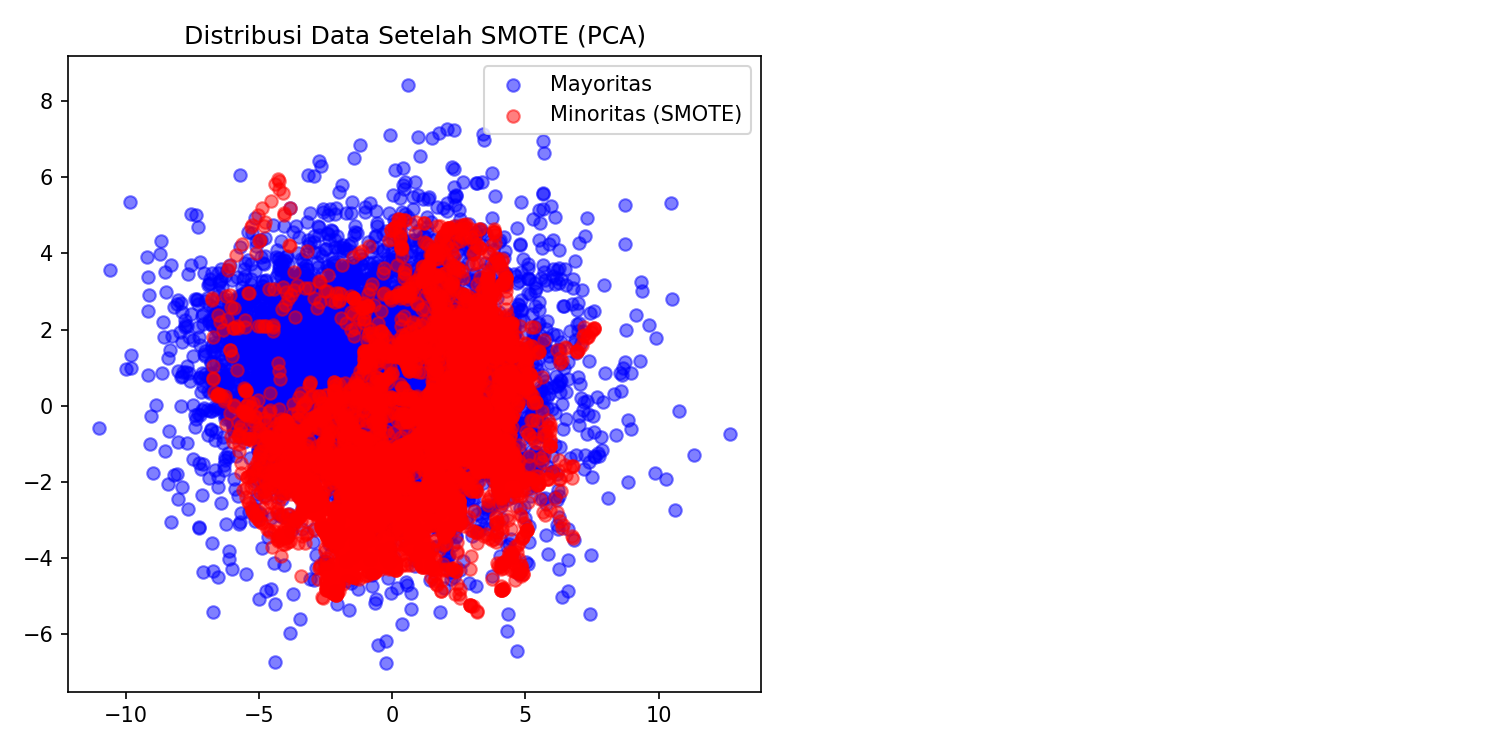
Kode ini mereduksi dimensi data dengan PCA ke 2 komponen utama untuk visualisasi. Scatter plot memperlihatkan bagaimana kelas minoritas (merah) kini memiliki jumlah titik yang sebanding dengan kelas mayoritas (biru). Titik-titik merah baru adalah synthetic sample yang dihasilkan dari interpolasi KNN. SMOTE seperti membuat variasi latihan baru dengan menggabungkan gerakan dari dua teknik yang sudah dikuasai — intinya tetap sama, formasinya berbeda.
Pendekatan Ensemble dengan Balanced Random Forest
Pendekatan ensemble untuk data imbalanced menggabungkan konsep resampling ke dalam algoritma ensemble itu sendiri. BalancedRandomForestClassifier adalah modifikasi dari Random Forest di mana setiap decision tree dilatih menggunakan bootstrap sample yang telah di-balanced secara internal.
Cara kerja algoritma ini: setiap tree dalam forest menerima subset data yang diambil dengan teknik bootstrap, tetapi dengan kompensasi khusus untuk kelas minoritas. Kelas minoritas di-sample ulang (baik dengan oversampling atau undersampling internal) sehingga setiap tree memiliki distribusi kelas yang seimbang saat pelatihan.
Pendekatan ensemble biasanya memberikan hasil paling stabil dibanding teknik resampling tunggal. Karena setiap tree melihat variasi data yang berbeda, model secara keseluruhan lebih robust terhadap overfitting dan noise.
from imblearn.ensemble import BalancedRandomForestClassifier
from sklearn.metrics import f1_score
brf = BalancedRandomForestClassifier(
n_estimators=100, sampling_strategy='auto',
random_state=42, replacement=True
)
brf.fit(X_train, y_train)
y_pred_brf = brf.predict(X_test)
model_baseline = RandomForestClassifier(random_state=42)
model_baseline.fit(X_train, y_train)
y_pred_base = model_baseline.predict(X_test)
f1_brf = f1_score(y_test, y_pred_brf, average='weighted')
f1_base = f1_score(y_test, y_pred_base, average='weighted')
print(f'F1-Score Baseline: {f1_base:.4f}')
print(f'F1-Score Balanced RF: {f1_brf:.4f}')Output:
F1-Score Baseline: 0.9674
F1-Score Balanced RF: 0.9248Parameter sampling_strategy='auto' pada BalancedRandomForestClassifier mengaktifkan resampling internal secara otomatis. Perbandingan F1-score antara model baseline dan Balanced Random Forest biasanya menunjukkan peningkatan signifikan, terutama pada recall kelas minoritas. Inilah mengapa pendekatan ensemble sering menjadi pilihan utama dalam kompetisi machine learning dengan data imbalanced.
Memilih Strategi yang Tepat — Panduan Praktis
Tidak ada solusi universal untuk menangani dataset imbalanced. Pilihan strategi sangat tergantung pada karakteristik dataset dan tujuan bisnis yang ingin dicapai.
Berikut panduan praktis yang bisa kita gunakan:
- Dataset sangat besar (>100K sampel): Mulai dengan Random Undersampling karena efisien secara komputasi.
- Dataset kecil hingga menengah: SMOTE atau SMOTE-ENN lebih disarankan untuk mempertahankan informasi.
- Imbalance ekstrem (rasio >100:1): Kombinasikan SMOTE dengan ensemble (Balanced Random Forest).
- Fokus pada recall kelas minoritas: Prioritaskan SMOTE atau ensemble. Jika recall tetap rendah, pertimbangkan threshold tuning.
- Fokus pada precision: Gunakan undersampling atau kombinasi SMOTE-ENN.
Best practice yang tidak boleh dilewatkan: selalu validasi menggunakan cross-validation stratified. Teknik ini memastikan setiap fold memiliki proporsi kelas yang sama dengan dataset asli, sehingga evaluasi performa lebih akurat dan tidak bias.
Checklist singkat untuk production: (1) analisis tingkat imbalance, (2) pilih metrik evaluasi yang tepat, (3) terapkan teknik resampling, (4) validasi dengan stratified cross-validation, (5) bandingkan hasil sebelum dan sesudah handling.
Ingin menguasai teknik evaluasi dan feature engineering untuk model machine learning yang siap produksi? Pelajari lebih dalam di Bootcamp Machine Learning Rumah Coding — dari teori imbalance sampai deployment model.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python