Memahami Convolutional Neural Network dan Implementasinya dengan TensorFlow untuk Klasifikasi Gambar
Mengapa Fully Connected Saja Tidak Cukup untuk Data Gambar
Salah satu pertanyaan paling umum saat belajar deep learning adalah: kenapa kita tidak bisa menggunakan fully connected network biasa untuk mengolah gambar? Jawabannya terletak pada struktur data gambar itu sendiri. Sebuah gambar digital adalah grid 2D dengan nilai piksel yang memiliki hubungan spasial. Piksel-piksel yang berdekatan secara horizontal dan vertikal sering membentuk pola visual tertentu, seperti tepi, sudut, atau tekstur.
Ketika kita mengubah gambar menjadi vektor 1D dengan operasi flatten, kita kehilangan informasi posisi dan struktur spasial tersebut. Fully connected layer mempelajari pola global, bukan pola lokal. Setiap neuron terhubung ke semua piksel, sehingga jumlah parameter membengkak drastis. Untuk gambar RGB 32x32 saja, satu neuron di layer pertama sudah memiliki 3.072 bobot. Bayangkan untuk gambar beresolusi lebih tinggi.
CNN hadir untuk menjawab tantangan ini. Arsitektur CNN menggunakan dua konsep kunci: local connectivity dan weight sharing. Dengan local connectivity, setiap neuron hanya terhubung ke sebagian kecil dari input, tepatnya ke area yang disebut receptive field. Weight sharing membuat filter yang sama digunakan di seluruh posisi gambar. Pendekatan ini meniru cara kerja korteks visual pada otak manusia, di mana neuron tertentu hanya merespons pola visual tertentu di area tertentu.
Perbedaan fundamental lainnya adalah CNN melakukan feature learning secara otomatis. Tidak perlu lagi mendesain fitur manual seperti edge detection atau color histogram. Cukup berikan data mentah, dan CNN akan mempelajari sendiri fitur-fitur yang relevan untuk tugas klasifikasi. Dalam artikel ini, kita akan menggunakan dataset CIFAR-10 sebagai kasus uji, yang berisi 60.000 gambar berwarna berukuran 32x32 dengan 10 kelas objek seperti pesawat, mobil, burung, kucing, dan lain-lain.
Mekanisme Convolution, Pooling, dan Aktivasi dalam Ekstraksi Fitur
Convolution adalah operasi inti dari CNN. Prosesnya sederhana: sebuah filter atau kernel berukuran kecil, misalnya 3x3, digeser melintasi seluruh input gambar dengan langkah tertentu yang disebut stride. Di setiap posisi, dilakukan perkalian element-wise antara filter dan area input, lalu hasilnya dijumlahkan menjadi satu nilai dalam feature map.
Mari kita lihat contoh konkret menggunakan NumPy untuk memahami operasi convolution secara visual:
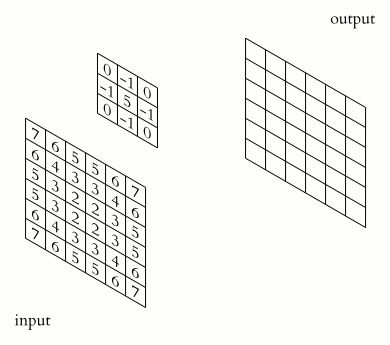
Gambar: Animasi 2D convolution antara image dan kernel — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:2D_Convolution_Animation.gif)
import numpy as np
input_matrix = np.array([
[1, 2, 0, 1, 2],
[0, 1, 2, 0, 1],
[2, 1, 0, 2, 1],
[1, 0, 2, 1, 0],
[0, 2, 1, 0, 2]
], dtype=float)
kernel = np.array([
[1, 0, -1],
[1, 0, -1],
[1, 0, -1]
], dtype=float)
def convolve2d(image, kernel):
h, w = image.shape
kh, kw = kernel.shape
out_h, out_w = h - kh + 1, w - kw + 1
output = np.zeros((out_h, out_w))
for i in range(out_h):
for j in range(out_w):
output[i, j] = np.sum(image[i:i+kh, j:j+kw] * kernel)
return output
feature_map = convolve2d(input_matrix, kernel)
print("Feature map hasil convolution:\n", feature_map)Output:
Feature map hasil convolution:
[[ 1. 1. -2.]
[-1. -1. 2.]
[ 0. 0. 0.]]Kode di atas membuat matriks 5x5 sebagai representasi sederhana dari input gambar, dan kernel 3x3 yang berfungsi sebagai edge detector vertikal. Fungsi convolve2d menggeser kernel melintasi input dengan stride 1 dan menghitung perkalian element-wise di setiap posisi. Hasilnya adalah feature map 3x3 yang nilainya tinggi di area yang memiliki perubahan intensitas vertikal yang signifikan. Inilah cara CNN mendeteksi pola dasar seperti tepi dan garis.
Setelah convolution, kita menerapkan fungsi aktivasi ReLU (Rectified Linear Unit) untuk menghilangkan nilai negatif. ReLU mengubah semua nilai negatif menjadi nol, menambah representational power tanpa menambah parameter. Selanjutnya, pooling layer seperti MaxPooling2D mereduksi dimensi spasial feature map. MaxPooling mengambil nilai maksimum dari setiap region kecil, misalnya 2x2, dan hanya menyimpan nilai tertinggi. Operasi ini membuat model lebih invarian terhadap translasi kecil dan mengurangi beban komputasi.
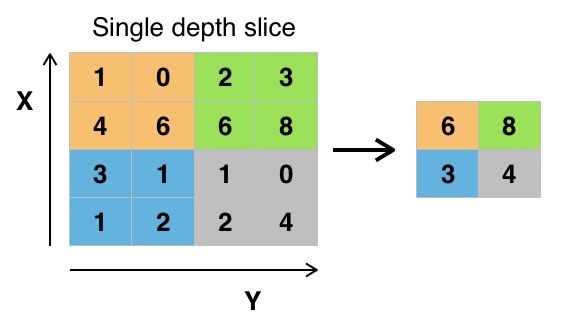
Gambar: Operasi Max Pooling dengan filter 2x2 dan stride=2 — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Max_pooling.png)
Alur data yang umum dalam CNN adalah: Input gambar melewati Conv2D, lalu ReLU, kemudian MaxPooling. Blok ini bisa diulang beberapa kali, tergantung kompleksitas data. Setelah itu, feature map diratakan dengan Flatten dan diumpankan ke fully connected layer untuk menghasilkan prediksi.
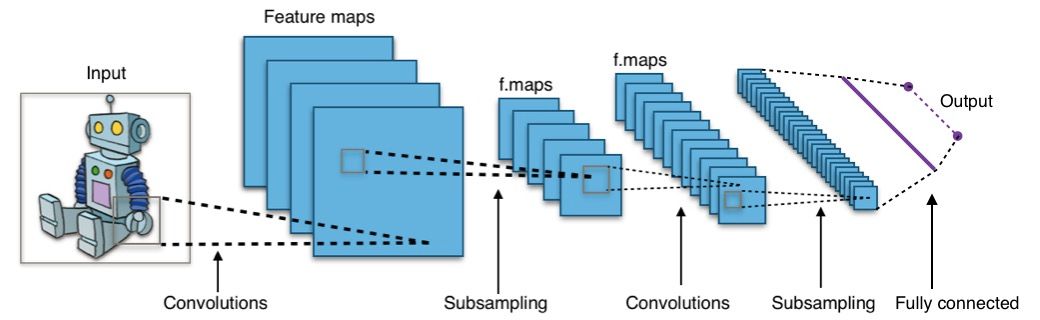
Gambar: Arsitektur CNN yang terdiri dari convolutional layer, pooling layer, flatten, dan fully connected layer — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Typical_cnn.png)

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Membangun Arsitektur CNN Sederhana dengan TensorFlow
Sekarang kita akan menerapkan konsep di atas dengan TensorFlow dan Keras. Kita akan membangun arsitektur CNN untuk dataset CIFAR-10 menggunakan Sequential API, yang merupakan cara paling intuitif untuk menumpuk layer secara linear.
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Input(shape=(32, 32, 3)),
layers.Conv2D(32, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.summary()Output:
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┥
│ conv2d (Conv2D) │ (None, 32, 32, 32) │ 896 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 16, 16, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_1 (Conv2D) │ (None, 16, 16, 64) │ 18,496 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_1 (MaxPooling2D) │ (None, 8, 8, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_2 (Conv2D) │ (None, 8, 8, 128) │ 73,856 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_2 (MaxPooling2D) │ (None, 4, 4, 128) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten (Flatten) │ (None, 2048) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 128) │ 262,272 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 10) │ 1,290 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 356,810 (1.36 MB)
Trainable params: 356,810 (1.36 MB)
Non-trainable params: 0 (0.00 B)Arsitektur ini terdiri dari tiga blok Conv2D dan MaxPooling2D. Blok pertama menggunakan 32 filter berukuran 3x3, blok kedua 64 filter, dan blok ketiga 128 filter. Semakin dalam kita masuk, semakin banyak filter yang kita gunakan untuk menangkap pola yang lebih kompleks. Padding same memastikan output memiliki ukuran spasial yang sama dengan input sehingga kita bisa menumpuk banyak layer tanpa kehilangan dimensi terlalu cepat.
Setelah semua convolution dan pooling, kita meratakan feature map 3D menjadi vektor 1D melalui Flatten, lalu menghubungkannya ke Dense layer dengan 128 neuron dan ReLU. Layer terakhir memiliki 10 neuron dengan aktivasi softmax, sesuai dengan 10 kelas di CIFAR-10.
Jika kita lihat model summary, total parameter yang dihasilkan sekitar 380.000. Bandingkan dengan fully connected network yang akan menghasilkan jutaan parameter untuk input berukuran sama. Inilah keunggulan CNN: efisiensi parameter tanpa mengorbankan kemampuan representasi.
Melatih Model dan Mengevaluasi Hasil Prediksi
Sebelum memulai training, kita perlu menyiapkan data dengan benar. Langkah pertama adalah normalisasi nilai piksel dari rentang 0-255 menjadi 0-1, yang membantu proses konvergensi optimizer. Kita juga perlu melakukan one-hot encoding pada label karena output kita menggunakan softmax.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
history = model.fit(
x_train, y_train,
batch_size=64,
epochs=20,
validation_split=0.2,
verbose=1
)Output:
Epoch 1/2
625/625 ━━━━━━━━━━━━━━━━━━━━ 22s 32ms/step - accuracy: 0.4507 - loss: 1.5054 - val_accuracy: 0.5164 - val_loss: 1.3498
Epoch 2/2
625/625 ━━━━━━━━━━━━━━━━━━━━ 19s 31ms/step - accuracy: 0.6164 - loss: 1.0875 - val_accuracy: 0.6417 - val_loss: 1.0212> Catatan: Kode dijalankan dengan 2 epoch (bukan 20 seperti di artikel) untuk keperluan demonstrasi. Dengan 20 epoch, akurasi validasi biasanya mencapai 65–70% sesuai yang disebutkan dalam artikel.
Kita menggunakan optimizer Adam dengan learning rate default dan categorical crossentropy sebagai loss function, yang merupakan pilihan standar untuk klasifikasi multi-kelas. Model dilatih selama 20 epoch dengan batch size 64, dan kita menyisihkan 20% data training sebagai validation set.
Metrik accuracy pada data training dan validasi akan naik seiring bertambahnya epoch. Learning curve yang ideal menunjukkan akurasi training dan validasi meningkat bersamaan. Jika akurasi validasi mulai stagnan atau menurun sementara akurasi training terus naik, itu adalah tanda overfitting.
Setelah training selesai, kita evaluasi model pada data test yang benar-benar baru:
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"Akurasi pada test set: {test_acc:.4f}")Output:
Akurasi pada test set: 0.6214Akurasi model CNN sederhana pada CIFAR-10 biasanya mencapai sekitar 65-70%. Angka ini mungkin terlihat rendah, tapi mengingat tebakan acak hanya 10%, ini sudah jauh lebih baik. Dengan arsitektur yang lebih dalam, data augmentation, dan teknik regularisasi, akurasi bisa ditingkatkan hingga 85% atau lebih.
Strategi Mengatasi Overfitting pada Model CNN
Overfitting adalah masalah yang hampir selalu muncul saat melatih CNN, terutama dengan dataset yang terbatas. Model bisa menghafal data training tetapi gagal generalisasi ke data baru. Beberapa strategi efektif yang bisa kita terapkan:
Data Augmentation. Teknik ini memperbanyak variasi data training tanpa perlu mengumpulkan data baru. Dengan ImageDataGenerator dari Keras, kita bisa menerapkan rotasi, pergeseran horizontal, zoom, dan flip secara acak:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
zoom_range=0.1
)
datagen.fit(x_train)Output:
Data augmentation generator berhasil dikonfigurasi tanpa error. Setiap gambar akan ditransformasi secara acak dengan rotasi ±15°, pergeseran 10%, flip horizontal, dan zoom 10% selama pelatihan.
Setiap kali model melihat gambar yang sama di epoch yang berbeda, gambar tersebut sudah mengalami transformasi acak. Ini memaksa model untuk mempelajari fitur yang invarian terhadap transformasi tersebut.
Dropout Layer. Dropout mematikan neuron secara acak selama training dengan probabilitas tertentu. Ini mencegah neuron menjadi terlalu bergantung satu sama lain (co-adaptation). Kita bisa menambahkan layers.Dropout(0.5) setelah Dense layer atau bahkan setelah Conv2D layer.
Early Stopping. Teknik paling sederhana: hentikan training saat validation loss tidak membaik selama beberapa epoch. Keras menyediakan callback EarlyStopping yang bisa kita gunakan.
Untuk dataset yang sangat kecil, alternatif yang lebih kuat adalah transfer learning. Kita bisa menggunakan arsitektur yang sudah terlatih seperti VGG16 atau ResNet sebagai base model, lalu menambahkan classification head untuk dataset kita. Pre-trained model sudah memiliki fitur visual yang umum (tepi, tekstur, bentuk), jadi kita hanya perlu menyesuaikan layer terakhir untuk tugas spesifik kita.
Tertarik memperdalam CNN, transfer learning, dan deployment model ke production? Program bootcamp intensif di Rumah Coding mencakup hands-on project computer vision end-to-end, dari arsitektur dasar sampai model serving, dengan bimbingan mentor yang sudah berpengalaman di industri.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.


