Memahami Generative Adversarial Network (GAN): Teori dan Implementasi dengan TensorFlow

Konsep Dasar GAN dan Arsitektur Generator-Discriminator
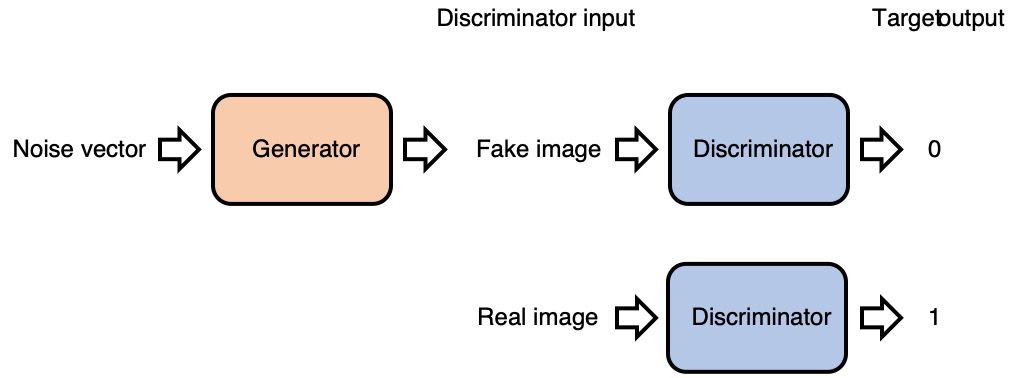
Generative Adversarial Network atau GAN adalah arsitektur deep learning yang diperkenalkan oleh Ian Goodfellow pada tahun 2014. GAN terdiri dari dua jaringan saraf yang saling bersaing dalam sebuah permainan zero-sum: Generator dan Discriminator. Generator bertugas menciptakan data sintetis yang realistis dari noise acak, sementara Discriminator bertugas membedakan antara data asli dan data palsu.
Bayangkan seperti seorang seniman pemula yang belajar memalsukan lukisan dan seorang kritikus yang semakin ahli mendeteksi palsuan — semakin baik seniman memalsukan, semakin tajam pula kemampuan kritikus. Keduanya saling mendorong untuk menjadi lebih baik.
Generator menerima input berupa vektor noise dari latent space, biasanya distribusi Gaussian atau uniform, dan mengubahnya menjadi data dengan dimensi yang sama dengan data asli. Discriminator bekerja sebagai classifier biner yang menerima input data (baik asli maupun palsu) dan mengeluarkan probabilitas antara 0 (palsu) dan 1 (asli).
Proses adversarial training inilah yang membuat GAN unik. Kedua jaringan dilatih secara bergantian dalam setiap iterasi. Generator tidak pernah melihat data asli secara langsung — ia hanya menerima sinyal dari Discriminator melalui loss function. Sebaliknya, Discriminator terus belajar dari data asli dan umpan balik dari Generator.
Gambar: Diagram arsitektur Generative Adversarial Network — Sumber: [Wikimedia Commons (Mtanti, CC BY-SA 4.0)](https://commons.wikimedia.org/wiki/File:Generative_Adversarial_Network_illustration.svg)
Mekanisme Adversarial Training dan Loss Function
Inti dari pelatihan GAN adalah konsep minimax game. Generator mencoba meminimalkan kemampuannya untuk dikenali sebagai palsu, sementara Discriminator mencoba memaksimalkan kemampuannya mendeteksi kepalsuan. Secara matematis, ini dirumuskan dengan value function V(D, G).
Loss function yang digunakan adalah Binary Cross-Entropy, di mana Discriminator menghitung loss dari prediksinya terhadap data real dan fake, sementara Generator menghitung loss berdasarkan seberapa sering Discriminator tertipu. Keseimbangan ideal terjadi ketika Discriminator tidak bisa membedakan data asli dan palsu — inilah yang disebut Nash Equilibrium.
Tantangan terbesar dalam training GAN adalah mencapai stabilitas. Mode collapse terjadi ketika Generator hanya memproduksi satu jenis output yang berhasil menipu Discriminator. Vanishing gradient muncul ketika Discriminator terlalu baik sehingga Generator tidak menerima gradien yang cukup untuk belajar.
import tensorflow as tf
import numpy as np
# Loss function untuk Discriminator
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
return real_loss + fake_loss
def generator_loss(fake_output):
# Generator ingin Discriminator mengira outputnya real
return cross_entropy(tf.ones_like(fake_output), fake_output)
# Optimizer dengan learning rate yang lebih rendah untuk stabilitas
generator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Kita menggunakan BinaryCrossentropy dengan from_logits=True karena output layer tidak menggunakan aktivasi sigmoid. Ini memberikan stabilitas numerik yang lebih baik selama training. Learning rate yang lebih rendah (0.0002) dan momentum beta_1 = 0.5 adalah konfigurasi standar yang terbukti bekerja baik untuk GAN.
Implementasi Generator dan Discriminator dengan TensorFlow
Generator dan Discriminator dibangun menggunakan Keras Sequential API. Generator mengubah vektor noise 1D menjadi data 2D (gambar), sementara Discriminator menerima gambar dan mengeluarkan satu nilai probabilitas.
Generator menggunakan arsitektur dense layer yang diikuti batch normalization dan activation function ReLU, kemudian di-reshape menjadi dimensi gambar. Batch normalization sangat penting untuk stabilitas training karena mencegah internal covariate shift. Discriminator menggunakan Leaky ReLU dengan slope 0.2 untuk menghindari neuron mati, ditambah Dropout untuk regularisasi.
import tensorflow as tf
def make_generator_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(7*7*256, use_bias=False, input_shape=(100,)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Reshape((7, 7, 256)),
tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
])
return model
def make_discriminator_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=(28, 28, 1)),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1)
])
return model
generator = make_generator_model()
discriminator = make_discriminator_model()
print("=== Generator Model ===")
generator.summary()
print("\n=== Discriminator Model ===")
discriminator.summary()Perhatikan penggunaan Conv2DTranspose pada Generator — ini adalah convolution terbalik yang melakukan upsampling secara learnable. Setiap layer meningkatkan resolusi spasial sambil mengurangi kedalaman fitur. Pada Discriminator, kita menggunakan convolution standar dengan stride 2 yang berfungsi untuk downsampling, menggantikan peran pooling layer.
Aktivasi tanh pada output Generator memetakan nilai ke rentang [-1, 1], yang sesuai dengan preprocessing data input (kita akan menormalisasi data ke rentang yang sama). Leaky ReLU dengan alpha 0.2 pada Discriminator memberikan slope negatif kecil sehingga neuron tetap belajar bahkan saat input negatif.
Melatih GAN pada Dataset Sederhana
Kita akan menggunakan dataset Fashion-MNIST yang berisi gambar pakaian skala abu-abu berukuran 28x28. Dataset ini lebih menantang daripada MNIST biasa dan menghasilkan visualisasi yang lebih menarik saat GAN mulai belajar.
Proses training dilakukan secara alternating: pertama kita latih Discriminator dengan batch data real dan batch data palsu dari Generator, kemudian kita latih Generator dengan mengecoh Discriminator. Kedua jaringan dibekukan secara bergantian menggunakan tf.GradientTape.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Load dan normalisasi dataset
(train_images, _), (_, _) = tf.keras.datasets.fashion_mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalisasi ke [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# Fungsi untuk menghasilkan noise latent
def generate_noise(batch_size, noise_dim=100):
return tf.random.normal([batch_size, noise_dim])
# Training step
@tf.function
def train_step(images):
noise = generate_noise(BATCH_SIZE)
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss
# Fungsi untuk menyimpan sample gambar
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 0.5 + 0.5, cmap='gray')
plt.axis('off')
plt.savefig(f'public/images/blog/gan-sample-epoch-{epoch:04d}.png')
plt.close()
# Training loop
EPOCHS = 50
noise_seed = generate_noise(16) # Seed tetap untuk visualisasi progres
gen_losses = []
disc_losses = []
for epoch in range(EPOCHS):
epoch_gen_loss = []
epoch_disc_loss = []
for image_batch in train_dataset:
gen_loss, disc_loss = train_step(image_batch)
epoch_gen_loss.append(gen_loss)
epoch_disc_loss.append(disc_loss)
gen_losses.append(np.mean(epoch_gen_loss))
disc_losses.append(np.mean(epoch_disc_loss))
if (epoch + 1) % 10 == 0:
generate_and_save_images(generator, epoch + 1, noise_seed)
print(f'Epoch {epoch + 1}: Generator Loss = {gen_losses[-1]:.4f}, Discriminator Loss = {disc_losses[-1]:.4f}')Pada setiap epoch, Discriminator melihat data asli dan data palsu. Loss Generator dan Discriminator bergerak secara berlawanan — saat Generator membaik, loss Discriminator cenderung naik, dan sebaliknya. Grafik loss yang stabil dengan kedua nilai berosilasi di sekitar angka tertentu menandakan training yang sehat.
Sample gambar disimpan setiap 10 epoch menggunakan seed noise yang sama. Ini memungkinkan kita melihat progres kualitas gambar yang dihasilkan dari waktu ke waktu. Pada epoch awal, gambar akan tampak seperti noise acak, tetapi secara bertahap akan membentuk pola yang menyerupai item Fashion-MNIST.
Evaluasi Hasil dan Best Practices Training GAN
Mengevaluasi kualitas GAN bukanlah tugas yang mudah karena tidak ada metrik objektif tunggal. Inception Score (IS) dan Fréchet Inception Distance (FID) adalah dua metrik yang umum digunakan, keduanya membandingkan distribusi fitur antara data asli dan data sintetis menggunakan model pre-trained Inception.
Beberapa teknik telah dikembangkan untuk menstabilkan training GAN. Label smoothing mengganti label 1 (real) dengan nilai sedikit lebih rendah seperti 0.9 untuk mencegah Discriminator menjadi terlalu percaya diri. Feature matching memodifikasi loss Generator agar mencocokkan fitur internal Discriminator antara data real dan fake.
# Teknik Label Smoothing untuk Discriminator
def discriminator_loss_smoothed(real_output, fake_output, smooth_factor=0.1):
real_labels = tf.ones_like(real_output) * (1.0 - smooth_factor)
fake_labels = tf.zeros_like(fake_output)
real_loss = cross_entropy(real_labels, real_output)
fake_loss = cross_entropy(fake_labels, fake_output)
return real_loss + fake_lossMode collapse dapat dideteksi ketika sample yang dihasilkan terlihat seragam atau hanya mencakup sebagian kecil variasi data. Solusi umum termasuk meningkatkan ukuran latent space, menambahkan noise pada input Discriminator, atau menggunakan arsitektur yang lebih stabil seperti Wasserstein GAN (WGAN) dengan gradient penalty.
Hyperparameter yang paling sensitif pada GAN adalah learning rate dan batch size. Learning rate yang terlalu tinggi menyebabkan osilasi divergen, sementara batch size yang terlalu kecil memberikan estimasi gradien yang terlalu bising. Rasio training antara Discriminator dan Generator juga penting — beberapa implementasi melatih Discriminator lebih sering (setiap 5 langkah) dibandingkan Generator.
Ingin mendalami arsitektur GAN yang lebih canggih? Bootcamp Deep Learning di Rumah Coding mencakup DCGAN, StyleGAN, dan Conditional GAN dengan studi kasus nyata. Daftar sekarang untuk mendapatkan bimbingan langsung dari praktisi industri.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.


