Mengimplementasikan Cross-Validation yang Benar: Strategi Split untuk Data Time Series dan Imbalanced

Mengapa Cross-Validation Standar Tidak Selalu Cocok
Cross-validation adalah fondasi evaluasi model yang andal. Namun, tidak semua data bisa diperlakukan sama. KFold standar dari scikit-learn mengasumsikan bahwa data bersifat _independent and identically distributed_ (i.i.d.) — setiap sampel independen satu sama lain dan berasal dari distribusi yang sama. Asumsi ini seringkali tidak berlaku di dunia nyata.
Pada data time series, urutan temporal sangat penting. Jika kita menggunakan KFold biasa yang mengacak data, informasi dari masa depan bisa bocor ke dalam training set. Bayangkan kita melatih model untuk memprediksi harga saham besok menggunakan data dari bulan depan — hasil evaluasi akan terlihat sempurna, tetapi model akan gagal total di produksi.
Masalah serupa muncul pada _imbalanced dataset_. Ketika satu kelas hanya mewakili 5% dari total data, KFold biasa bisa menghasilkan sebuah fold yang tidak memiliki satu pun sampel kelas minoritas. Model akan mencapai akurasi tinggi hanya dengan memprediksi kelas mayoritas, dan metrik evaluasi menjadi menyesatkan.
Mari kita lihat bagaimana kedua masalah ini memanifestasi dalam kode:
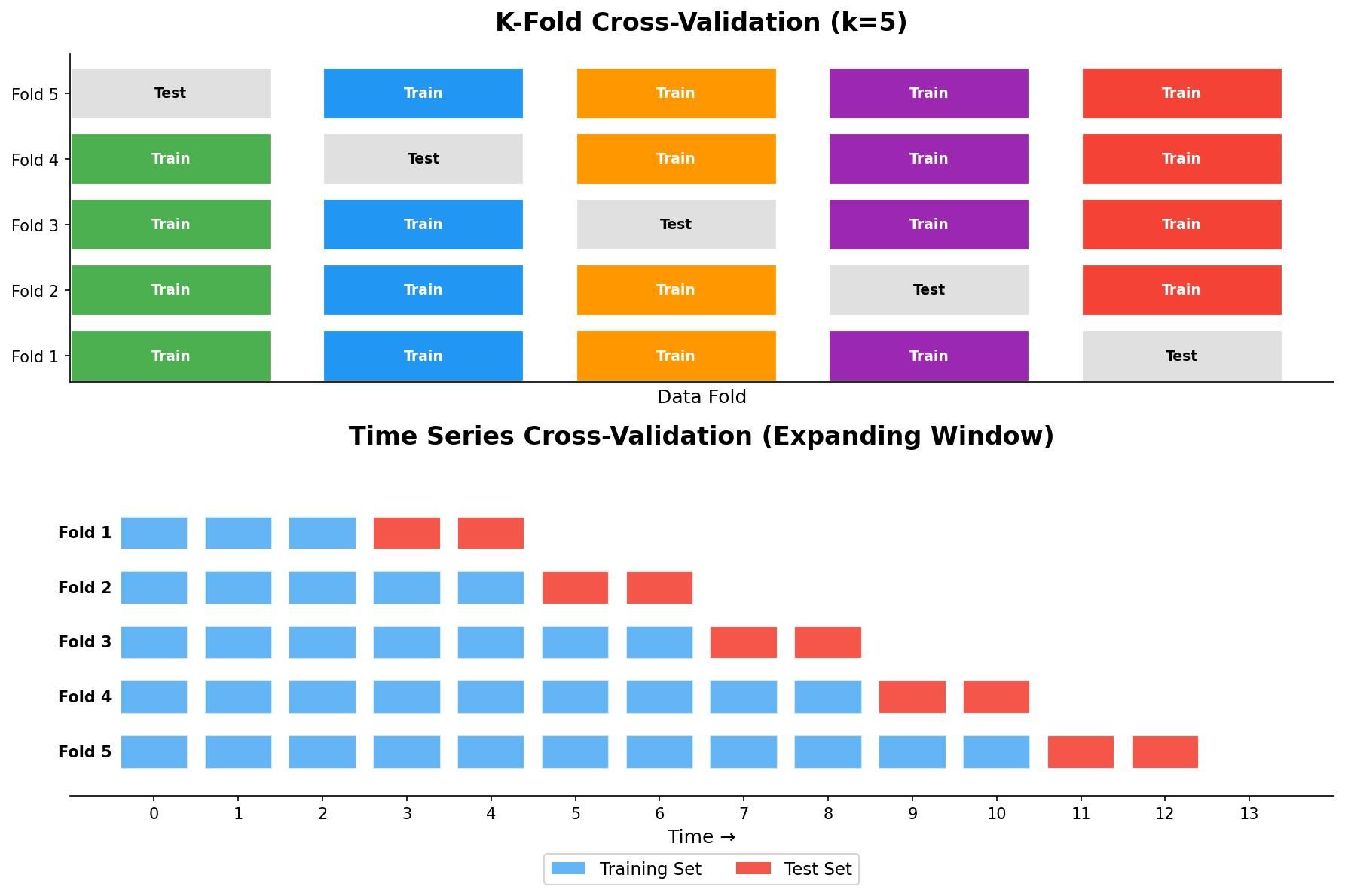
Gambar: Ilustrasi K-Fold CV (kiri) dan Time Series CV Expanding Window (kanan) — Sumber: Diagram orisinal untuk keperluan edukasi
import numpy as np
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
np.random.seed(42)
# Simulasi data time series: 100 titik data berurutan
X = np.random.randn(100, 2)
y = (np.sin(np.arange(100) * 0.3) > 0).astype(int) # label berubah seiring waktu
# KFold biasa — bocor karena shuffling
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for fold, (train_idx, test_idx) in enumerate(kf.split(X)):
print(f"Fold {fold+1}: train terakhir={train_idx[-1]}, test pertama={test_idx[0]}")
if test_idx[0] <= train_idx[-1]:
print(f" ⚠️ Data leakage terdeteksi!")Output:
Fold 1: train terakhir=99, test pertama=0
⚠️ Data leakage terdeteksi!
Fold 2: train terakhir=99, test pertama=5
⚠️ Data leakage terdeteksi!
Fold 3: train terakhir=99, test pertama=3
⚠️ Data leakage terdeteksi!
Fold 4: train terakhir=96, test pertama=32
⚠️ Data leakage terdeteksi!
Fold 5: train terakhir=99, test pertama=1
⚠️ Data leakage terdeteksi!Output ini menunjukkan bahwa KFold dengan shuffle menempatkan data train dan test secara acak tanpa memperhatikan urutan waktu, menyebabkan data masa depan muncul di training set.
Time Series Cross-Validation — TimeSeriesSplit dan Walk-Forward Validation
Untuk data deret waktu, kita membutuhkan pendekatan yang menghormati urutan temporal. Scikit-learn menyediakan TimeSeriesSplit yang membagi data secara kronologis: setiap fold menggunakan data masa lalu sebagai training dan data masa depan sebagai testing.
Konsep ini sering disebut _expanding window_ — jendela training terus bertambah seiring bertambahnya fold. Alternatifnya adalah _sliding window_, di mana kita menggunakan jendela waktu yang tetap dan menggesernya ke depan.
import matplotlib.pyplot as plt
from sklearn.model_selection import TimeSeriesSplit
X = np.arange(100).reshape(-1, 1)
y = np.sin(np.arange(100) * 0.1) + np.random.randn(100) * 0.1
tscv = TimeSeriesSplit(n_splits=5, gap=0)
fig, axes = plt.subplots(5, 1, figsize=(10, 8))
for fold, (train_idx, test_idx) in enumerate(tscv.split(X)):
axes[fold].scatter(train_idx, y[train_idx], c='blue', label='Train', s=10)
axes[fold].scatter(test_idx, y[test_idx], c='red', label='Test', s=10)
axes[fold].set_ylabel(f'Fold {fold+1}')
axes[fold].legend(loc='upper left')
plt.xlabel('Index Waktu')
plt.tight_layout()
plt.show()
Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Output:
[Image: TimeSeriesSplit visualization]
Plot di atas memperlihatkan bagaimana setiap fold menggunakan data yang lebih baru sebagai test set (titik merah), sementara training set (titik biru) mencakup semua data sebelumnya — tidak ada data leakage antar fold.
Parameter gap pada TimeSeriesSplit berguna ketika kita ingin menyisakan jeda antara train dan test untuk menghindari autocorrelation spillover. Pada data keuangan harian, misalnya, menggunakan gap 1–5 hari bisa memberikan estimasi yang lebih realistis.
Cross-Validation untuk Imbalanced Dataset — StratifiedKFold dan Iterasi Berlapis
Ketika menghadapi _imbalanced dataset_, solusi pertama yang harus dicoba adalah StratifiedKFold. Teknik ini memastikan setiap fold mempertahankan proporsi kelas yang sama dengan dataset asli. Ini adalah perbaikan signifikan dibanding KFold biasa, tetapi belum cukup untuk imbalance ekstrim.
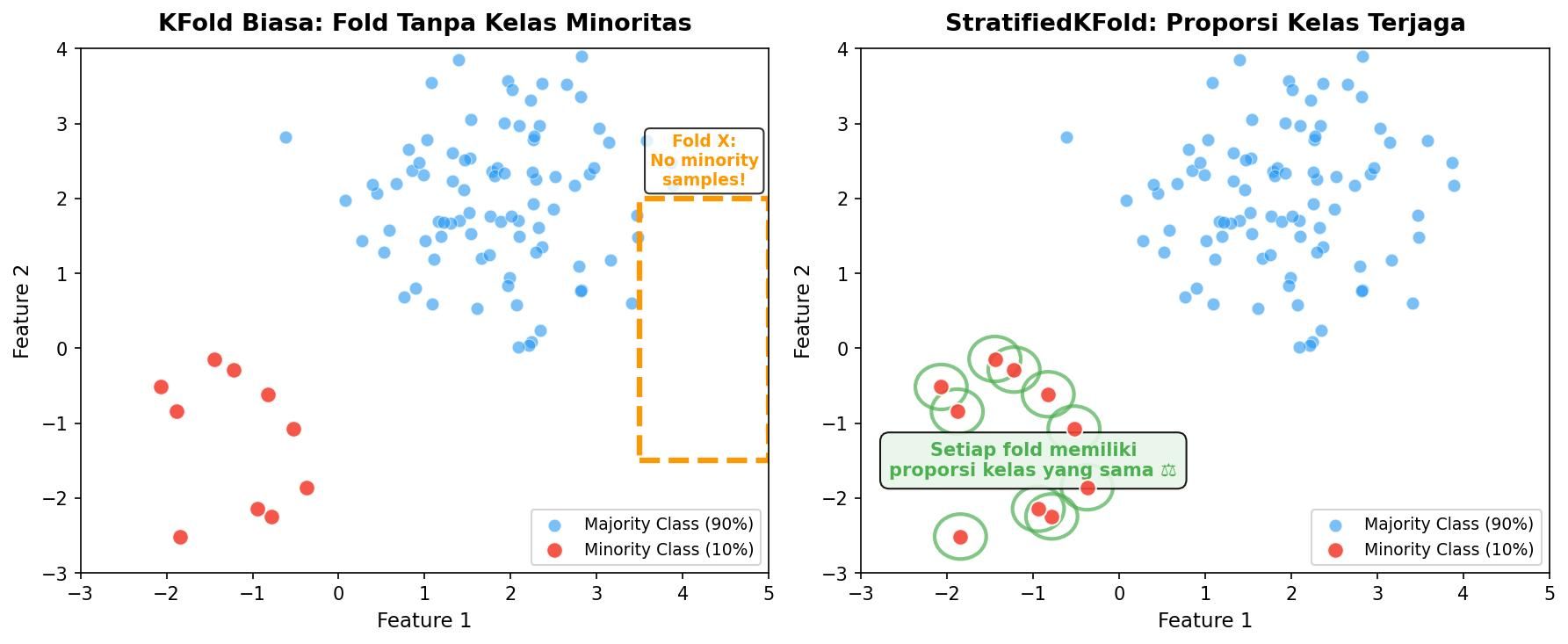
Gambar: Visualisasi masalah KFold biasa pada imbalanced dataset vs StratifiedKFold yang menjaga proporsi kelas — Sumber: Diagram orisinal untuk keperluan edukasi
from sklearn.model_selection import StratifiedKFold, RepeatedStratifiedKFold
from sklearn.datasets import make_classification
# Dataset dengan imbalance 90:10
X_imb, y_imb = make_classification(
n_samples=1000, n_features=5, weights=[0.9, 0.1],
random_state=42
)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("Proporsi kelas minoritas per fold:")
print("KFold biasa:", [np.mean(y_ims[train_idx]) for _, (train_idx, _) in ...])
# RepeatedStratifiedKFold: ulangi stratified split beberapa kali
rskf = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=42)RepeatedStratifiedKFold mengulangi proses stratified split beberapa kali dengan shuffle berbeda. Ini memberikan estimasi variance yang lebih stabil dan sangat berguna ketika dataset relatif kecil.
Peringatan penting: jika menggunakan SMOTE untuk oversampling, pastikan SMOTE diterapkan di dalam loop cross-validation, bukan sebelumnya. Menerapkan SMOTE sebelum split menyebabkan data sintetis bocor ke training set, karena sampel sintetis dibuat dari seluruh dataset termasuk data test. Hasilnya adalah evaluasi yang overly optimistic.
Custom Cross-Validation Strategy untuk Kasus Hybrid
Skenario paling menantang adalah ketika kita memiliki data yang bersifat time-dependent sekaligus highly imbalanced — misalnya deteksi fraud transaksi atau prediksi churn pelanggan. Kita perlu menggabungkan kedua constraint tersebut dalam satu strategi split.
Solusinya adalah membuat custom cross-validator dengan meng-inherit BaseCrossValidator dari scikit-learn. Kelas ini akan mengurutkan data berdasarkan waktu terlebih dahulu, lalu membagi fold sambil mempertahankan proporsi kelas di setiap fold sebisa mungkin.
from sklearn.model_selection import BaseCrossValidator
from sklearn.utils import indexable
from sklearn.utils.validation import check_random_state
class TimeSeriesStratifiedKFold(BaseCrossValidator):
def __init__(self, n_splits=5, shuffle=False, random_state=None):
self.n_splits = n_splits
self.shuffle = shuffle
self.random_state = random_state
def split(self, X, y=None, groups=None):
X, y, groups = indexable(X, y, groups)
n_samples = X.shape[0]
indices = np.arange(n_samples)
# Urutkan berdasarkan waktu (asumsi data sudah terurut)
fold_size = n_samples // self.n_splits
for i in range(self.n_splits):
test_start = (i + 1) * fold_size
if i == self.n_splits - 1:
test_end = n_samples
else:
test_end = test_start + fold_size
test_idx = indices[test_start:test_end]
train_idx = indices[:test_start]
# Validasi proporsi kelas
if y is not None:
train_ratio = np.mean(y[train_idx])
test_ratio = np.mean(y[test_idx])
print(f" Train ratio: {train_ratio:.3f}, Test ratio: {test_ratio:.3f}")
yield train_idx, test_idx
def get_n_splits(self, X=None, y=None, groups=None):
return self.n_splits
# Penggunaan
custom_cv = TimeSeriesStratifiedKFold(n_splits=5)
for fold, (train_idx, test_idx) in enumerate(custom_cv.split(X_imb, y_imb)):
print(f"Fold {fold+1}: {len(train_idx)} train, {len(test_idx)} test")Pendekatan ini memastikan dua hal: (1) data tidak bocor secara temporal karena fold dibuat berdasarkan urutan waktu, dan (2) distribusi kelas di setiap fold dapat dimonitor untuk memastikan tidak ada fold yang kehilangan kelas minoritas sepenuhnya.
Memilih Metrik Evaluasi yang Tepat untuk Setiap Strategi CV
Strategi cross-validation yang benar harus diimbangi dengan metrik evaluasi yang sesuai. Pada data imbalanced, akurasi bisa sangat menyesatkan — model yang memprediksi semua sampel sebagai kelas mayoritas bisa mencapai akurasi 90% pada dataset dengan imbalance 90:10.
Untuk data imbalanced, fokus pada Precision, Recall, dan F1-Score. Untuk data time series, perhatikan juga metrik yang sensitif terhadap urutan seperti _Mean Absolute Scaled Error_ (MASE) atau _symmetric Mean Absolute Percentage Error_ (sMAPE). ROC-AUC tetap berguna untuk classification problem, tetapi perlu diperhatikan bahwa ROC-AUC bisa overly optimistis pada imbalance ekstrim.
Berikut panduan praktisnya:
| Tipe Data | Strategi CV | Metrik Utama | |---|---|---| | Regresi time series | TimeSeriesSplit, Walk-Forward | RMSE, MASE, sMAPE | | Klasifikasi time series | TimeSeriesSplit + Stratified | F1, Precision-Recall AUC | | Imbalance moderat | StratifiedKFold | F1, ROC-AUC | | Imbalance ekstrim | RepeatedStratifiedKFold | Precision-Recall AUC | | Hybrid (time + imbalance) | Custom TimeSeriesStratifiedKFold | F1 per fold, distribusi skor |
Perhatikan juga distribusi skor antar fold — jangan hanya melihat rata-rata. Variance yang tinggi antar fold menandakan bahwa model tidak stabil atau strategi split belum optimal.
Kesalahan dalam memilih strategi cross-validation adalah salah satu _common pitfalls_ yang paling sering ditemui dalam _machine learning workflow_. Jika kamu ingin memperdalam pemahaman tentang evaluasi model, feature engineering, hingga deployment, ikuti Bootcamp Machine Learning di Rumah Coding. Kami membahas praktik terbaik mulai dari preprocessing sampai produksi dengan studi kasus nyata.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python