Exploratory Data Analysis dengan Sweetviz: Auto-Generate Profile Report
Exploratory Data Analysis (EDA) adalah langkah pertama yang penting dalam setiap proyek data science. Sebelum kita membangun model atau menarik kesimpulan, kita perlu memahami karakteristik dataset secara menyeluruh — mulai dari distribusi nilai, korelasi antar fitur, hingga keberadaan missing values. Sayangnya, EDA manual dengan Pandas seringkali membutuhkan puluhan baris kode yang terpisah-pisah. Sweetviz hadir sebagai solusi yang mengotomatisasi seluruh proses ini dalam satu panggilan fungsi.
Mengapa Memilih Sweetviz untuk Eksplorasi Data Otomatis
Dalam workflow EDA konvensional menggunakan Pandas, kita harus menulis baris demi baris kode untuk setiap jenis analisis: .describe() untuk statistik ringkasan, .isnull().sum() untuk deteksi missing values, .corr() untuk matriks korelasi, dan .hist() untuk visualisasi distribusi. Belum lagi kode tambahan untuk mengatur ukuran plot dan menyusun layout visualisasinya. Proses ini tidak hanya memakan waktu, tetapi juga rawan inkonsistensi ketika kita bekerja dengan banyak dataset berbeda.
Sweetviz mengubah paradigma ini dengan menyediakan fungsi analyze() yang menghasilkan laporan HTML interaktif lengkap dalam satu panggilan. Laporan yang dihasilkan mencakup ringkasan statistik per fitur, histogram distribusi, matriks korelasi, deteksi missing values, dan bahkan analisis asosiasi antar fitur kategorikal — semuanya tanpa perlu menulis kode visualisasi tambahan.
Dibandingkan dengan library EDA lain seperti ydata-profiling (sebelumnya dikenal sebagai pandas-profiling) dan D-Tale, Sweetviz memiliki keunggulan pada kemudahan perbandingan antar dataset. Fitur compare() dan compare_intra() memungkinkan kita melihat perbedaan profil dua dataset secara berdampingan, yang sangat berguna saat memvalidasi train-test split atau membandingkan data sebelum dan sesudah preprocessing. D-Tale unggul dalam eksplorasi interaktif berbasis GUI web, tetapi kurang cocok untuk laporan statis yang bisa dibagikan ke tim. Sementara ydata-profiling menghasilkan laporan yang lebih detail secara statistik, tetapi proses komputasinya lebih lambat pada dataset berukuran sedang. Dengan Sweetviz, kita mendapatkan keseimbangan antara kecepatan, kedalaman informasi, dan kemudahan berbagi laporan dalam format HTML yang ringan.
!pip install sweetviz pandas
import sweetviz as sv
import pandas as pd
# Baca dataset contoh
df = pd.read_csv("contoh_data.csv")
# Hasilkan profile report dengan satu baris kode
report = sv.analyze(df)
# Simpan dan buka laporan
report.show_html("SWEETVIZ_REPORT.html")Kode di atas sudah cukup untuk menghasilkan laporan EDA yang interaktif. File HTML yang dihasilkan bisa langsung dibuka di browser dan menyajikan seluruh informasi yang kita butuhkan untuk memahami dataset.
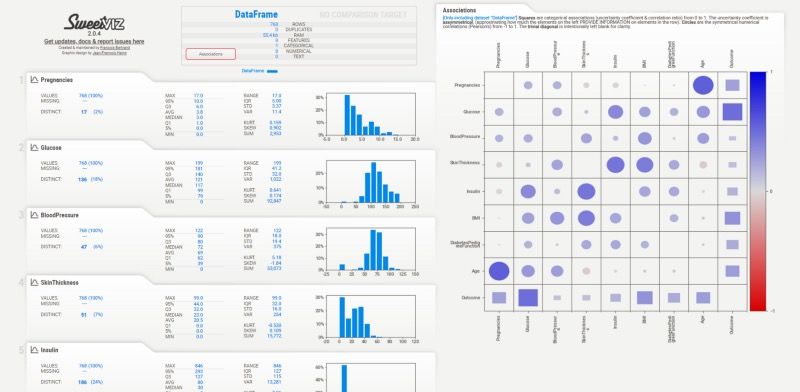
Gambar: Contoh laporan EDA yang dihasilkan Sweetviz menampilkan ringkasan dataset, distribusi fitur numerik dan kategorikal, serta informasi missing values — Sumber: [DataGrads](https://www.datagrads.com/sweetviz-for-quicker-in-depth-exploratory-data-analysis/)
Membaca Dataset dan Menghasilkan Profile Report Pertama
Untuk memahami cara kerja Sweetviz secara praktis, mari kita gunakan dataset publik yang sudah dikenal luas: Tips dataset dari Seaborn. Dataset ini berisi informasi tentang transaksi restoran termasuk total tagihan, jumlah tip, jenis kelamin pelanggan, hari, waktu makan, dan ukuran grup.
Fungsi analyze() adalah pintu masuk utama ke Sweetviz. Kita cukup memberikan DataFrame sebagai argumen, dan Sweetviz akan secara otomatis memeriksa setiap kolom — mendeteksi tipe data numerik atau kategorikal, menghitung statistik deskriptif, dan membangun visualisasi distribusi. Proses ini berlangsung dalam tiga tahap: summarization per fitur, pairwise feature processing, dan pembuatan associations graph. Progress setiap tahap ditampilkan di terminal sehingga kita bisa memperkirakan waktu komputasi yang tersisa.
!pip install sweetviz pandas seaborn
import sweetviz as sv
import seaborn as sns
# Load dataset Tips dari seaborn
df = sns.load_dataset("tips")
# Generate profile report
report = sv.analyze(df)
# Simpan ke file HTML dan buka
report.show_html("SWEETVIZ_REPORT.html")Output:

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
[Summarizing dataframe] | | [ 0%] 00:00 -> (? left)
Feature: total_bill |██▌ | [ 25%] 00:00 -> (00:01 left)
Feature: tip |███▊ | [ 38%] 00:00 -> (00:01 left)
Feature: sex |█████ | [ 50%] 00:00 -> (00:00 left)
Feature: smoker |██████▎ | [ 62%] 00:01 -> (00:00 left)
Feature: day |███████▌ | [ 75%] 00:01 -> (00:00 left)
Feature: time |███████▌ | [ 75%] 00:01 -> (00:00 left)
Feature: size |██████████| [100%] 00:01 -> (00:00 left)
[Step 2/3] Processing Pairwise Features | | [ 0%] 00:00 -> (? left)
[Step 3/3] Generating associations graph | | [ 0%] 00:00 -> (? left)
Done! Use 'show' commands to display/save. |██████████| [100%] 00:00 -> (00:00 left)
Report SWEETVIZ_REPORT.html was generated!Parameter target dalam analyze() memungkinkan kita menentukan kolom target untuk analisis supervised. Ketika parameter ini diisi, Sweetviz secara otomatis menambahkan visualisasi yang menunjukkan bagaimana setiap fitur berkontribusi terhadap target variable — seberapa baik suatu fitur membedakan nilai-nilai target. Parameter feat_cfg berguna untuk mengelompokkan fitur tertentu, misalnya menentukan kolom mana yang harus diperlakukan sebagai kategorikal meskipun berisi angka. Sementara itu, pairwise_analysis mengontrol komputasi korelasi berpasangan dan dapat diatur ke mode "off" untuk dataset besar agar proses tetap cepat.
Membandingkan Dua Dataset dengan compare() dan compare_intra()
Salah satu fitur paling kuat dari Sweetviz adalah kemampuannya membandingkan dua dataset secara side-by-side. Fungsi compare() menerima dua DataFrame dan menghasilkan laporan yang menyoroti perbedaan distribusi, perubahan korelasi, dan shifting missing values antara keduanya.
Kemampuan ini sangat berguna dalam skenario validasi train-test split. Setelah kita membagi dataset menjadi data latih dan data uji, kita perlu memastikan bahwa distribusi kedua subset tersebut konsisten. Jika terdapat perbedaan signifikan, model yang kita latih mungkin tidak akan bekerja dengan baik pada data uji.
!pip install sweetviz pandas numpy
import sweetviz as sv
import pandas as pd
import numpy as np
# Load dataset
df = pd.read_csv("contoh_data.csv")
# Split dataset
train = df.sample(frac=0.8, random_state=42)
test = df.drop(train.index)
# Bandingkan kedua dataset
comparison = sv.compare([train, "Training Data"], [test, "Test Data"])
comparison.show_html("TRAIN_TEST_COMPARISON.html")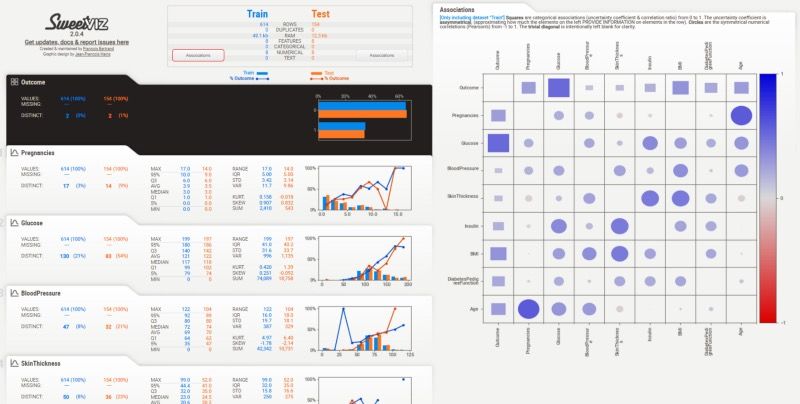
Gambar: Contoh laporan perbandingan Sweetviz yang menyoroti perbedaan distribusi fitur antara dua dataset (misalnya train vs test) secara berdampingan — Sumber: [DataGrads](https://www.datagrads.com/sweetviz-for-quicker-in-depth-exploratory-data-analysis/)
Selain compare(), Sweetviz juga menyediakan compare_intra() untuk membandingkan subgroup dalam satu dataset. Misalnya, kita bisa membandingkan profil pelanggan pria versus wanita dalam dataset yang sama, atau membandingkan transaksi di hari weekdays versus weekend. Sintaksnya sederhana: sv.compare_intra(df, df["kolom"] == "kondisi", ["Label Ya", "Label Tidak"]). Fitur ini sangat berguna ketika kita ingin menyelidiki perbedaan karakteristik antar segmen dalam data, membantu kita menemukan insight yang mungkin terlewatkan jika hanya melihat agregat keseluruhan.
Menginterpretasikan Informasi dalam Laporan Sweetviz
Laporan yang dihasilkan Sweetviz menyajikan informasi dalam format yang terstruktur dan mudah dicerna. Untuk setiap fitur, laporan menampilkan ringkasan statistik yang mencakup tipe data, jumlah unique values, persentase missing values, serta nilai mean, min, dan max untuk fitur numerik.
Visualisasi distribusi menjadi komponen utama dalam laporan ini. Untuk fitur numerik, Sweetviz menampilkan histogram yang memperlihatkan sebaran data secara visual — apakah distribusinya normal, skewed, atau memiliki multimodal pattern. Untuk fitur kategorikal, bar chart menunjukkan frekuensi setiap kategori, lengkap dengan persentase proporsinya.
Bagian associations matrix menyajikan korelasi Pearson antar fitur numerik dan Uncertainty Coefficient untuk fitur kategorikal. Matriks ini membantu kita mengidentifikasi hubungan linear antar variabel dan fitur-fitur yang mungkin redundan. Nilai korelasi berkisar antara -1 hingga +1, di mana nilai mendekati +1 menunjukkan hubungan positif yang kuat dan nilai mendekati -1 menunjukkan hubungan negatif yang kuat. Jika dua fitur memiliki korelasi di atas 0.8, kita mungkin perlu mempertimbangkan untuk menghilangkan salah satunya guna menghindari multicollinearity dalam modeling. Untuk fitur kategorikal, Uncertainty Coefficient mengukur seberapa baik nilai suatu fitur dapat memprediksi nilai fitur lainnya — semakin tinggi angkanya, semakin kuat ketergantungan antar keduanya.
Ketika parameter target ditentukan, laporan juga menyertakan target analysis yang menunjukkan bagaimana distribusi setiap fitur berubah berdasarkan nilai target. Informasi ini sangat berharga untuk feature selection awal — kita bisa langsung melihat fitur mana yang memiliki daya pembeda tinggi terhadap target.
Mengintegrasikan Sweetviz dalam Pipeline EDA
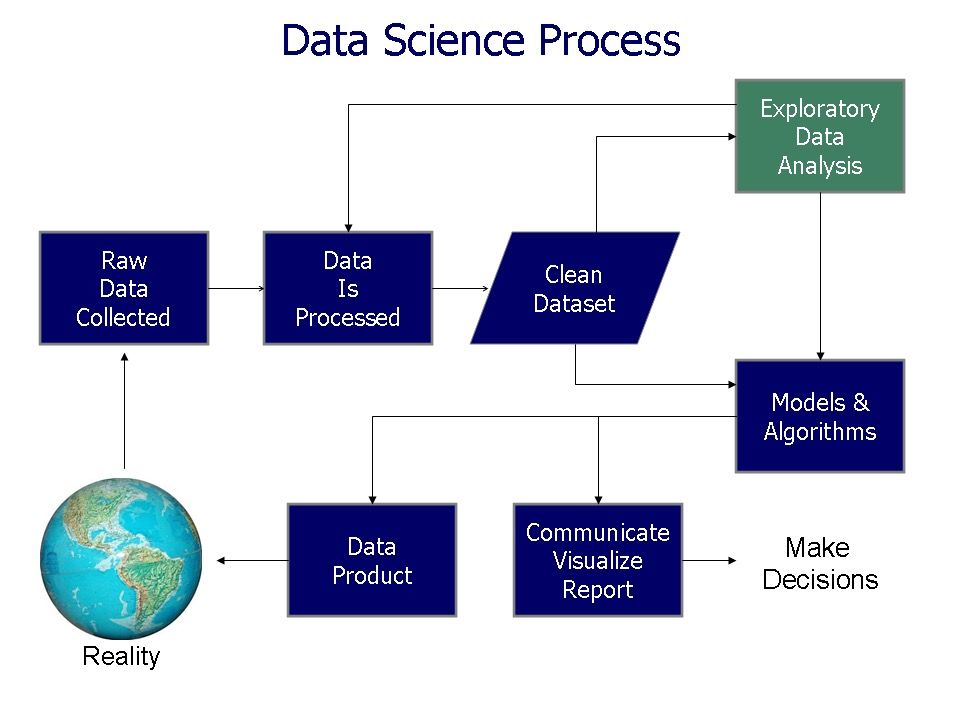
Gambar: Alur kerja data science yang menunjukkan bagaimana EDA menjadi langkah integral setelah data preparation dan sebelum modeling — Sumber: [Wikimedia Commons (CC BY-SA 3.0)](https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png)
Untuk memaksimalkan manfaat Sweetviz dalam proyek data science, kita perlu mengintegrasikannya sebagai langkah standar dalam pipeline EDA. Idealnya, setiap kali kita menerima dataset baru, kita menjalankan Sweetviz untuk mendapatkan gambaran cepat sebelum masuk ke tahap preprocessing dan modeling yang lebih mendalam.
!pip install sweetviz pandas
import sweetviz as sv
import pandas as pd
from datetime import datetime
import os
# Buat folder untuk menyimpan report
REPORT_DIR = "eda_reports"
os.makedirs(REPORT_DIR, exist_ok=True)
def generate_eda_report(df, dataset_name):
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"{REPORT_DIR}/{dataset_name}_{timestamp}.html"
report = sv.analyze(df)
report.show_html(filename)
print(f"Report saved: {filename}")
return filename
# Gunakan dalam pipeline
df = pd.read_csv("dataset_baru.csv")
generate_eda_report(df, "dataset_baru")Script di atas menunjukkan pola yang bisa kita terapkan dalam proyek nyata. Report disimpan dengan timestamp sehingga kita memiliki riwayat EDA yang terorganisir. Ini sangat berguna ketika dataset diperbarui secara berkala dan kita perlu melacak perubahan profil data dari waktu ke waktu. Dengan pendekatan ini, kita juga bisa membandingkan report lama dan baru untuk mendeteksi data drift — misalnya, apakah distribusi suatu fitur berubah signifikan setelah penambahan data terbaru. Tim data science dapat menjadwalkan script ini berjalan otomatis setiap kali ada pipeline injeksi data baru, dan menyimpan hasil report sebagai artifact di folder terpusat.
Meskipun Sweetviz sangat powerful, penting untuk memahami keterbatasannya. Library ini kurang optimal untuk dataset di atas 100 ribu baris karena proses komputasi akan terasa lambat. Untuk dataset besar, sebaiknya kita melakukan sampling terlebih dahulu atau menggunakan parameter pairwise_analysis="off". Selain itu, preprocessing dasar seperti pembersihan missing values tetap diperlukan sebelum menggunakan Sweetviz agar laporan yang dihasilkan akurat.
Best practice yang kami rekomendasikan adalah menggunakan Sweetviz untuk eksplorasi cepat dan iteratif di tahap awal proyek. Setelah mendapatkan gambaran umum dari laporan Sweetviz, kita bisa melanjutkan dengan analisis statistik lanjutan dan visualisasi kustom yang lebih mendalam menggunakan Matplotlib atau Seaborn.
EDA yang sistematis adalah fondasi dari proyek data science yang sukses. Jika kamu ingin menguasai seluruh pipeline data science — dari EDA, feature engineering, hingga model deployment — Bergabunglah dengan Bootcamp Data Science di Rumah Coding. Kami menyediakan kurikulum terstruktur dengan studi kasus nyata yang akan membantumu menjadi data scientist yang siap terjun ke industri.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner
Memahami Algoritma Random Forest dari Teori sampai Implementasi dengan Scikit-learn untuk Klasifikasi dan Regresi
