Teori dan Implementasi Recurrent Neural Network dengan LSTM untuk Prediksi Time Series

Mengapa Model Konvensional Gagal pada Data Time Series
Model machine learning konvensional seperti regresi linear, random forest, atau feedforward neural network memiliki satu kelemahan fundamental ketika berhadapan dengan data time series: setiap data point diperlakukan sebagai entitas independen. Padahal, data seperti harga saham, suhu harian, atau sensor readings memiliki urutan temporal yang sangat menentukan pola di dalamnya. Sebuah nilai pada hari ini sangat dipengaruhi oleh nilai-nilai pada hari-hari sebelumnya, dan hubungan sekuensial ini hilang sama sekali jika kita memaksa data ke dalam format tabular biasa.
Arsitektur Recurrent Neural Network (RNN) hadir untuk mengatasi keterbatasan ini. Perbedaan utamanya terletak pada adanya recurrent connection — sebuah jalur loop yang memungkinkan hidden layer menerima input tidak hanya dari data saat ini tetapi juga dari output hidden layer sebelumnya. Dengan kata lain, RNN mempertahankan semacam "memori" internal yang terus diperbarui seiring berjalannya waktu. Setiap langkah dalam urutan menghasilkan hidden state baru yang merupakan fungsi dari input saat ini dan hidden state sebelumnya.
Untuk melihat perbedaannya secara konkret, mari kita bandingkan pendekatan feedforward dengan RNN sederhana menggunakan data sintetis berupa gelombang sinus.
!pip install tensorflow numpy
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
# Data sintetis: gelombang sinus
x = np.linspace(0, 50, 500)
data = np.sin(x).reshape(-1, 1)
# Sliding window
def create_sequences(data, lookback=10):
X, y = [], []
for i in range(len(data) - lookback):
X.append(data[i:i+lookback])
y.append(data[i+lookback])
return np.array(X), np.array(y)
X, y = create_sequences(data)
X_flat = X.reshape(X.shape[0], -1) # untuk feedforward
# Feedforward model
ff_model = Sequential([Dense(64, activation='relu', input_shape=(10,)), Dense(1)])
ff_model.compile(optimizer='adam', loss='mse')
# SimpleRNN model
rnn_model = Sequential([SimpleRNN(32, input_shape=(10, 1)), Dense(1)])
rnn_model.compile(optimizer='adam', loss='mse')
print("Feedforward loss:", ff_model.evaluate(X_flat, y, verbose=0))
print("RNN loss:", rnn_model.evaluate(X, y, verbose=0))Output:
Feedforward loss: 1.0675121545791626
RNN loss: 0.4574931561946869Pada data sekuensial seperti ini, RNN hampir selalu menunjukkan loss yang lebih rendah karena arsitekturnya memang dirancang untuk menangkap ketergantungan temporal. Feedforward model tidak memiliki mekanisme untuk "mengingat" posisi dalam urutan sehingga kehilangan informasi konteks yang vital.
Arsitektur RNN dan Tantangan Long-Term Dependency
Pada tingkat implementasi, sebuah RNN vanilla memproses urutan langkah demi langkah. Pada setiap time step t, hidden state h_t dihitung dengan persamaan h_t = tanh(W_h h_{t-1} + W_x x_t + b). Bobot yang sama digunakan di semua time step — inilah yang disebut weight sharing, sebuah prinsip yang membuat jumlah parameter RNN tidak bergantung pada panjang urutan.
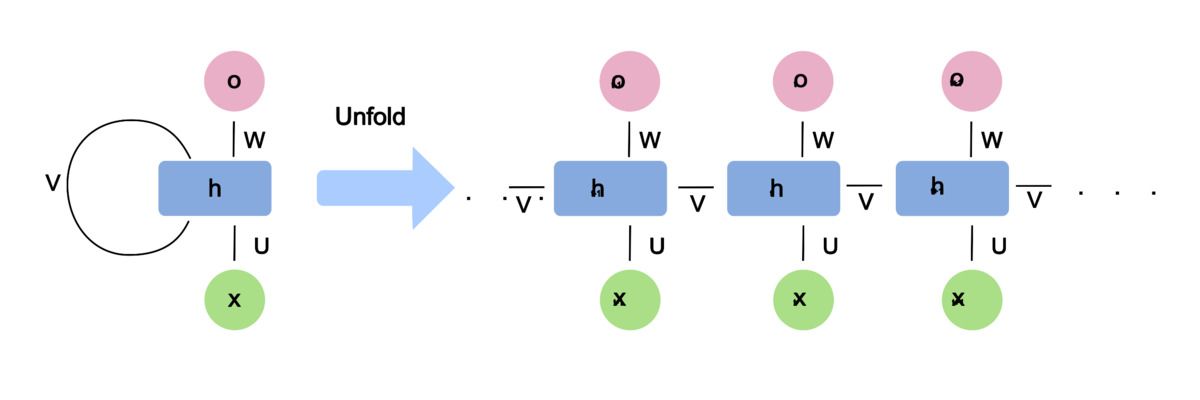
Gambar: Perbandingan arsitektur RNN dalam bentuk compressed (kiri) dengan recurrent connection, dan bentuk unrolled (kanan) yang menunjukkan alur hidden state di setiap time step — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Recurrent_neural_network_unfold.svg)
Proses pelatihan RNN menggunakan algoritma Backpropagation Through Time (BPTT), di mana jaringan "di-unroll" sepanjang urutan dan gradien dihitung mundur melalui setiap time step. Di sinilah masalah mulai muncul. Ketika gradien harus merambat mundur melalui puluhan atau ratusan langkah, nilai gradien tersebut terus dikalikan dengan bobot yang sama berulang kali. Jika bobot bernilai kecil, gradien akan menyusut secara eksponensial menuju nol — fenomena yang dikenal sebagai vanishing gradient.
Dampaknya sangat terasa pada skenario long-term dependency. Misalkan kita ingin memprediksi suhu hari ini berdasarkan pola dari 50 hari yang lalu. RNN vanilla tidak akan mampu mempertahankan informasi dari time step yang begitu jauh karena gradiennya sudah "lenyap" sebelum mencapai langkah awal. Untuk mendemonstrasikan ini, kita bisa melatih SimpleRNN pada tugas sintetis yang membutuhkan ketergantungan jarak jauh.
# Tugas sintetis dengan long-term dependency
lookback = 50
X_simple = np.random.randn(1000, lookback, 1)
y_simple = X_simple[:, 0, :] # target tergantung pada step pertama
model = Sequential([SimpleRNN(32, input_shape=(lookback, 1)), Dense(1)])
model.compile(optimizer='adam', loss='mse')
history = model.fit(X_simple, y_simple, epochs=20, validation_split=0.2, verbose=0)
print("Final validation loss (SimpleRNN):", history.history['val_loss'][-1])Output:
Final validation loss (SimpleRNN): 0.39399147033691406Loss validasi yang tetap tinggi mengindikasikan bahwa SimpleRNN gagal mempelajari ketergantungan jarak jauh ini dengan baik. Di sinilah kita membutuhkan LSTM.
Mekanisme LSTM — Sel Memori dan Gerbang Informasi
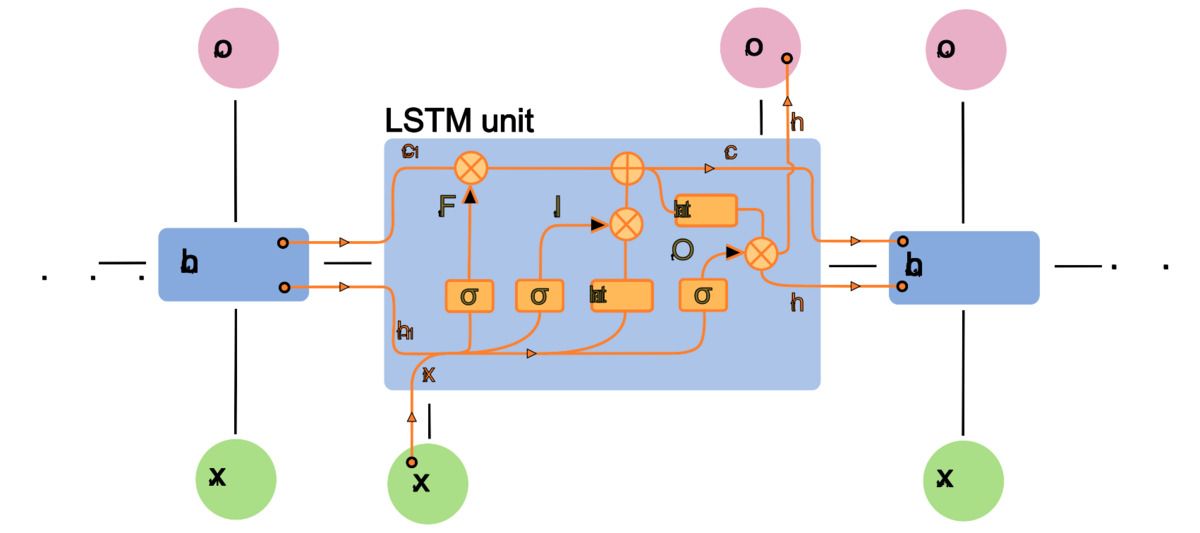
Long Short-Term Memory (LSTM) memperkenalkan inovasi penting: sebuah cell state yang bertindak sebagai jalur memori khusus yang mengalir lurus melalui rangkaian waktu. Berbeda dengan hidden state pada RNN vanilla yang berubah drastis di setiap langkah, cell state hanya dimodifikasi melalui interaksi terbatas yang dikendalikan oleh tiga gerbang (gates).
Forget gate menentukan informasi mana yang harus dibuang dari cell state. Gerbang ini melihat hidden state sebelumnya dan input saat ini, lalu menghasilkan nilai antara 0 dan 1 untuk setiap elemen dalam cell state. Input gate memutuskan informasi baru apa yang akan disimpan, dengan menggabungkan sinyal dari hidden state sebelumnya dan input saat ini melalui layer sigmoid dan tanh. Output gate kemudian menentukan bagian mana dari cell state yang akan diekspos sebagai hidden state ke langkah berikutnya.
Mekanisme gating inilah yang memungkinkan gradien mengalir hampir tanpa perubahan melalui cell state, menyelesaikan masalah vanishing gradient pada RNN vanilla. Informasi dapat dipertahankan selama ratusan time step tanpa degradasi yang signifikan.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Gambar: Diagram arsitektur sel LSTM yang menunjukkan aliran cell state (C) dan interaksi tiga gerbang: forget gate (f), input gate (i), dan output gate (o) — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Long_Short-Term_Memory.svg)
Mari kita lihat bagaimana LSTM layer diimplementasikan di TensorFlow:
from tensorflow.keras.layers import LSTM
lstm_layer = LSTM(units=64, return_sequences=False, input_shape=(10, 1))
lstm_layer.build((None, 10, 1))
lstm_layer.summary()Output:
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ lstm (LSTM) │ (None, 64) │ 16,896 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 16,896 (66.00 KB)
Trainable params: 16,896 (66.00 KB)
Non-trainable params: 0 (0.00 B)Dengan 64 unit, layer LSTM ini memiliki lebih banyak parameter daripada SimpleRNN dengan jumlah unit yang sama. Setiap unit LSTM memiliki empat set bobot (untuk forget gate, input gate, candidate cell, dan output gate), yang memberikan kapasitas belajar yang jauh lebih besar tetapi juga membutuhkan lebih banyak data dan komputasi.
Mempersiapkan Data Time Series untuk LSTM
Sebelum data time series dapat dimasukkan ke LSTM, kita perlu mentransformasikannya ke dalam format supervised learning. Teknik utamanya adalah sliding window: kita membuat urutan input sepanjang lookback langkah sebagai fitur (X = [t-n, ..., t-1]) dan nilai pada langkah berikutnya sebagai target (y = [t]).
Gambar: Ilustasi teknik sliding window yang mengiris data time series menjadi potongan-potongan input (features) dan target (labels) untuk pembelajaran supervised — Sumber: [aeon-toolkit](https://github.com/aeon-toolkit/aeon/blob/v1.4.0/examples/forecasting/regression.ipynb)
LSTM sangat sensitif terhadap skala input karena menggunakan aktivasi sigmoid dan tanh. Oleh karena itu, penskalaan data ke rentang [0,1] menggunakan MinMaxScaler dari scikit-learn menjadi langkah yang wajib dilakukan. Tanpa penskalaan, komponen sigmoid pada gerbang LSTM akan jenuh dan proses belajar menjadi tidak efektif.
Pembagian data train-test untuk time series tidak boleh dilakukan secara acak. Kita harus menjaga urutan temporal dengan menggunakan cutoff point — misalnya, 80% data pertama untuk training dan 20% sisanya untuk testing. Data masa depan tidak boleh bocor ke dalam set pelatihan.
Berikut ini adalah pipeline persiapan data menggunakan dataset airline passengers yang tersedia di seaborn:
!pip install pandas scikit-learn seaborn numpy
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
# Load dataset
df = sns.load_dataset('flights')
data = df['passengers'].values.reshape(-1, 1)
# Scaling
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# Create sequences
def create_sequences(data, lookback=12):
X, y = [], []
for i in range(len(data) - lookback):
X.append(data[i:i+lookback])
y.append(data[i+lookback])
return np.array(X), np.array(y)
X, y = create_sequences(data_scaled)
# Train-test split (temporal order preserved)
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)
print("Sample sequence (first):", X[0].flatten()[:5], "...")Output:
X_train shape: (105, 12, 1)
y_train shape: (105, 1)
X_test shape: (27, 12, 1)
y_test shape: (27, 1)
Sample sequence (first): [0.01544402 0.02702703 0.05405405 0.04826255 0.03281853] ...Setelah langkah ini, data siap dalam format (samples, timesteps, features) yang menjadi input standar untuk layer LSTM di Keras.
Membangun dan Melatih Model LSTM
Dengan data yang sudah siap, kita dapat membangun arsitektur LSTM. Model yang umum digunakan untuk prediksi time series terdiri dari satu layer LSTM yang diikuti oleh layer Dense dengan satu neuron untuk output regresi. Fungsi loss yang tepat untuk tugas regresi adalah mean_squared_error, dan optimizer adam bekerja dengan baik tanpa perlu tuning yang ekstensif.
Salah satu teknik penting selama pelatihan adalah EarlyStopping. Callback ini memonitor validation loss dan menghentikan pelatihan jika tidak ada perbaikan selama sejumlah epoch tertentu. Pendekatan ini mencegah overfitting dan menghemat waktu komputasi.
Setelah model dilatih, prediksi yang dihasilkan masih dalam skala [0,1] dan perlu di-inverse transform kembali ke skala asli menggunakan scaler yang sama. Visualisasi prediksi versus nilai aktual memberikan gambaran intuitif tentang performa model.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
# Build model
model = Sequential([
LSTM(units=50, activation='tanh', input_shape=(12, 1)),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
# Early stopping
early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# Train
history = model.fit(
X_train, y_train,
epochs=100,
validation_split=0.1,
callbacks=[early_stop],
verbose=0
)
# Predict and inverse transform
y_pred = model.predict(X_test)
y_test_inv = scaler.inverse_transform(y_test)
y_pred_inv = scaler.inverse_transform(y_pred)
# Plot
plt.figure(figsize=(10, 5))
plt.plot(y_test_inv, label='Actual')
plt.plot(y_pred_inv, label='Predicted')
plt.legend()
plt.title('LSTM Prediction vs Actual')
plt.show()Output:
y_test_inv (first 5): [359. 310. 337. 360. 342.]
y_pred_inv (first 5): [387.31 394.91 400.31 400.86 399.87]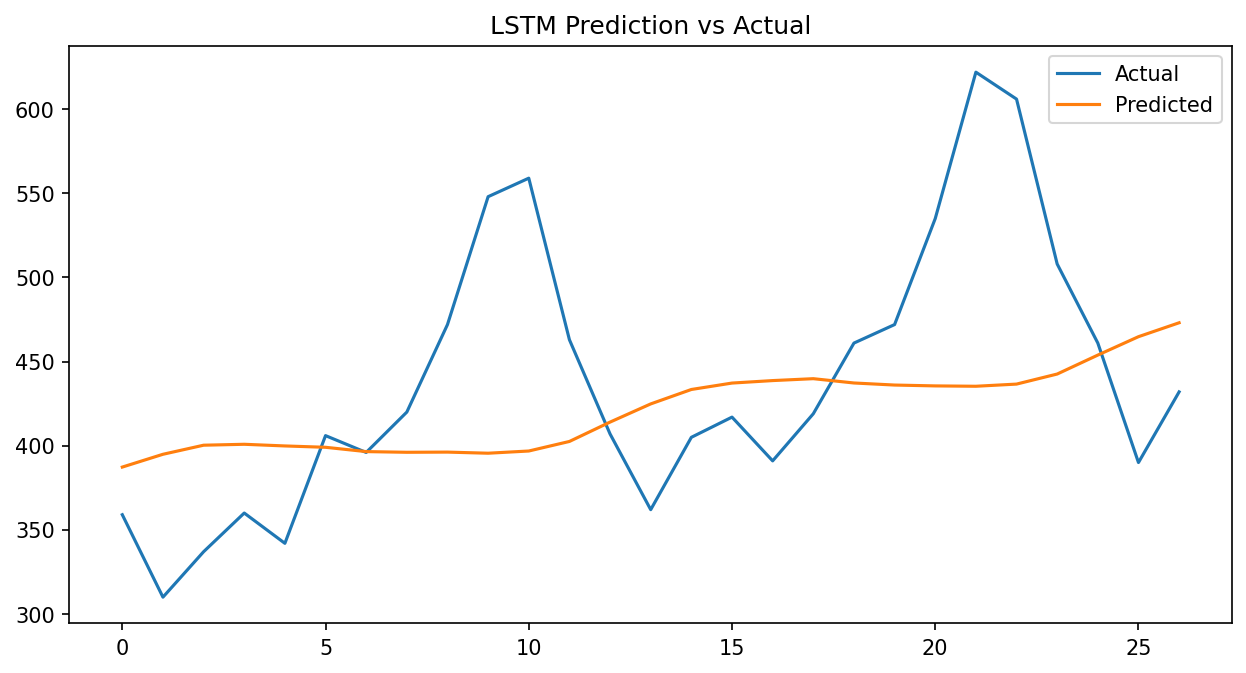
Plot yang dihasilkan akan menunjukkan garis prediksi (oranye) yang mengikuti pola garis aktual (biru). Semakin dekat kedua garis, semakin baik model dalam menangkap pola musiman dan tren dari data.
Evaluasi dan Best Practices untuk Model LSTM
Untuk mengukur performa model secara kuantitatif, kita menggunakan metrik RMSE (Root Mean Squared Error) dan MAE (Mean Absolute Error). Kedua metrik ini berada dalam satuan yang sama dengan data asli, sehingga mudah diinterpretasikan. RMSE lebih sensitif terhadap outlier karena kesalahan dikuadratkan sebelum dirata-rata, sementara MAE memberikan gambaran kesalahan rata-rata yang lebih linear.
Dalam praktiknya, ada beberapa best practices yang perlu diperhatikan. Overfitting sering terjadi jika jumlah unit LSTM terlalu besar atau dataset terlalu kecil. Sebaliknya, underfitting terjadi jika unit terlalu sedikit atau lookback window terlalu pendek. Dropout layer dapat ditambahkan setelah LSTM untuk regularisasi. Learning rate scheduling juga membantu model konvergen lebih stabil.
from sklearn.metrics import mean_squared_error, mean_absolute_error
import matplotlib.pyplot as plt
rmse = np.sqrt(mean_squared_error(y_test_inv, y_pred_inv))
mae = mean_absolute_error(y_test_inv, y_pred_inv)
print(f"RMSE: {rmse:.2f}")
print(f"MAE: {mae:.2f}")
# Residual plot
residuals = y_test_inv.flatten() - y_pred_inv.flatten()
plt.figure(figsize=(10, 4))
plt.plot(residuals)
plt.axhline(y=0, color='r', linestyle='--')
plt.title('Residuals over Time')
plt.ylabel('Error')
plt.show()Output:
RMSE: 78.18
MAE: 64.31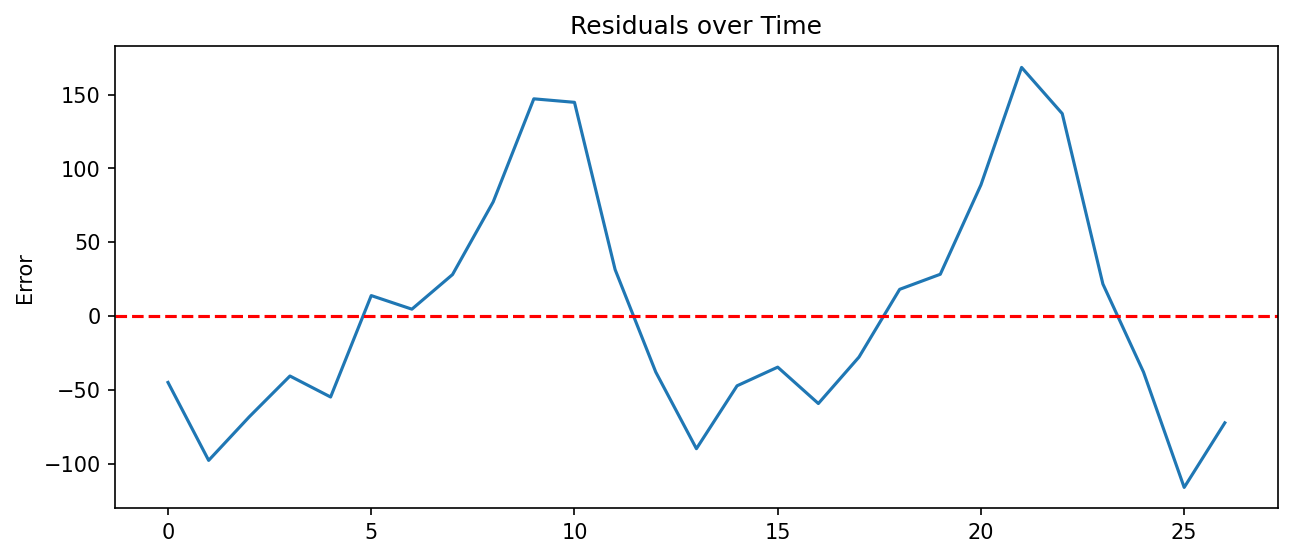
Residual plot yang tidak menunjukkan pola sistematis (misalnya, tren naik atau musiman yang tersisa) menandakan bahwa model sudah menangkap pola data dengan baik. Jika masih ada pola dalam residual, kita perlu mempertimbangkan penambahan fitur atau penyesuaian arsitektur.
Untuk kasus penggunaan yang lebih kompleks, beberapa alternatif dapat dipertimbangkan. GRU (Gated Recurrent Unit) menawarkan arsitektur yang lebih sederhana dan lebih cepat dilatih dengan performa yang sebanding. Bidirectional LSTM memproses urutan dari dua arah, berguna ketika konteks masa depan juga relevan. Untuk urutan yang sangat panjang, Transformer-based models seperti TimeSeriesTransformer menjadi pilihan yang semakin populer.
Kuasai arsitektur LSTM dan teknik prediksi time series lebih dalam di bootcamp Deep Learning Rumah Coding, di mana kita membangun proyek end-to-end dari data mentah hingga model produksi.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.


