Visualisasi Data Efektif menggunakan Matplotlib dan Seaborn untuk Analisis Eksplorasi

Visualisasi merupakan langkah pertama yang esensial dalam Exploratory Data Analysis (EDA). Tanpa visualisasi yang tepat, pola tersembunyi dan anomali dalam dataset akan sulit terdeteksi. Matplotlib menyediakan kontrol granular atas setiap elemen grafik, sementara Seaborn membangun abstraksi di atasnya untuk menghasilkan statistical plot yang informatif dengan sintaks yang ringkas.
Kombinasi kedua library ini menjadi standar de facto dalam workflow Data Science. Matplotlib cocok untuk kustomisasi mendalam ketika kita membutuhkan kontrol penuh atas setiap detail visual, sedangkan Seaborn mempercepat proses eksplorasi dengan default estimator dan statistical function yang siap pakai.
Setup dan Dataset
Kita membutuhkan matplotlib, seaborn, pandas, dan numpy untuk tutorial ini. Dataset yang digunakan adalah dataset bawaan Seaborn agar fokus pada teknik visualisasi.
!pip install matplotlib seaborn pandas numpy
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# Load dataset bawaan Seaborn
df = sns.load_dataset('tips')
print(df.head())
print(df.describe())Output:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000Dataset tips berisi informasi tentang tagihan makan, tip, jenis kelamin, waktu makan, dan ukuran grup. Dataset kecil ini cocok untuk mendemonstrasikan berbagai jenis plot.
Histogram dan Distribution Plot
Histogram memberikan gambaran distribusi dari variabel numerik. Kita bisa melihat sebaran data, kecenderungan central tendency, dan keberadaan outliers.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
df = sns.load_dataset('tips')
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Histogram total_bill dengan Matplotlib
axes[0].hist(df['total_bill'], bins=20, color='#4C72B0', edgecolor='white')
axes[0].set_xlabel('Total Bill ($)')
axes[0].set_ylabel('Frequency')
axes[0].set_title('Distribution of Total Bill')
# Distribution plot dengan Seaborn (hist + KDE)
sns.histplot(data=df, x='total_bill', kde=True, ax=axes[1], color='#DD8452')
axes[1].set_title('Total Bill with KDE')
plt.tight_layout()
plt.show()Output:
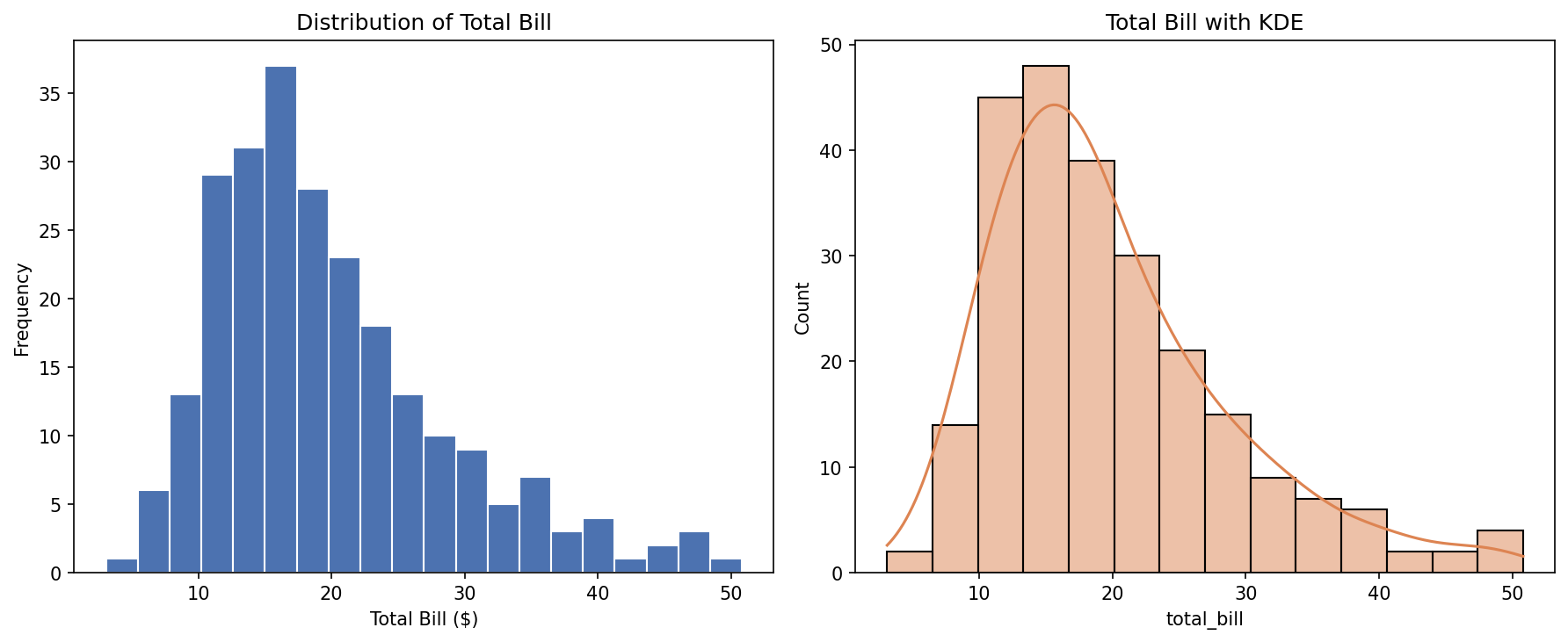
Seaborn menambahkan KDE (Kernel Density Estimation) curve di atas histogram, memberikan estimasi kontinu dari distribusi data. Curve ini membantu mengidentifikasi pola distribusi secara lebih halus dibanding histogram saja.
Scatter Plot dan Regresi
Scatter plot memperlihatkan hubungan antara dua variabel numerik. Dengan Seaborn, kita bisa langsung menambahkan regression line dan segmentasi berdasarkan variabel kategorikal.
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('tips')
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Scatter plot dasar
sns.scatterplot(data=df, x='total_bill', y='tip', ax=axes[0], color='#4C72B0', alpha=0.7)
axes[0].set_title('Total Bill vs Tip')
# Scatter plot dengan regression line
sns.regplot(data=df, x='total_bill', y='tip', ax=axes[1], scatter_kws={'alpha': 0.5}, line_kws={'color': 'red'})
axes[1].set_title('Regression: Total Bill vs Tip')
plt.tight_layout()
plt.show()Output:

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
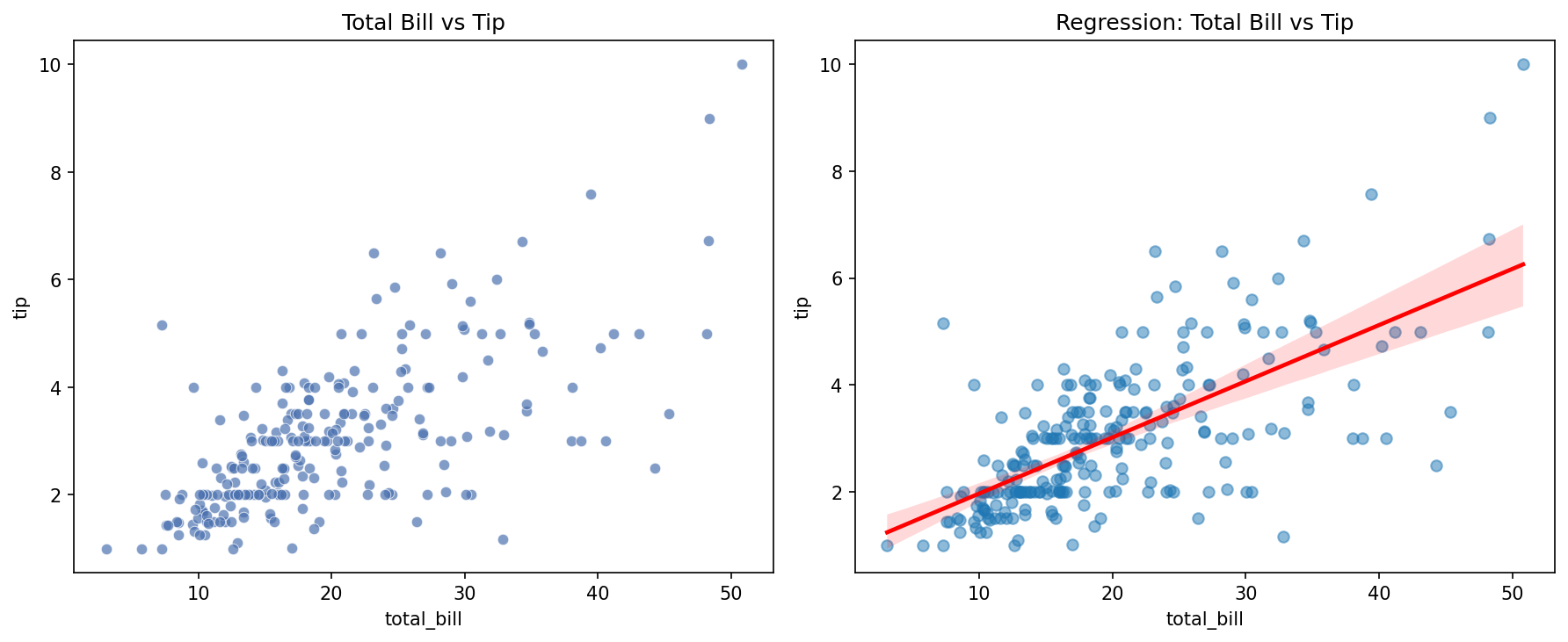
Regresi linear pada scatter plot menunjukkan korelasi positif antara total_bill dan tip. Confidence interval di sekitar garis regresi mengindikasikan kepastian model — interval yang sempit menandakan data mendukung estimasi dengan baik.
Categorical Plot
Ketika ingin membandingkan distribusi numerik berdasarkan kategori, Seaborn menawarkan boxplot, violinplot, dan barplot yang masing-masing memberikan perspektif berbeda.
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('tips')
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# Boxplot: distribusi tip per hari
sns.boxplot(data=df, x='day', y='tip', ax=axes[0], hue='day', palette='Set2', legend=False)
axes[0].set_title('Tip Distribution by Day')
# Violin plot: distribusi + density
sns.violinplot(data=df, x='day', y='tip', ax=axes[1], hue='day', palette='Set2', inner='quartile', legend=False)
axes[1].set_title('Violin: Tip by Day')
# Bar plot: rata-rata tip per hari dengan error bars
sns.barplot(data=df, x='day', y='tip', ax=axes[2], hue='day', palette='Set2', errorbar='sd', legend=False)
axes[2].set_title('Mean Tip by Day')
plt.tight_layout()
plt.show()Output:
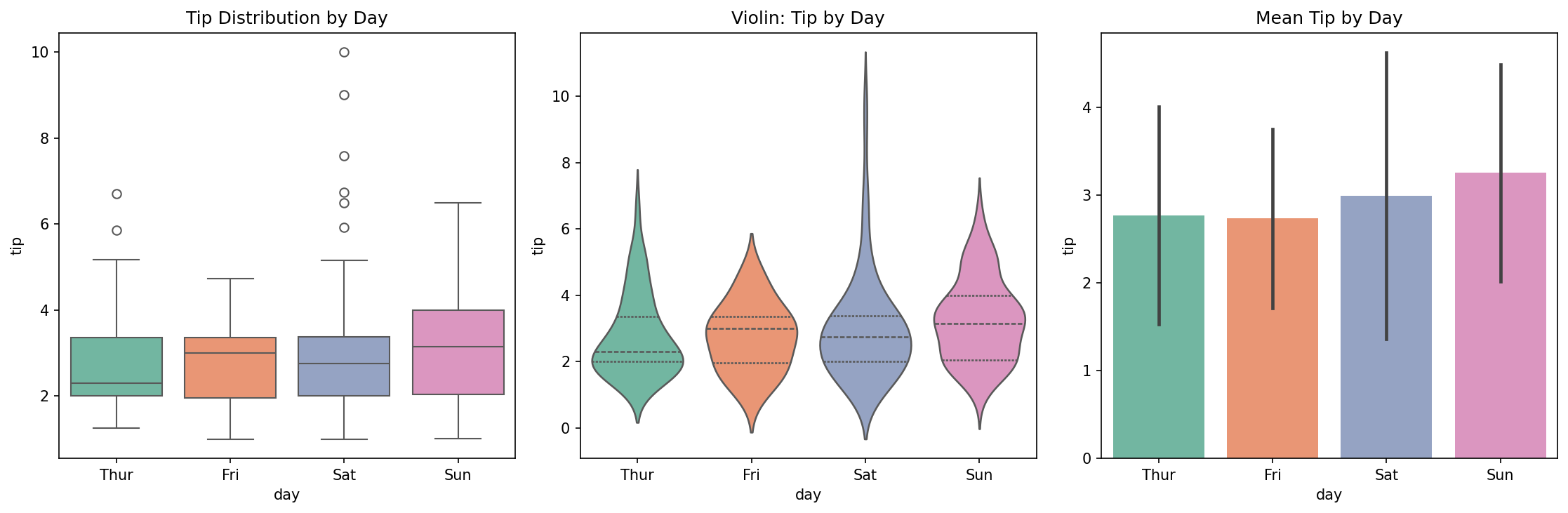
Boxplot menampilkan median, quartile, dan outliers secara ringkas. Violin plot menambahkan estimasi density pada boxplot, memberikan informasi distribusi yang lebih kaya. Bar plot menunjukkan mean dengan error bars yang merepresentasikan standar deviasi — cocok untuk presentasi ringkas kepada stakeholder.
Heatmap Korelasi
Heatmap korelasi merupakan salah satu plot paling informatif untuk memahami hubungan multivariat. Korelasi antar variabel numerik divisualisasikan dengan skala warna, membuat pattern identification menjadi lebih intuitif.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
df = sns.load_dataset('tips')
# Pilih kolom numerik saja
numeric_df = df.select_dtypes(include=[np.number])
corr = numeric_df.corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, cmap='RdBu_r', center=0, fmt='.2f',
square=True, linewidths=0.5)
plt.title('Correlation Heatmap - Tips Dataset')
plt.show()
print('Correlation matrix:')
print(corr)Output:
Correlation matrix:
total_bill tip size
total_bill 1.000000 0.675734 0.598315
tip 0.675734 1.000000 0.489299
size 0.598315 0.489299 1.000000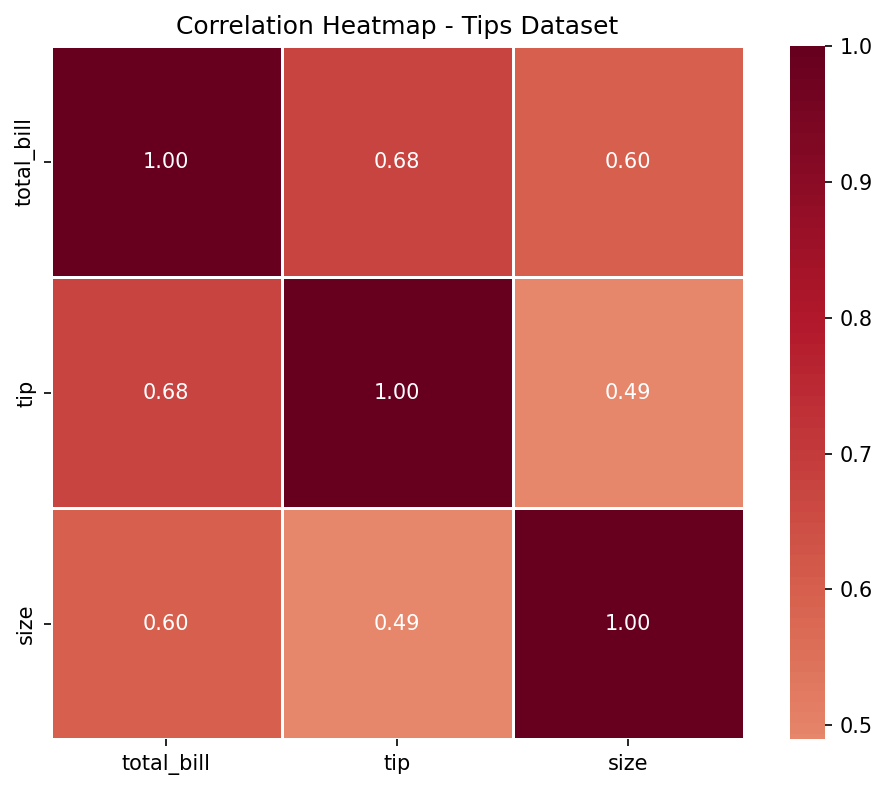
Parameter annot=True menambahkan nilai korelasi pada setiap sel. cmap='RdBu_r' menggunakan skala merah-biru yang intuitif — merah menandakan korelasi positif, biru menandakan korelasi negatif. Nilai yang mendekati 0 menunjukkan tidak ada hubungan linear yang signifikan.
Pairplot untuk Analisis Multivariat
Untuk dataset dengan beberapa variabel numerik, pairplot menghasilkan matriks scatter plot antar semua pasangan variabel. Plot diagonal menampilkan distribusi masing-masing variabel.
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('tips')
g = sns.pairplot(df, vars=['total_bill', 'tip', 'size'], hue='time',
palette={'Lunch': '#4C72B0', 'Dinner': '#DD8452'},
diag_kind='kde', plot_kws={'alpha': 0.6})
plt.show()Output:
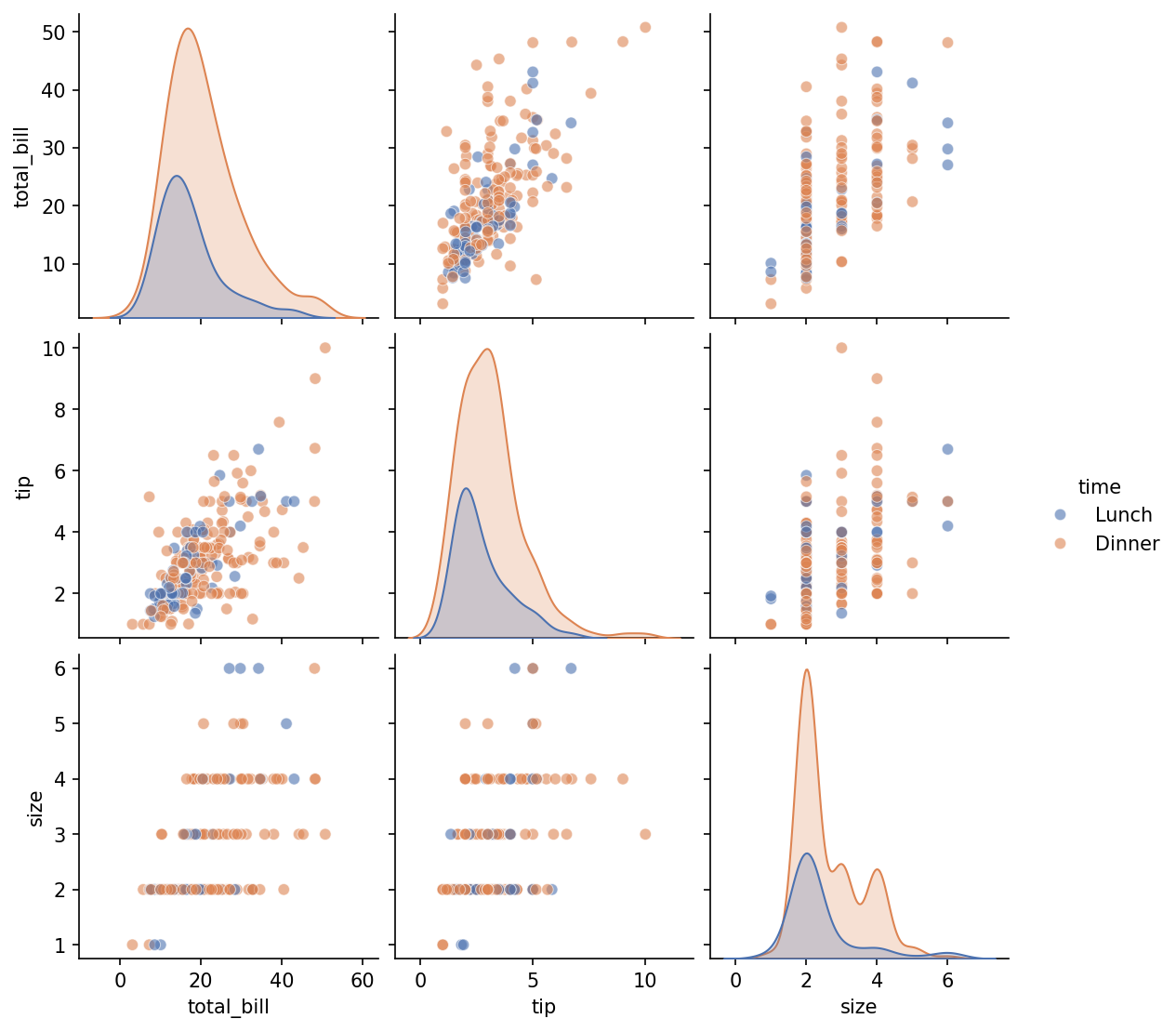
Parameter hue='time' memisahkan data berdasarkan waktu makan (Lunch vs Dinner), mengungkap perbedaan pola antar kategori secara visual. diag_kind='kde' menampilkan distribusi kontinu pada diagonal, lebih smooth dibanding histogram default.
Kustomisasi Matplotlib
Seaborn mengabstraksi banyak detail kustomisasi, namun Matplotlib tetap diperlukan untuk kontrol penuh. Beberapa teknik kustomisasi yang sering digunakan dalam laporan profesional.
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('tips')
# Set style global
sns.set_style('whitegrid')
fig, ax = plt.subplots(figsize=(10, 6))
sns.scatterplot(data=df, x='total_bill', y='tip', hue='time', style='smoker',
size='size', sizes=(30, 200), ax=ax, alpha=0.7)
ax.set_xlabel('Total Bill ($)', fontsize=12)
ax.set_ylabel('Tip ($)', fontsize=12)
ax.set_title('Tip Analysis: Multi-Dimensional View', fontsize=14, fontweight='bold')
ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.tight_layout()
plt.show()Output:
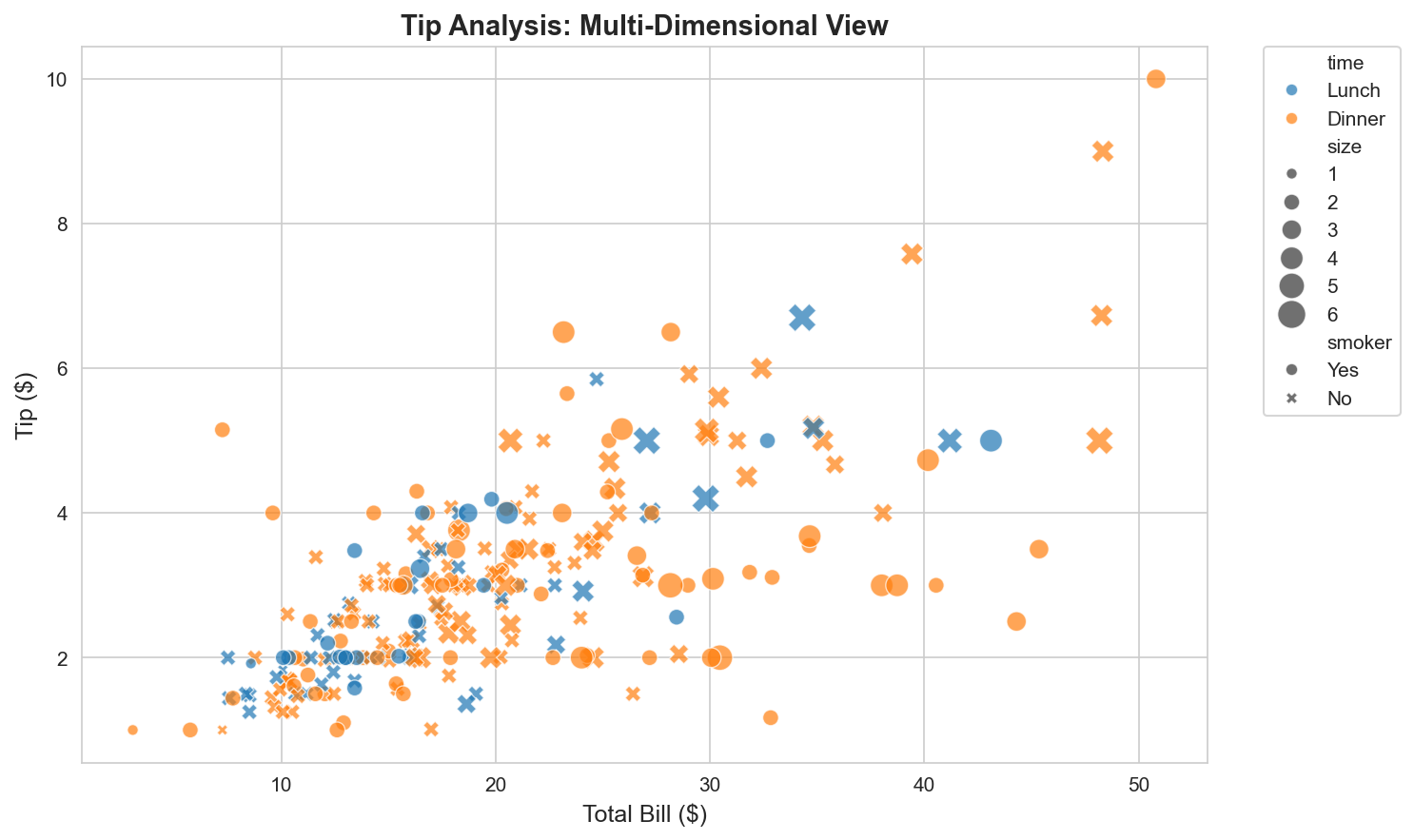
Plot di atas menggabungkan empat dimensi data dalam satu visualisasi: sumbu x (total_bill), sumbu y (tip), warna (time), dan ukuran marker (size). Pendekatan ini efektif untuk presentation karena satu grafik memberikan insight dari berbagai sudut sekaligus.
Best Practices Visualisasi EDA
Beberapa prinsip yang perlu diperhatikan saat membuat visualisasi untuk EDA: pilih jenis plot yang sesuai dengan tipe data (categorical vs numerical), gunakan palet warna yang konsisten, hindari clutter dengan membatasi jumlah variabel per plot, dan selalu tambahkan label sumbu serta judul yang deskriptif.
Matplotlib adalah fondasi yang memberikan kontrol penuh, sementara Seaborn mempercepat workflow dengan menyediakan statistical plot yang siap pakai. Kombinasi keduanya memungkinkan kita menghasilkan visualisasi yang informatif dan estetik tanpa menulis kode yang bertele-tele.
Mau menguasai teknik visualisasi data dan skill Data Science lainnya secara mendalam? Bergabunglah dengan Data Science Bootcamp di Rumah Coding. Kurikulum berbasis proyek nyata dengan bimbingan mentor berpengalaman.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model
Artikel Terkait

Time Series Decomposition dengan Python: Memisahkan Trend, Seasonal, dan Residual menggunakan Statsmodels

Memahami Konsep Korelasi dan Regresi Linear: Implementasi dengan Statsmodels untuk Analisis Hubungan Variabel
