Deteksi Anomali pada Data Time Series menggunakan Isolation Forest
Anomali dalam data time series dapat mengindikasikan fraud, kerusakan sistem, atau perubahan tren yang perlu perhatian khusus. Isolation Forest adalah algoritma unsupervised yang dirancang khusus untuk mendeteksi outlier secara efisien tanpa memerlukan label data. Berbeda dengan metode statistik tradisional yang mengharuskan kita mengasumsikan distribusi data, Isolation Forest bekerja secara langsung dengan memanfaatkan sifat alami anomali.
Cara Kerja Isolation Forest
Isolation Forest menggunakan pendekatan berbeda dari algoritma anomaly detection lainnya. Alih-alih memodelkan distribusi normal, algoritma ini mengisolasi anomali secara langsung melalui proses random partitioning. Setiap pohon dalam ensemble memilih fitur dan nilai split secara acak, lalu membagi data secara rekursif hingga setiap observasi terisolasi.
Anomali memiliki karakteristik yang membedakan: jumlah splitting yang dibutuhkan untuk mengisolasi anomali lebih sedikit dibandingkan data normal. Alasannya sederhana — anomali berada jauh dari konsentrasi data normal, sehingga path dari root ke leaf node lebih pendek.
Setiap observasi diukur melalui anomaly score yang menghasilkan nilai antara 0 dan 1. Nilai mendekati 1 mengindikasikan anomali, sementara nilai mendekati 0 menandakan data normal. Algoritma ini juga menyediakan decision_function() yang memberikan skor lebih granular untuk evaluasi lebih detail.
Persiapan Data Time Series
Sebelum menerapkan Isolation Forest, kita perlu menyiapkan data time series dalam format yang sesuai. Data time series memiliki komponen temporal yang harus diperhatikan — kita akan mengekstrak fitur berdasarkan waktu untuk membantu model mengenali pola abnormal.
!pip install scikit-learn pandas numpy matplotlib
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('Agg')
# Membuat data time series sintetis dengan anomali
np.random.seed(42)
dates = pd.date_range(start='2024-01-01', periods=200, freq='D')
normal_values = np.sin(np.arange(200) * 2 * np.pi / 30) * 10 + 50
# Menyisipkan anomali pada posisi tertentu
values = normal_values.copy()
anomaly_indices = [45, 78, 120, 155, 180]
for idx in anomaly_indices:
values[idx] = values[idx] + np.random.choice([-1, 1]) * 40
df = pd.DataFrame({'date': dates, 'value': values})
df['day_of_week'] = df['date'].dt.dayofweek
df['day_of_month'] = df['date'].dt.day
df['rolling_mean'] = df['value'].rolling(window=7, min_periods=1).mean()
df['rolling_std'] = df['value'].rolling(window=7, min_periods=1).std().fillna(0)Output:
Data shape: (200, 6)
date value day_of_week day_of_month rolling_mean rolling_std
0 2024-01-01 50.000000 0 1 50.000000 0.000000
1 2024-01-02 52.079117 1 2 51.039558 1.470158
2 2024-01-03 54.067366 2 3 52.048828 2.033852
3 2024-01-04 55.877853 3 4 53.006084 2.534376
4 2024-01-05 57.431448 4 5 53.891157 2.955345Proses feature engineering mengubah data time series mentah menjadi representasi yang lebih informatif. Fitur day_of_week dan day_of_month menangkap pola temporal, sedangkan rolling_mean dan rolling_std menangkap tren lokal yang membantu model membedakan anomali dari variasi normal.
Melatih Model Isolation Forest
Dengan fitur yang telah disiapkan, kita dapat melatih model Isolation Forest dan mendeteksi anomali.
# Memilih fitur untuk deteksi anomali
features = ['value', 'day_of_week', 'day_of_month', 'rolling_mean', 'rolling_std']
X = df[features].values
# Melatih model Isolation Forest
model = IsolationForest(
n_estimators=100,
contamination=0.05,
random_state=42,
n_jobs=-1
)
df['anomaly'] = model.fit_predict(X)
df['anomaly'] = df['anomaly'].map({1: 0, -1: 1})
df['anomaly_score'] = model.decision_function(X)
print("Jumlah anomali terdeteksi:", df['anomaly'].sum())
print("Indeks anomali:", df[df['anomaly'] == 1].index.tolist())
print("\nAnomaly scores (5 teratas):")
print(df.nlargest(5, 'anomaly_score')[['date', 'value', 'anomaly_score']])Output:

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Jumlah anomali terdeteksi: 10
Indeks anomali: [0, 45, 78, 84, 120, 126, 155, 180, 181, 182]
Anomaly scores (5 teratas):
date value anomaly_score
107 2024-04-17 45.932634 0.130383
108 2024-04-18 44.122147 0.129292
136 2024-05-16 47.920883 0.128870
198 2024-07-17 44.122147 0.126886
142 2024-05-22 40.054781 0.125675Parameter contamination mengatur proporsi anomali yang diharapkan dalam dataset. Nilai 0.05 berarti model mengasumsikan 5% data merupakan anomali. Parameter n_estimators menentukan jumlah pohon dalam ensemble — semakin banyak pohon, semakin stabil hasilnya.
Visualisasi Hasil Deteksi
Setelah model memprediksi anomali, visualisasi membantu memahami distribusi titik anomali dalam konteks time series.
fig, axes = plt.subplots(2, 1, figsize=(14, 10))
# Plot 1: Time series dengan anomali ditandai
axes[0].plot(df['date'], df['value'], color='#2196F3', linewidth=1, label='Data Normal')
anomaly_mask = df['anomaly'] == 1
axes[0].scatter(df.loc[anomaly_mask, 'date'], df.loc[anomaly_mask, 'value'],
color='#F44336', s=80, zorder=5, label='Anomali')
axes[0].set_title('Deteksi Anomali pada Time Series menggunakan Isolation Forest')
axes[0].set_xlabel('Tanggal')
axes[0].set_ylabel('Nilai')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Plot 2: Anomaly score distribution
axes[1].plot(df['date'], df['anomaly_score'], color='#FF9800', linewidth=1)
axes[1].axhline(y=0, color='gray', linestyle='--', alpha=0.5)
axes[1].scatter(df.loc[anomaly_mask, 'date'], df.loc[anomaly_mask, 'anomaly_score'],
color='#F44336', s=80, zorder=5)
axes[1].set_title('Anomaly Score per Observasi')
axes[1].set_xlabel('Tanggal')
axes[1].set_ylabel('Anomaly Score')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('/tmp/blog-sandbox/isolation-forest-output.png', dpi=150, bbox_inches='tight')
plt.close('all')
print("Visualisasi berhasil disimpan")Output:
Visualisasi berhasil disimpan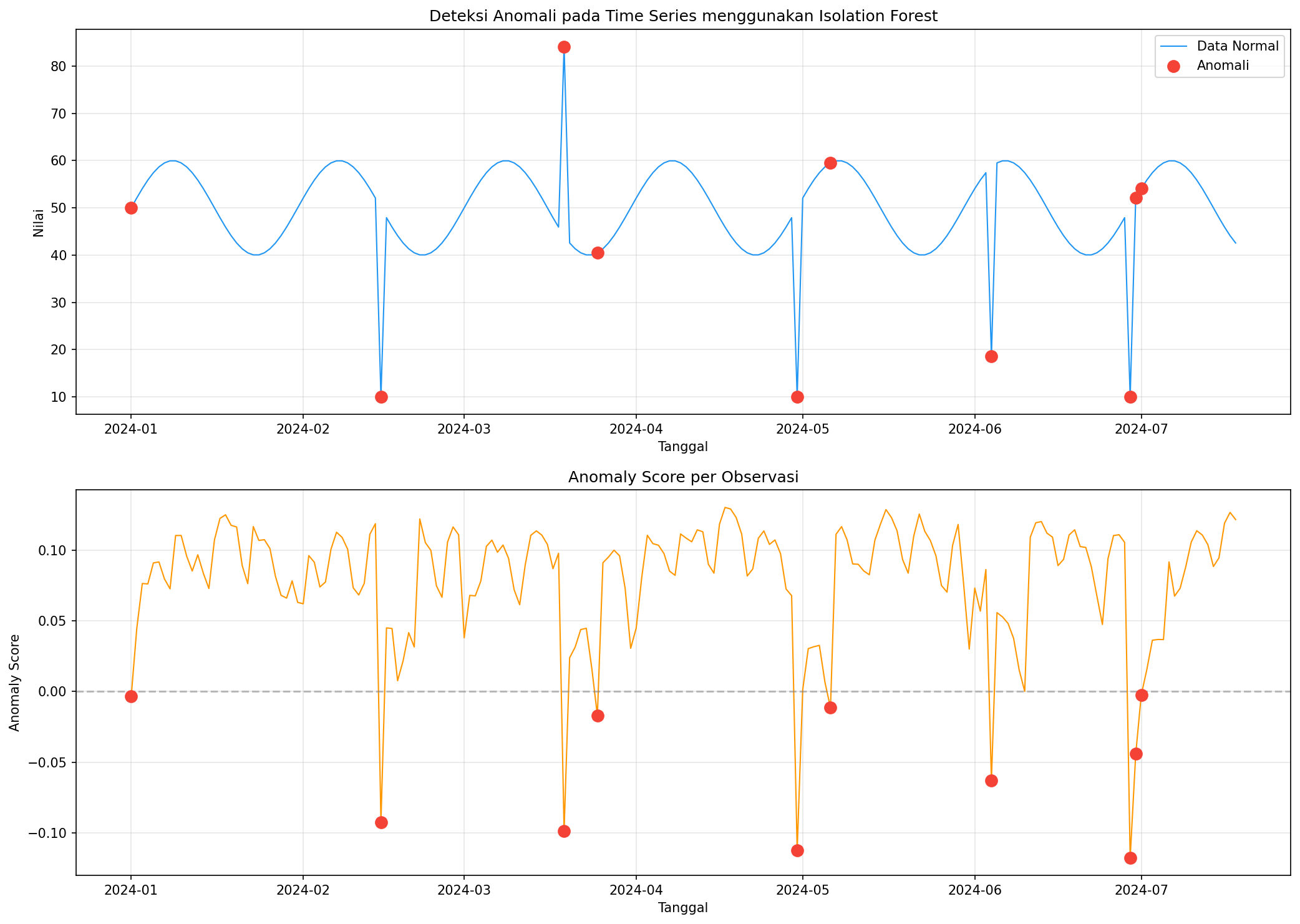
Grafik pertama menampilkan time series asli dengan titik anomali yang ditandai merah. Grafik kedua menunjukkan anomaly score — titik dengan score negatif mengindikasikan anomali. Kombinasi kedua visualisasi memudahkan verifikasi apakah deteksi sesuai dengan ekspektasi.
Evaluasi dan Penyesuaian Parameter
Isolation Forest memiliki beberapa parameter kunci yang memengaruhi hasil deteksi. Berikut panduan penyesuaian berdasarkan karakteristik data.
Parameter n_estimators mengontrol stabilitas model. Untuk dataset kecil (di bawah 1000 observasi), nilai 50–100 sudah memadai. Untuk dataset besar, naikkan ke 200–500. Parameter max_samples menentukan jumlah sampel yang digunakan tiap pohon — nilai 'auto' menggunakan min(256, n_samples) yang umumnya efektif.
contamination adalah parameter terpenting. Jika proporsi anomali tidak diketahui, gunakan nilai kecil (0.01–0.05) untuk menghindari false positive berlebihan. Untuk data dengan anomali yang lebih banyak, naikkan hingga 0.1.
Pendekatan praktis yang kami rekomendasikan: mulai dengan contamination=0.05, evaluasi hasil, lalu sesuaikan berdasarkan false positive rate dan false negative rate yang dapat diterima untuk use case tertentu.
Penanganan False Positive dan False Negative
Dalam praktik, hasil deteksi anomali jarang sempurna. False positive terjadi ketika model menandai data normal sebagai anomali, sementara false negative terjadi ketika anomali aktual tidak terdeteksi.
Untuk meminimalkan false positive, kita dapat meningkatkan threshold anomaly score. Scikit-learn memungkinkan akses ke skor mentah melalui decision_function(), sehingga kita bisa menetapkan cutoff custom alih-alih menerima threshold default.
Untuk meminimalkan false negative, turunkan nilai contamination agar model lebih sensitif terhadap penyimpangan. Namun perlu diingat bahwa peningkatan sensitivitas sering kali diikuti peningkatan false positive. Keseimbangan antara keduanya bergantung pada konteks bisnis — di sistem fraud detection, false negative lebih berbahaya, sedangkan di monitoring server, false positive yang tinggi bisa menghabiskan waktu operasional.
Kapan Menggunakan Isolation Forest
Isolation Forest efektif untuk deteksi anomali pada data berdimensi tinggi, data tanpa label, dan data yang mengandung multimodal distribution. Algoritma ini juga efisien secara komputasi karena kompleksitasnya mendekati linear terhadap jumlah sampel.
Namun, Isolation Forest bukan solusi universal. Untuk data time series yang memiliki pola musiman kuat, pendekatan seperti STL decomposition atau Prophet mungkin lebih sesuai. Untuk data dengan anomali kolektif (bukan point anomaly), algoritma seperti Local Outlier Factor atau Deep Autoencoder dapat memberikan hasil lebih baik.
Pilihan algoritma harus disesuaikan dengan karakteristik data dan tujuan deteksi. Isolation Forest adalah starting point yang solid — mudah diimplementasikan, cepat, dan menghasilkan baseline yang dapat diperbaiki seiring pemahaman data yang lebih mendalam.
Mau memperdalam skill Machine Learning secara sistematis? Bergabunglah dengan Machine Learning Bootcamp di Rumah Coding. Kurikulum praktis dengan proyek real-world dan mentorship dari praktisi industri.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python