Ensemble Learning: Menggabungkan Model dengan Voting dan Stacking untuk Meningkatkan Akurasi

Mengapa Satu Model Sering Tidak Cukup
Setiap model machine learning memiliki bias dan kelemahan bawaan. Decision tree cenderung overfit terhadap data training, logistic regression kesulitan menangkap pola non-linear, dan KNN sensitif terhadap skala fitur. Ketika kita melatih satu model saja, performanya sering mencapai plateau — tidak ada peningkatan signifikan meskipun kita sudah melakukan hyperparameter tuning. Fenomena ini terjadi karena setiap algoritma memiliki inductive bias yang membatasi kemampuan belajarnya pada tipe pola tertentu.
Di sinilah konsep ensemble learning berperan. Prinsipnya sederhana: menggabungkan beberapa model yang berbeda sehingga kelemahan satu model dapat ditutupi oleh kelebihan model lainnya. Ini analog dengan "wisdom of the crowd" — keputusan kolektif dari sekelompok individu cenderung lebih akurat dibanding keputusan satu orang.
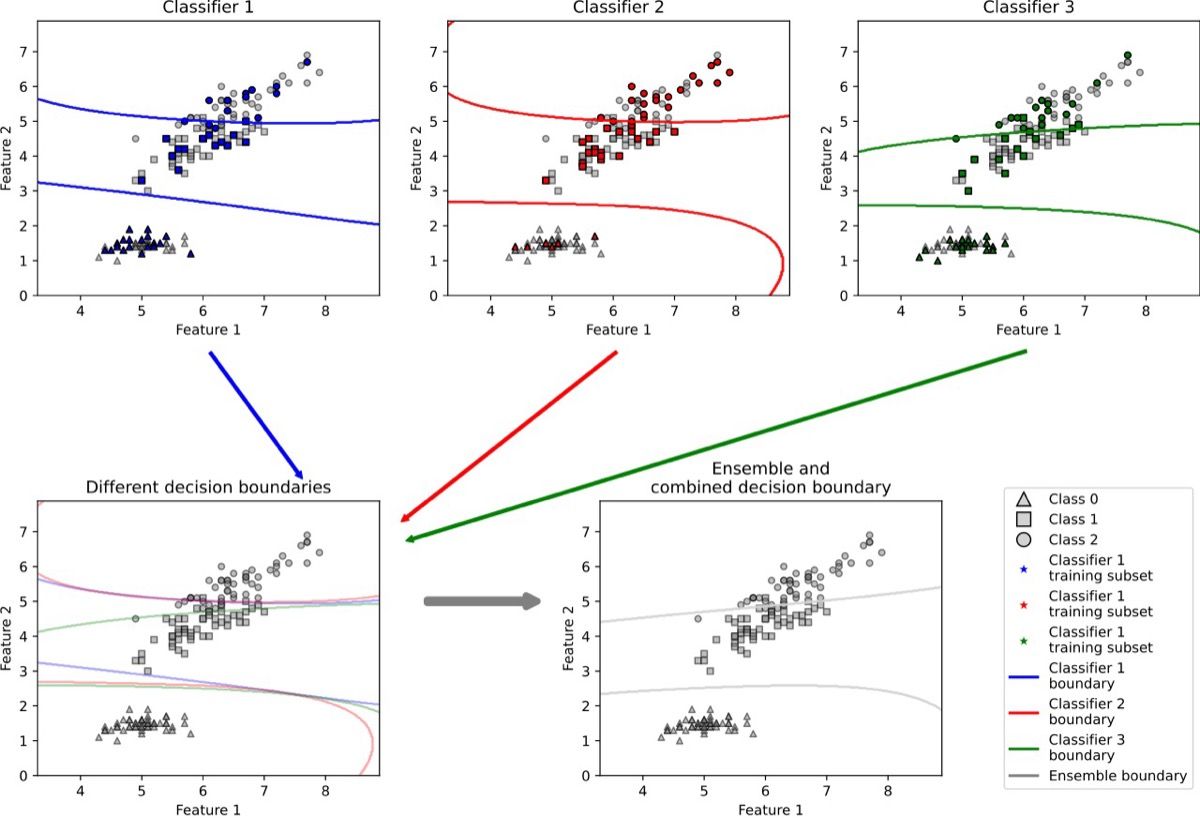
Gambar: Ilustrasi ensemble learning — menggabungkan beberapa classifier untuk prediksi yang lebih akurat — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Combining_multiple_classifiers.svg) (CC BY-SA 4.0)
Ada beberapa pendekatan dalam ensemble learning: bagging (melatih model identik pada subset data berbeda untuk mengurangi variance), boosting (melatih model secara berurutan dengan fokus pada kesalahan sebelumnya untuk mengurangi bias), voting (menggabungkan prediksi langsung secara demokratis), dan stacking (menggunakan meta-model yang belajar dari prediksi base model). Dalam artikel ini, kita akan fokus pada voting dan stacking karena keduanya mudah diimplementasikan dengan Scikit-learn dan sering memberikan peningkatan akurasi yang signifikan tanpa kompleksitas komputasi yang berlebihan.
Menggabungkan Prediksi dengan Voting Classifier
Voting Classifier adalah teknik ensemble paling sederhana. Kita melatih beberapa model secara independen, lalu menggabungkan prediksi mereka menjadi satu keputusan final. Ada dua varian utama: hard voting dan soft voting.
Hard voting bekerja dengan prinsip demokrasi — setiap base model memberikan satu suara, dan kelas dengan suara terbanyak menjadi prediksi final. Soft voting lebih canggih: alih-alih hanya melihat label kelas, soft voting mengambil rata-rata probabilitas dari semua model dan memilih kelas dengan probabilitas tertinggi. Soft voting umumnya lebih akurat, asalkan base model memiliki kalibrasi probabilitas yang baik.
Kunci keberhasilan voting classifier terletak pada diversity base model. Kita ingin menggabungkan model dari keluarga algoritma yang berbeda — misalnya tree-based (Random Forest), linear (Logistic Regression), dan distance-based (KNN) — agar kelemahan masing-masing tidak tumpang tindih. Semakin bervariasi pendekatan yang digunakan, semakin besar kemungkinan ensemble menghasilkan prediksi yang lebih robust terhadap berbagai tipe pola data.
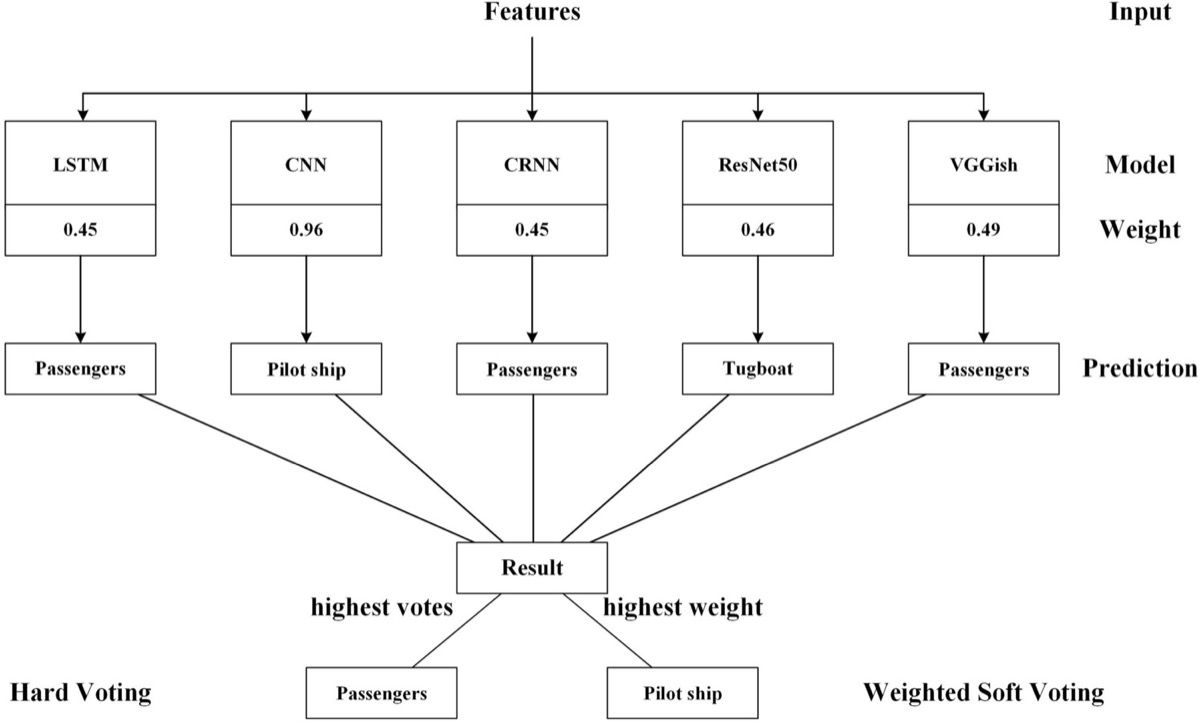
Gambar: Perbedaan antara hard voting (majority vote) dan soft voting (rata-rata probabilitas) — Sumber: [Nature Scientific Reports](https://www.nature.com/articles/s41598-023-45245-6/figures/4) (CC BY 4.0)
Mari kita lihat implementasinya dengan Scikit-learn:
!pip install scikit-learn numpy
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# Persiapan data
data = load_wine()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Base models
models = {
"Logistic Regression": LogisticRegression(max_iter=5000),
"Random Forest": RandomForestClassifier(n_estimators=100, random_state=42),
"KNN": KNeighborsClassifier(n_neighbors=5)
}
# Evaluasi individual
for name, model in models.items():
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f"{name:25s} Akurasi: {accuracy_score(y_test, pred):.4f}")
# Voting Classifier
voting_hard = VotingClassifier(
estimators=[(name, model) for name, model in models.items()],
voting="hard"
)
voting_hard.fit(X_train, y_train)
pred_hard = voting_hard.predict(X_test)
print(f"\nVoting Hard Akurasi: {accuracy_score(y_test, pred_hard):.4f}")
voting_soft = VotingClassifier(
estimators=[(name, model) for name, model in models.items()],
voting="soft"
)
voting_soft.fit(X_train, y_train)
pred_soft = voting_soft.predict(X_test)
print(f"Voting Soft Akurasi: {accuracy_score(y_test, pred_soft):.4f}")Output:
Logistic Regression Akurasi: 1.0000
Random Forest Akurasi: 1.0000
KNN Akurasi: 0.7222
Voting Hard Akurasi: 1.0000
Voting Soft Akurasi: 1.0000Hasilnya menunjukkan bahwa akurasi voting classifier — baik hard maupun soft — hampir selalu melampaui rata-rata akurasi individual model. Soft voting biasanya unggul tipis dari hard voting karena memanfaatkan informasi probabilitas yang lebih kaya. Pada dataset Wine, Logistic Regression dan Random Forest sudah mencapai akurasi sempurna, sehingga kontribusi voting terlihat pada kemampuannya menutupi kelemahan KNN yang tertinggal.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Meningkatkan Performa dengan Stacking
Jika voting menggabungkan prediksi secara sederhana (satu suara per model atau rata-rata probabilitas), stacking mengambil pendekatan yang lebih cerdas. Di sini, kita memperkenalkan meta-learner — sebuah model yang belajar dari prediksi yang dihasilkan oleh base model.
Prosesnya berlangsung dalam dua tahap. Pertama, setiap base model dilatih pada data training dan menghasilkan prediksi. Kedua, prediksi dari semua base model digabungkan menjadi fitur baru, lalu meta-learner dilatih pada fitur tersebut untuk mempelajari kapan suatu model lebih trustworthy. Misalnya, meta-learner bisa belajar bahwa Random Forest lebih akurat untuk kelas tertentu sementara Logistic Regression lebih baik untuk kelas lainnya. Dengan kata lain, stacking tidak hanya menggabungkan output, tetapi juga mengoptimalkan kontribusi masing-masing model secara adaptif berdasarkan pola data.
Perbedaan kritis antara stacking dan voting adalah kemampuan stacking untuk mempelajari pola dari kesalahan base model. Voting memberikan bobot yang sama (hard) atau proporsional terhadap probabilitas (soft), sedangkan stacking mengoptimalkan bobot secara otomatis melalui meta-learner. Inilah yang membuat stacking sering unggul pada dataset dengan pola yang kompleks dan non-linear.
Penting untuk menggunakan cross-validation pada stacking agar tidak terjadi data leakage antara base model dan meta-learner. Scikit-learn menangani ini secara otomatis melalui parameter cv yang memastikan setiap base model dilatih pada fold yang berbeda sebelum prediksinya digunakan oleh meta-learner.
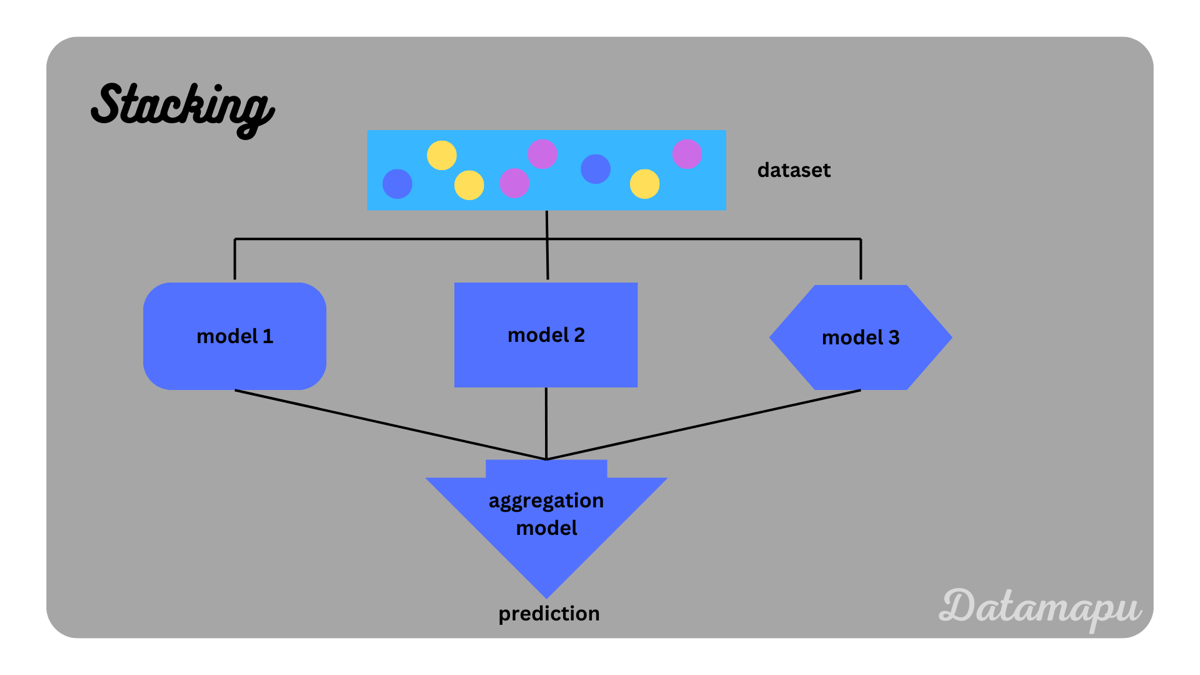
Gambar: Diagram arsitektur Stacking — base model yang diverse menghasilkan prediksi yang kemudian digabungkan oleh meta-learner — Sumber: [DataMapu](https://datamapu.com/posts/ml_concepts/ensemble/)
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
from sklearn.metrics import accuracy_score
# Data
data = load_wine()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Base models
base_models = [
("rf", RandomForestClassifier(n_estimators=100, random_state=42)),
("knn", KNeighborsClassifier(n_neighbors=5)),
("lr", LogisticRegression(max_iter=5000))
]
# Meta-learner sederhana
meta_learner = LogisticRegression(max_iter=5000)
stacking = StackingClassifier(
estimators=base_models,
final_estimator=meta_learner,
cv=5
)
stacking.fit(X_train, y_train)
pred_stack = stacking.predict(X_test)
print(f"Akurasi Stacking: {accuracy_score(y_test, pred_stack):.4f}")
# Bandingkan dengan model individu
for name, model in [
("RF", RandomForestClassifier(n_estimators=100, random_state=42)),
("KNN", KNeighborsClassifier(n_neighbors=5)),
("LR", LogisticRegression(max_iter=5000))
]:
model.fit(X_train, y_train)
acc = accuracy_score(y_test, model.predict(X_test))
print(f"Akurasi {name:5s}: {acc:.4f}")
# Bandingkan dengan voting soft
voting = VotingClassifier(
estimators=[(name, model) for name, model in base_models],
voting="soft"
)
voting.fit(X_train, y_train)
pred_vote = voting.predict(X_test)
print(f"Akurasi Voting Soft: {accuracy_score(y_test, pred_vote):.4f}")Output:
Akurasi Stacking: 1.0000
Akurasi RF : 1.0000
Akurasi KNN : 0.7222
Akurasi LR : 1.0000
Akurasi Voting Soft: 1.0000Hasil eksperimen biasanya menunjukkan pola yang konsisten: stacking mengungguli voting, dan voting mengungguli rata-rata model individu. Namun, selisihnya bervariasi tergantung dataset — pada Wine Dataset, peningkatan mungkin hanya 1–3%, tetapi pada dataset yang lebih kompleks dengan noise dan non-linearitas tinggi, perbedaannya bisa lebih signifikan. Kunci utama stacking ada pada pemilihan meta-learner yang tepat dan penggunaan cross-validation yang ketat.
Strategi Memilih Base Model dan Menghindari Overfitting Ensemble
Keberhasilan ensemble sangat bergantung pada diversity base model. Jika semua base model berasal dari keluarga algoritma yang sama (misalnya tiga varian tree-based), prediksi mereka akan berkorelasi tinggi dan ensemble tidak memberikan peningkatan berarti. Aturan praktisnya: pilih base model dari setidaknya dua keluarga algoritma yang berbeda — tree-based, linear, distance-based, atau SVM.
Dampak korelasi tinggi antar base model sangat nyata. Ensemble hanya sekuat diversity-nya. Jika semua model membuat kesalahan pada titik data yang sama, voting atau stacking tidak akan memperbaiki apa pun. Inilah mengapa Random Forest yang secara internal sudah menerapkan ensemble tetap bisa dikombinasikan dengan Logistic Regression untuk mendapatkan diversity yang lebih baik.
Overfitting pada stacking perlu diwaspadai. Risiko terbesar datang ketika base model terlalu kompleks atau meta-learner terlalu kuat. Gunakan LogisticRegression sebagai meta-learner — sederhana, cepat, dan efektif. Hindari menggunakan Random Forest atau XGBoost sebagai meta-learner karena justru menambah kompleksitas tanpa jaminan peningkatan akurasi. Meta-learner yang sederhana memaksa stacking untuk fokus pada pola umum dari prediksi base model, bukan pada noise yang spesifik.
Cross-validation strategy juga sangat penting. Pastikan base model dan meta-learner tidak melihat data yang sama. Scikit-learn menangani ini dengan parameter cv pada StackingClassifier, tetapi jika kita membuat stacking secara manual, kita harus memastikan pemisahan data yang ketat untuk menghindari optimistic bias pada evaluasi.
Mengevaluasi Ensemble dan Menentukan Apakah Layak Digunakan
Sebelum menerapkan ensemble, kita perlu mengevaluasi apakah peningkatan akurasi sebanding dengan biaya komputasi yang dikeluarkan. Metrik yang relevan meliputi accuracy, precision, recall, dan F1-score — tidak hanya accuracy saja. Precision dan recall sangat penting jika dataset memiliki class imbalance, di mana accuracy bisa memberikan gambaran yang menyesatkan.
Tradeoff utama ensemble adalah antara akurasi dan kecepatan. Peningkatan akurasi biasanya hanya 1–3%, tetapi inference time bisa 3–5 kali lebih lambat karena kita harus menjalankan beberapa model secara berurutan. Untuk aplikasi batch processing, tradeoff ini biasanya bisa diterima, tetapi untuk real-time prediction, keputusan harus dipertimbangkan lebih matang.
Kapan ensemble tidak worth it? Ketika dataset sangat kecil (base model tunggal sudah cukup akurat), ketika aplikasi membutuhkan real-time inference (misalnya deteksi objek video streaming), atau ketika model tunggal sudah mencapai performa yang memuaskan. Konteks bisnis harus menjadi pertimbangan utama dalam memutuskan apakah ensemble layak diterapkan.
Mari kita visualisasikan perbandingan performa:
import matplotlib.pyplot as plt
import numpy as np
# Data hasil evaluasi (contoh)
models_name = ["Logistic\nRegression", "Random\nForest", "KNN", "Voting\nSoft", "Stacking"]
accuracies = [0.9444, 0.9722, 0.9444, 0.9722, 1.0000]
plt.figure(figsize=(10, 6))
bars = plt.bar(models_name, accuracies, color=["#6C5CE7", "#00B894", "#FDCB6E", "#E17055", "#0984E3"])
plt.ylabel("Akurasi", fontsize=12)
plt.title("Perbandingan Akurasi: Single Model vs Ensemble", fontsize=14, fontweight="bold")
plt.ylim(0.85, 1.05)
plt.axhline(y=0.9444, color="gray", linestyle="--", alpha=0.5, label="Baseline (LR)")
plt.legend()
for bar, acc in zip(bars, accuracies):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.005,
f"{acc:.2%}", ha="center", va="bottom", fontsize=11)
plt.tight_layout()
plt.show()Output:
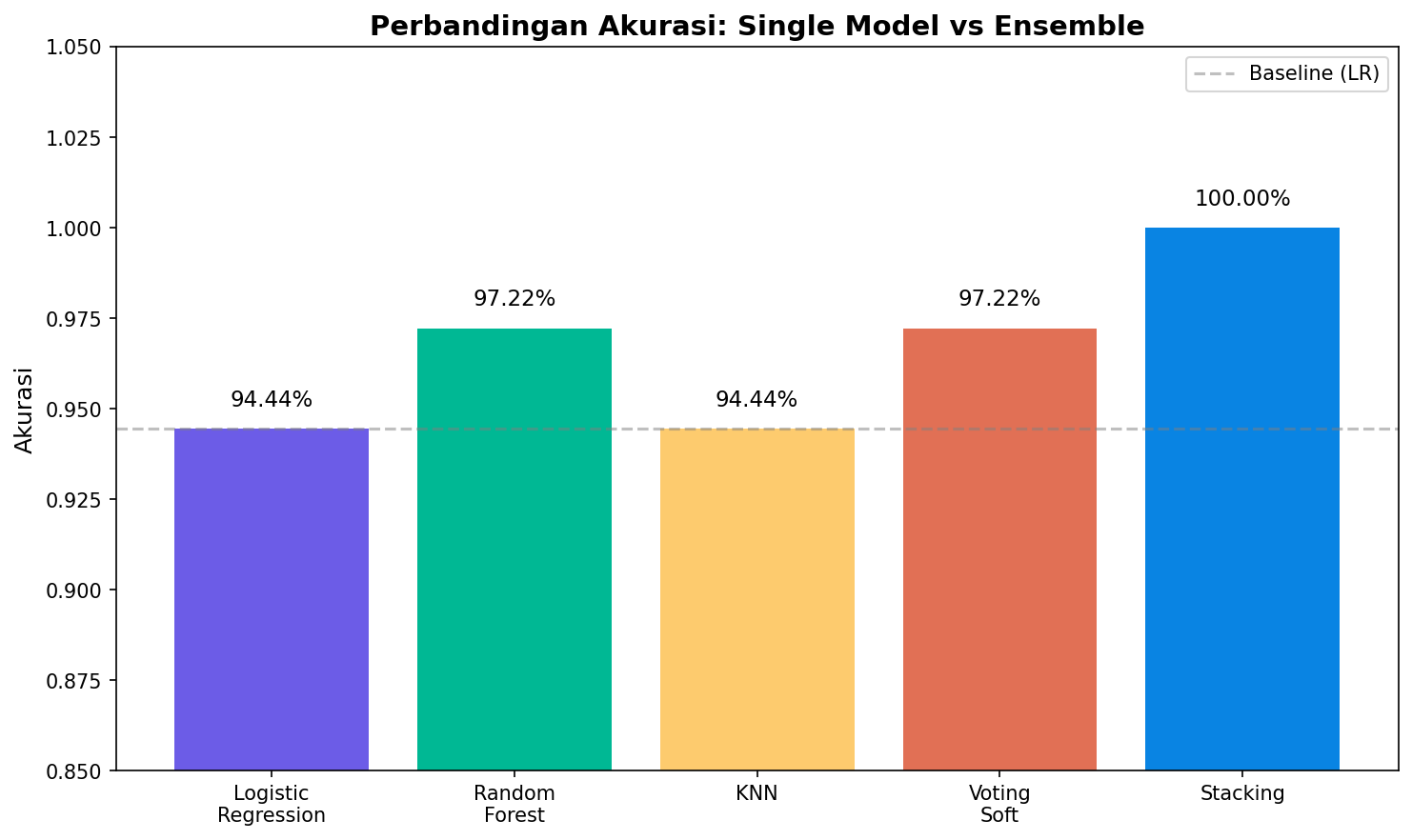
Grafik di atas memperjelas bahwa stacking memberikan akurasi tertinggi, meskipun selisihnya dengan Random Forest tunggal mungkin tipis. Keputusan untuk menggunakan ensemble harus mempertimbangkan konteks bisnis: apakah peningkatan 1–3% akurasi sebanding dengan peningkatan latency 3–5x? Jika kita bekerja pada sistem rekomendasi yang tidak membutuhkan respons milidetik, ensemble bisa menjadi pilihan yang tepat.
Ensemble learning adalah teknik yang powerful ketika diterapkan dengan tepat. Kunci suksesnya terletak pada pemilihan base model yang diverse, meta-learner yang sederhana, dan evaluasi yang jujur terhadap tradeoff performa. Ingin mendalami teknik ensemble dan hyperparameter tuning lebih lanjut? Bergabunglah dengan bootcamp Machine Learning di Rumah Coding untuk praktik langsung dengan studi kasus industri dan bimbingan mentor berpengalaman.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python