Memahami Algoritma Decision Tree dan Implementasinya dengan Scikit-learn untuk Masalah Klasifikasi
Apa Itu Decision Tree dan Bagaimana Cara Kerjanya
Decision Tree adalah algoritma supervised learning yang bekerja dengan cara membagi data secara rekursif berdasarkan nilai fitur tertentu hingga mencapai suatu keputusan. Struktur dari decision tree menyerupai diagram pohon: root node di puncak mewakili seluruh dataset, internal node mewakili kondisi atau pengujian terhadap suatu fitur, dan leaf node mewakili keputusan akhir berupa kelas prediksi.
Proses pembagian ini dilakukan dengan memilih fitur yang paling informatif pada setiap percabangan. Algoritma akan mengevaluasi seluruh fitur yang tersedia, lalu memilih satu fitur yang paling mampu memisahkan data ke dalam kelas-kelas yang berbeda. Percabangan ini berlangsung terus hingga mencapai kriteria berhenti, seperti kedalaman maksimum pohon atau jumlah minimum sampel di sebuah node.
Salah satu keunggulan utama decision tree adalah interpretability — kita dapat melacak alur pengambilan keputusan dari root hingga leaf dengan jelas. Hal ini membuat decision tree menjadi pilihan populer untuk domain yang membutuhkan transparansi tinggi, seperti diagnosis medis atau analisis risiko kredit.
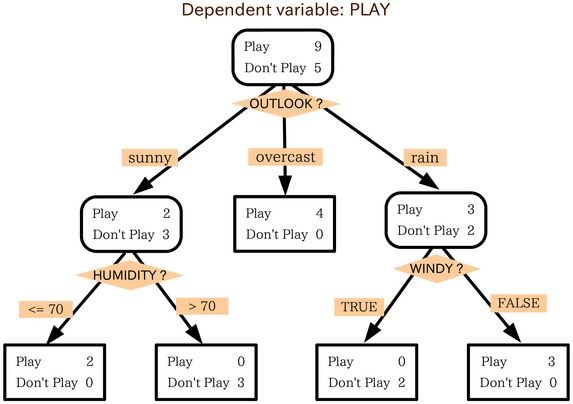
Gambar: Diagram struktur Decision Tree — Sumber: [Wikipedia](https://en.wikipedia.org/wiki/File:Decision_tree_model.png)
Kriteria Splitting — Information Gain dan Gini Impurity
Untuk menentukan fitur mana yang paling optimal dijadikan cabang, decision tree menggunakan metrik ketidakmurnian (impurity). Dua metrik yang paling umum digunakan adalah Gini Impurity dan Information Gain (berbasis Entropy).
Gini Impurity mengukur seberapa sering suatu elemen yang dipilih secara acak dari dataset akan salah diklasifikasikan jika labelnya ditentukan secara acak berdasarkan distribusi kelas di node tersebut. Nilai Gini berkisar antara 0 (semua sampel dalam satu kelas) hingga 0.5 (distribusi sempurna antar kelas untuk dataset biner). Semakin rendah nilai Gini, semakin baik kualitas split.
Information Gain menggunakan konsep Entropy dari teori informasi. Entropy mengukur tingkat ketidakpastian dalam data. Information Gain dihitung sebagai selisih entropy sebelum dan sesudah split. Semakin besar nilai Information Gain, semakin baik fitur tersebut dalam memisahkan data.
Di Scikit-learn, parameter criterion pada DecisionTreeClassifier menerima nilai "gini" (default) atau "entropy". Dalam praktiknya, perbedaan performa antara keduanya sering kali kecil, tetapi Gini Impurity cenderung lebih cepat secara komputasi karena tidak melibatkan perhitungan logaritma.
Gambar: Decision Tree sederhana untuk ilustrasi Information Gain — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:A_simple_Decision_Tree.png)
Mari kita lihat perhitungan Gini Impurity secara manual untuk memperkuat pemahaman:
!pip install numpy
import numpy as np
def gini_impurity(classes):
total = len(classes)
if total == 0:
return 0
counts = np.bincount(classes)
probabilities = counts / total
return 1 - np.sum(probabilities ** 2)
# Contoh: 3 kelas A, 2 kelas B
samples = np.array([0, 0, 0, 1, 1])
print(f"Gini Impurity: {gini_impurity(samples):.4f}")Output:

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Gini Impurity: 0.4800Semakin tinggi nilai Gini Impurity, semakin tidak murni suatu node. Algoritma akan memilih fitur yang menghasilkan penurunan Gini terbesar setelah split.
Implementasi Decision Tree Classifier dengan Scikit-learn
Setelah memahami konsep dasarnya, mari kita implementasikan decision tree untuk klasifikasi menggunakan dataset Iris. Kita akan membangun model, melatihnya, lalu mengevaluasi performanya.
!pip install scikit-learn pandas numpy
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix
import pandas as pd
# Load dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# Split data: 70% training, 30% testing
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# Buat dan latih model Decision Tree
model = DecisionTreeClassifier(criterion="gini", random_state=42)
model.fit(X_train, y_train)
# Prediksi dan evaluasi
y_pred = model.predict(X_test)
print("=== Classification Report ===")
print(classification_report(y_test, y_pred, target_names=target_names))
print("\n=== Confusion Matrix ===")
print(confusion_matrix(y_test, y_pred))Output:
=== Classification Report ===
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.80 0.89 15
virginica 0.83 1.00 0.91 15
accuracy 0.93 45
macro avg 0.94 0.93 0.93 45
weighted avg 0.94 0.93 0.93 45
=== Confusion Matrix ===
[[15 0 0]
[ 0 12 3]
[ 0 0 15]]Dalam implementasi di atas, kita menggunakan random_state=42 untuk memastikan hasil yang konsisten setiap kali kode dijalankan. Parameter stratify=y pada train_test_split menjaga proporsi kelas tetap sama antara data training dan testing.
Decision tree yang kita latih akan mempelajari pola dari data training dengan cara membangun serangkaian aturan if-else berdasarkan nilai fitur. Misalnya, jika petal length ≤ 2.45 cm, maka sampel diklasifikasikan sebagai setosa. Jika tidak, algoritma akan melanjutkan ke pemeriksaan fitur berikutnya hingga mencapai leaf node.
Mengatasi Overfitting dengan Hyperparameter Tuning
Meskipun decision tree mudah diinterpretasi, algoritma ini memiliki kelemahan utama: overfitting. Tanpa batasan, pohon dapat tumbuh hingga setiap sampel berada di leaf yang terpisah, menghafal noise dalam data training dan gagal melakukan generalisasi pada data baru.
Scikit-learn menyediakan beberapa hyperparameter untuk mengendalikan kompleksitas pohon:
max_depth: Membatasi kedalaman maksimum pohon. Semakin dalam pohon, semakin spesifik aturan yang dipelajari.min_samples_split: Jumlah minimum sampel yang diperlukan untuk melakukan split. Nilai yang lebih tinggi mencegah split pada kelompok kecil yang mungkin merupakan noise.min_samples_leaf: Jumlah minimum sampel yang harus ada di leaf node. Efeknya mirip denganmin_samples_split, tetapi lebih ketat karena berlaku pada hasil split.
Mari kita lihat perbandingan akurasi training dan testing pada berbagai nilai max_depth:
!pip install scikit-learn matplotlib numpy
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.3, random_state=42
)
depths = range(1, 11)
train_scores = []
test_scores = []
for depth in depths:
model = DecisionTreeClassifier(max_depth=depth, random_state=42)
model.fit(X_train, y_train)
train_scores.append(model.score(X_train, y_train))
test_scores.append(model.score(X_test, y_test))
print("Depth | Train Acc | Test Acc")
print("-" * 35)
for d, tr, te in zip(depths, train_scores, test_scores):
print(f" {d:2d} | {tr:.3f} | {te:.3f}")Output:
Depth | Train Acc | Test Acc
-----------------------------------
1 | 0.648 | 0.711
2 | 0.943 | 0.978
3 | 0.952 | 1.000
4 | 0.971 | 1.000
5 | 0.990 | 1.000
6 | 1.000 | 1.000
7 | 1.000 | 1.000
8 | 1.000 | 1.000
9 | 1.000 | 1.000
10 | 1.000 | 1.000Dari hasil perbandingan tersebut, kita akan melihat bahwa pada max_depth yang kecil, model belum mampu menangkap pola secara optimal (underfitting). Seiring bertambahnya kedalaman, akurasi training terus meningkat hingga mencapai 100%, tetapi akurasi testing bisa menurun jika pohon terlalu dalam — inilah tanda overfitting. Titik optimal biasanya terletak di area di mana akurasi testing mencapai puncak sebelum mulai menurun.
Proses membatasi pertumbuhan pohon ini sering disebut pruning. Analoginya sederhana: seperti memotong cabang pohon yang tidak perlu agar nutrisi terfokus pada cabang utama, pruning pada decision tree membuang split yang tidak berkontribusi signifikan terhadap generalisasi.
Kelebihan, Kekurangan, dan Kapan Menggunakan Decision Tree
Decision tree memiliki sejumlah kelebihan yang membuatnya tetap relevan di era algoritma ensemble. Pertama, interpretability — kita dapat memvisualisasikan pohon dan menjelaskan logika prediksi kepada pemangku kepentingan non-teknis. Kedua, decision tree tidak memerlukan scaling fitur, sehingga kita bisa langsung menggunakan data mentah tanpa normalisasi atau standarisasi. Ketiga, algoritma ini mampu menangani campuran data numerik dan kategorikal secara alami.
Namun, decision tree juga memiliki kekurangan yang signifikan. Algoritma ini rentan terhadap overfitting, terutama jika tidak dibatasi dengan hyperparameter pruning. Decision tree juga memiliki variance tinggi — perubahan kecil pada data training dapat menghasilkan pohon yang sangat berbeda. Selain itu, decision tree cenderung bias terhadap fitur dengan jumlah kategori yang banyak.
Meskipun demikian, decision tree tetap menjadi pilihan yang tepat ketika explainability adalah prioritas utama. Untuk dataset kecil hingga menengah, decision tree yang di-pruning dengan baik dapat memberikan performa yang kompetitif. Decision tree juga berfungsi sebagai base learner yang sangat baik untuk algoritma ensemble seperti Random Forest dan Gradient Boosting — di situlah kekuatan sebenarnya dari decision tree sering dimanfaatkan.
Mulailah bereksperimen dengan decision tree pada dataset Anda sendiri. Bootcamp Machine Learning di Rumah Coding membahas Decision Tree, Random Forest, dan XGBoost secara mendalam — dari konsep hingga implementasi proyek nyata.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python