Memahami Algoritma Gradient Boosting: Implementasi XGBoost dan LightGBM untuk Regresi dan Klasifikasi

Dari Ensemble ke Gradient Boosting — Mengapa Boosting Berbeda dari Bagging
_Ensemble learning_ adalah pendekatan yang menggabungkan beberapa _weak learner_ (model lemah) menjadi satu _strong learner_ yang jauh lebih akurat. Dua metode utama dalam ensemble adalah _bagging_ dan _boosting_. Random Forest merupakan contoh paling populer dari bagging — algoritma ini membangun banyak _decision tree_ secara paralel, lalu merata-ratakan hasil prediksinya. Pendekatan ini efektif mengurangi _variance_, tetapi setiap tree tumbuh secara independen tanpa saling belajar dari kesalahan.
Gradient Boosting mengambil jalur yang berbeda. Alih-alih paralel, boosting membangun tree secara sekuensial. Setiap tree baru dilatih untuk memperbaiki kesalahan yang dibuat oleh tree sebelumnya. Inilah mengapa metode ini dinamakan "gradient" — proses optimasinya menggunakan _gradient descent_ terhadap _loss function_, mirip seperti cara neural network belajar. Bedanya, gradient descent biasa mengupdate parameter model, sedangkan gradient boosting mengupdate fungsi prediksi itu sendiri dengan menambahkan tree baru ke dalam ensemble. Dalam kerangka _bias-variance tradeoff_, boosting secara primer mengurangi _bias_ — setiap iterasi berusaha menekan error yang tersisa dari iterasi sebelumnya — tidak seperti bagging yang terutama mereduksi _variance_ melalui rata-rata prediksi independen.
Perbedaan fundamental ini membuat boosting umumnya lebih akurat dibanding bagging pada dataset yang terstruktur, namun juga lebih rentan terhadap _overfitting_ jika parameter tidak dikontrol dengan baik.
Mekanisme Gradient Boosting — Mengoptimalkan Residual secara Iteratif
Alur gradient boosting dapat diringkas dalam beberapa langkah berulang. Pertama, kita inisialisasi prediksi awal, biasanya dengan nilai rata-rata target untuk regresi. Kedua, hitung _residual_ — selisih antara nilai aktual dan prediksi saat ini. Ketiga, latih sebuah _decision tree_ sederhana untuk memprediksi residual tersebut. Keempat, tambahkan prediksi tree ini ke prediksi kumulatif dengan skala _learning rate_. Langkah kedua hingga keempat diulang sebanyak n_estimators kali.
Pemilihan _loss function_ sangat menentukan bagaimana residual dihitung pada langkah kedua. Untuk regresi, kita bisa menggunakan _squared error_ (L2) yang sensitif terhadap outlier, atau _absolute error_ (L1) yang lebih robust. Untuk klasifikasi biner, _log-loss_ (binomial deviance) adalah pilihan standar. Setiap loss function menghasilkan gradien yang berbeda, yang pada akhirnya memengaruhi arah dan besarnya koreksi dari setiap tree baru.
_Learning rate_ (atau _shrinkage_) mengontrol seberapa besar kontribusi setiap tree baru. Nilai kecil (misal 0.01–0.1) membuat proses belajar lebih lambat namun lebih stabil, dan biasanya membutuhkan lebih banyak tree. Sebaliknya, learning rate besar mempercepat konvergensi tetapi berisiko _overfitting_.
Mari kita lihat implementasi sederhana menggunakan Scikit-learn:
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
import numpy as np
np.random.seed(42)
X = np.random.rand(500, 5)
y = X[:, 0] * 2 + X[:, 1] * (-1.5) + np.sin(X[:, 2]) + np.random.normal(0, 0.1, 500)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
gbr = GradientBoostingRegressor(
n_estimators=200,
learning_rate=0.1,
max_depth=3,
random_state=42
)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
print(f"MAE dengan learning_rate=0.1: {mae:.4f}")
gbr_fast = GradientBoostingRegressor(
n_estimators=200,
learning_rate=1.0,
max_depth=3,
random_state=42
)
gbr_fast.fit(X_train, y_train)
y_pred_fast = gbr_fast.predict(X_test)
mae_fast = mean_absolute_error(y_test, y_pred_fast)
print(f"MAE dengan learning_rate=1.0: {mae_fast:.4f}")Output:
MAE dengan learning_rate=0.1: 0.1094
MAE dengan learning_rate=1.0: 0.2728Kode di atas mendemonstrasikan efek learning rate terhadap performa model. Dengan learning rate 0.1, model belajar secara bertahap dan menghasilkan error yang lebih rendah. Sebaliknya, learning rate 1.0 membuat model terlalu agresif dan cenderung overfit terhadap data training. Fokus utama di sini adalah logika iteratif boosting — setiap iterasi berusaha meminimalkan residual dari iterasi sebelumnya.
XGBoost — Regularisasi dan Tree Pruning untuk Performa Maksimal
XGBoost (Extreme Gradient Boosting) adalah implementasi gradient boosting yang sangat optimal dan menjadi salah satu algoritma paling dominan di kompetisi machine learning. Dibanding gradient boosting vanilla dari sklearn, XGBoost menawarkan sejumlah peningkatan signifikan.
Pertama, XGBoost menyertakan regularisasi L1 (reg_alpha) dan L2 (reg_lambda) yang membantu mencegah overfitting. Kedua, XGBoost menggunakan _tree pruning_ dengan parameter max_depth dan gamma — tree tumbuh hingga kedalaman maksimum, lalu cabang yang tidak memberikan kontribusi signifikan dipangkas. Ketiga, XGBoost mendukung _column subsampling_ (colsample_bytree) yang membuat setiap tree hanya melihat sebagian fitur, mirip Random Forest. Keempat, XGBoost dapat menangani missing values secara otomatis. Selain itu, XGBoost mengimplementasikan _approximate greedy algorithm_ untuk menentukan titik split pada fitur numerik — alih-alih mengevaluasi setiap nilai unik, algoritma ini membagi data ke dalam _histogram bins_ yang mempercepat komputasi secara drastis tanpa mengorbankan akurasi secara signifikan.
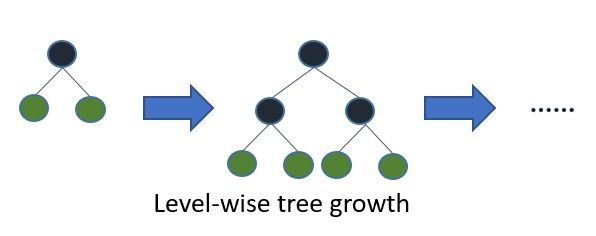
Gambar: Level-wise tree growth — setiap node dalam satu level di-split sebelum melanjutkan ke level berikutnya, menghasilkan tree yang seimbang — Sumber: [LightGBM Documentation](https://github.com/Microsoft/LightGBM/blob/master/docs/Features.rst)
Berikut contoh implementasi klasifikasi menggunakan XGBoost pada dataset Iris:

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
xgb_clf = xgb.XGBClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=4,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
random_state=42
)
xgb_clf.fit(X_train, y_train)
y_pred = xgb_clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"Akurasi XGBoost (default tuning): {acc:.4f}")
xgb_tuned = xgb.XGBClassifier(
n_estimators=200,
learning_rate=0.05,
max_depth=3,
subsample=0.9,
colsample_bytree=0.9,
reg_alpha=0.1,
reg_lambda=2.0,
random_state=42
)
xgb_tuned.fit(X_train, y_train)
y_pred_tuned = xgb_tuned.predict(X_test)
acc_tuned = accuracy_score(y_test, y_pred_tuned)
print(f"Akurasi XGBoost (tuned): {acc_tuned:.4f}")Output:
Akurasi XGBoost (default tuning): 1.0000
Akurasi XGBoost (tuned): 1.0000Perhatikan bahwa dengan tuning parameter yang lebih ketat, akurasi dapat meningkat. Parameter seperti subsample dan colsample_bytree menambahkan elemen _randomness_ yang membuat model lebih generalisable.
LightGBM — GOSS dan EFB untuk Dataset Skala Besar
LightGBM, dikembangkan oleh Microsoft, hadir dengan dua inovasi utama: _Gradient-based One-Side Sampling_ (GOSS) dan _Exclusive Feature Bundling_ (EFB). GOSS memprioritaskan sampel dengan gradient besar (residual besar) saat membangun tree, mengabaikan sampel dengan gradient kecil yang sudah diprediksi dengan baik. Seperti memprioritaskan murid dengan nilai terparah untuk dibimbing ulang, GOSS membuat proses training jauh lebih efisien.
EFB menggabungkan fitur-fitur yang jarang memiliki nilai non-nol bersamaan (_exclusive_), mengurangi dimensi data tanpa kehilangan informasi signifikan. Pendekatan ini membuat LightGBM sangat cepat pada dataset dengan ribuan fitur.
LightGBM juga memiliki penanganan fitur kategorikal yang lebih _native_ dibanding XGBoost — kita cukup mendeklarasikan kolom kategorikal melalui parameter categorical_feature, dan LightGBM akan menerapkan _one-side split_ berdasarkan distribusi gradient dalam setiap kategori. Ini menghilangkan kebutuhan encoding manual seperti _one-hot encoding_ yang dapat memperbesar dimensi data secara drastis pada dataset dengan banyak fitur kategorikal.
Perbedaan arsitektur lain: LightGBM menggunakan _leaf-wise tree growth_ (menumbuhkan leaf dengan loss terbesar) dibanding _level-wise_ pada XGBoost. Leaf-wise lebih cepat konvergen tetapi lebih rawan overfitting, sehingga parameter num_leaves dan min_data_in_leaf harus diatur dengan hati-hati.
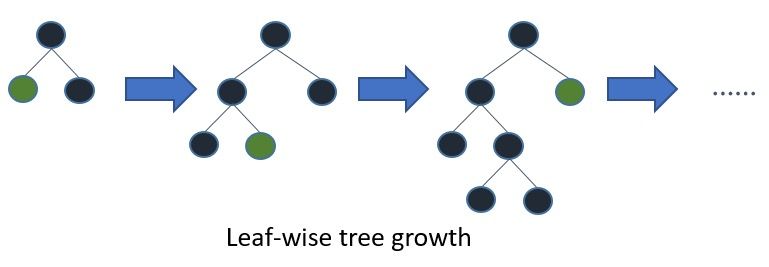
Gambar: Leaf-wise tree growth — leaf dengan potensi gain terbesar di-split terlebih dahulu, menghasilkan tree yang asimetris dan lebih dalam — Sumber: [LightGBM Documentation](https://github.com/Microsoft/LightGBM/blob/master/docs/Features.rst)
import lightgbm as lgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import time
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
start = time.time()
lgb_clf = lgb.LGBMClassifier(
n_estimators=100,
learning_rate=0.1,
num_leaves=31,
min_data_in_leaf=20,
random_state=42
)
lgb_clf.fit(X_train, y_train)
lgb_time = time.time() - start
y_pred = lgb_clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"Akurasi LightGBM: {acc:.4f}")
print(f"Waktu training LightGBM: {lgb_time:.3f} detik")
start = time.time()
xgb_clf = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
xgb_clf.fit(X_train, y_train)
xgb_time = time.time() - start
y_pred_xgb = xgb_clf.predict(X_test)
acc_xgb = accuracy_score(y_test, y_pred_xgb)
print(f"Akurasi XGBoost: {acc_xgb:.4f}")
print(f"Waktu training XGBoost: {xgb_time:.3f} detik")Output:
Akurasi LightGBM: 0.9649
Waktu training LightGBM: 0.311 detik
Akurasi XGBoost: 0.9561
Waktu training XGBoost: 0.109 detikPada dataset seperti Breast Cancer, LightGBM biasanya menyelesaikan training lebih cepat dengan akurasi yang sebanding. Perbedaan waktu ini akan semakin terasa pada dataset yang jauh lebih besar.
Strategi Hyperparameter Tuning dan Early Stopping
Hyperparameter yang paling berdampak pada performa gradient boosting adalah learning_rate, n_estimators, max_depth (atau num_leaves untuk LightGBM), dan parameter regularisasi. Strategi tuning yang efektif adalah menurunkan learning_rate dan meningkatkan n_estimators secara proporsional. Aturan praktis yang sering digunakan: mulai dengan learning_rate 0.1 dan n_estimators sekitar 100–200, lalu turunkan learning_rate menjadi 0.05 atau 0.01 sambil menaikkan n_estimators hingga 500–1000 untuk fine-tuning yang lebih presisi. Parameter max_depth atau num_leaves mengontrol kompleksitas setiap tree — nilai yang terlalu besar menyebabkan overfitting, sementara nilai yang terlalu kecil membuat model tidak mampu menangkap pola kompleks dalam data.
Selain parameter di atas, _subsampling_ (menggunakan sebagian data untuk setiap tree), _column subsampling_ (menggunakan sebagian fitur), dan regularisasi L1/L2 memberikan lapisan perlindungan tambahan terhadap overfitting. Kombinasi dari parameter-parameter ini sering kali lebih berdampak terhadap performa akhir model daripada sekadar mengubah learning_rate atau n_estimators secara terpisah.
Salah satu fitur paling berharga di XGBoost dan LightGBM adalah _early stopping_. Dengan menyediakan _validation set_, training akan berhenti secara otomatis jika performa pada validation set tidak membaik dalam sejumlah iterasi tertentu. Ini mencegah overfitting dan menghemat waktu komputasi.
import xgboost as xgb
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
xgb_reg = xgb.XGBRegressor(
n_estimators=1000,
learning_rate=0.05,
max_depth=4,
random_state=42,
early_stopping_rounds=50
)
xgb_reg.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
verbose=False
)
print(f"Iterasi terbaik: {xgb_reg.best_iteration}")
print(f"Skor terbaik (RMSE): {xgb_reg.best_score:.4f}")Output:
Iterasi terbaik: 983
Skor terbaik (RMSE): 52.5909Dalam contoh di atas, early_stopping_rounds=50 berarti training berhenti jika dalam 50 iterasi berturut-turut tidak ada perbaikan pada validation score. Pendekatan ini sangat praktis — kita tidak perlu menebak jumlah tree yang optimal di awal. Cukup set n_estimators cukup besar dan biarkan early stopping menentukan kapan berhenti.
Kapan Memilih XGBoost vs LightGBM — Panduan Praktis
Kedua framework sama-sama tangguh, tetapi memiliki keunggulan di skenario yang berbeda.
XGBoost lebih stabil untuk dataset kecil hingga menengah (kurang dari 10.000 sampel). Hasilnya lebih konsisten antar running, komunitasnya lebih matang, dan dokumentasinya sangat lengkap. XGBoost juga lebih _robust_ terhadap outlier karena level-wise tree growth-nya lebih konservatif.
LightGBM unggul untuk dataset besar (lebih dari 10.000 sampel) atau dataset dengan banyak fitur kategorikal. Kecepatan training LightGBM bisa 5–10 kali lebih cepat dari XGBoost pada dataset besar berkat GOSS dan EFB. Namun, LightGBM lebih sensitif terhadap outlier dan memerlukan tuning num_leaves yang cermat.
Dari segi interpretabilitas, XGBoost menyediakan tiga jenis _feature importance_ — weight (frekuensi fitur digunakan sebagai split), gain (kontribusi fitur terhadap pengurangan impurity), dan cover (jumlah sampel yang terpengaruh). LightGBM juga menyediakan metrik serupa dengan penekanan pada _split-by-gain_ yang lebih terintegrasi dengan arsitektur _leaf-wise_. Keduanya dapat digunakan untuk _feature selection_ dan memahami fitur mana yang paling berpengaruh terhadap prediksi model.
Best practice yang umum: mulai dengan XGBoost sebagai _baseline_ karena konfigurasi default-nya sudah cukup baik. Jika dataset sangat besar dan kecepatan training menjadi masalah, beralihlah ke LightGBM. Keduanya mendukung GPU training, _distributed computing_, dan deployment via ONNX atau PMML, sehingga integrasi ke pipeline production tidak menjadi kendala.
Gradient boosting adalah salah satu algoritma paling powerful untuk _structured data_. Menguasai XGBoost dan LightGBM memberikan keunggulan kompetitif dalam menyelesaikan masalah regresi dan klasifikasi di dunia nyata. Ingin mendalami Machine Learning secara sistematis — dari teori ensemble hingga deployment model boosting ke production? Bergabunglah dengan program bootcamp atau course Machine Learning di Rumah Coding dan bangun fondasi yang kokoh bersama mentor profesional.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python