Memahami Konsep Bias-Variance Tradeoff dan Implementasinya dalam Model Machine Learning

Mendeteksi Underfitting dan Overfitting melalui Analisis Error
Saat kita melatih model machine learning, dua metrik paling penting untuk diperhatikan adalah training error dan validation error. Training error mengukur seberapa baik model menangkap pola dari data yang digunakan saat pelatihan. Validation error mengukur kemampuan model dalam memprediksi data baru yang belum pernah dilihat sebelumnya. Perbandingan antara keduanya menjadi indikator utama untuk mendiagnosis dua masalah paling umum: underfitting dan overfitting.
Underfitting terjadi ketika model terlalu sederhana untuk menangkap struktur yang ada dalam data. Ciri khasnya adalah training error yang tinggi dan validation error yang juga tinggi. Model underfit tidak belajar cukup baik dari data training, sehingga performanya buruk secara konsisten. Sebaliknya, overfitting terjadi ketika model terlalu kompleks dan mulai menghafal noise dalam data latih. Gejalanya adalah training error yang sangat rendah, tetapi validation error yang tinggi — model gagal generalisasi ke data baru.
Hubungan antara kedua kondisi ini dengan bias dan variance sudah mulai terlihat: underfitting berkaitan erat dengan high bias (model membuat asumsi yang terlalu sederhana), sedangkan overfitting berkaitan dengan high variance (model terlalu sensitif terhadap fluktuasi kecil pada data training).
Mari kita lihat demonstrasi langsung menggunakan polynomial regression dengan tiga tingkat kompleksitas berbeda.
!pip install numpy matplotlib scikit-learn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
np.random.seed(42)
X = np.linspace(0, 1, 30).reshape(-1, 1)
y = np.sin(2 * np.pi * X).ravel() + np.random.normal(0, 0.15, 30)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=42)
degrees = [1, 4, 15]
plt.figure(figsize=(15, 4))
for i, deg in enumerate(degrees):
poly = PolynomialFeatures(degree=deg)
X_poly_train = poly.fit_transform(X_train)
X_poly_val = poly.transform(X_val)
model = LinearRegression()
model.fit(X_poly_train, y_train)
mse_train = mean_squared_error(y_train, model.predict(X_poly_train))
mse_val = mean_squared_error(y_val, model.predict(X_poly_val))
plt.subplot(1, 3, i + 1)
plt.scatter(X_train, y_train, label="Train", alpha=0.6)
plt.scatter(X_val, y_val, label="Validation", alpha=0.6)
X_plot = np.linspace(0, 1, 100).reshape(-1, 1)
X_poly_plot = poly.transform(X_plot)
plt.plot(X_plot, model.predict(X_poly_plot), "r-", label=f"deg={deg}")
plt.title(f"Degree {deg}\nTrain MSE: {mse_train:.4f} | Val MSE: {mse_val:.4f}")
plt.legend()
plt.tight_layout()
plt.show()Output:
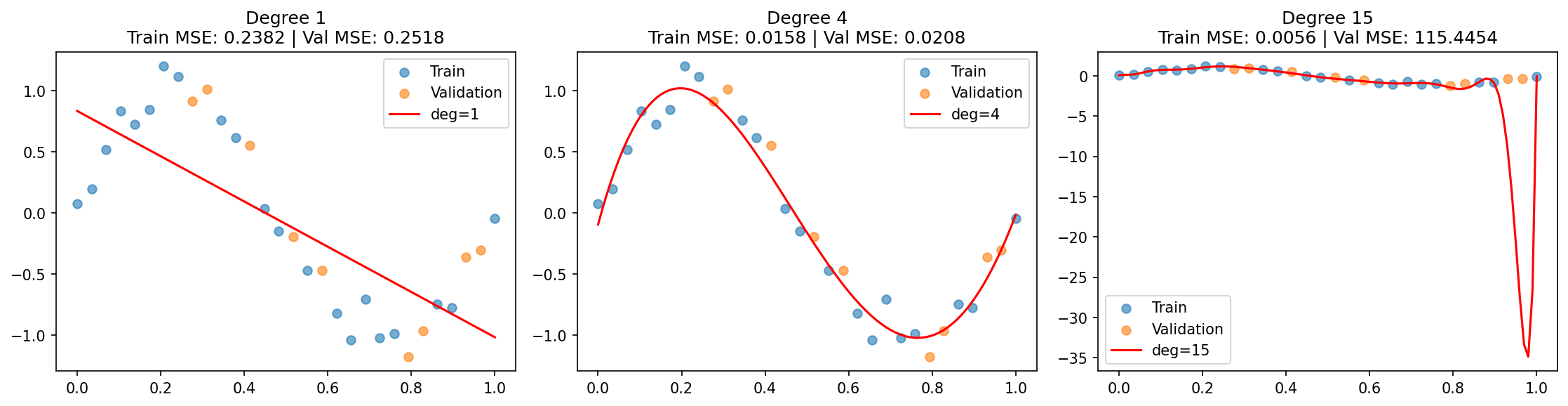
Kode di atas membangkitkan data sinusoidal dengan noise, lalu melatih tiga model polynomial regression dengan derajat 1, 4, dan 15. Model dengan degree=1 menghasilkan garis lurus yang gagal mengikuti pola sinusoidal — training error tinggi (underfitting, high bias). Degree=4 menghasilkan kurva yang mengikuti pola data dengan baik tanpa menghafal noise — training error dan validation error sama-sama rendah (optimal). Degree=15 menghasilkan kurva yang sangat berliku mengikuti titik data latih secara persis — training error mendekati nol, tetapi validation error melonjak drastis (overfitting, high variance).
Hubungan Matematis antara Bias dan Variance melalui Dekomposisi Error
Untuk memahami tradeoff ini secara fundamental, kita perlu melihat dekomposisi matematis dari error total model. Dalam teori pembelajaran statistik, expected error dari sebuah model dapat diuraikan menjadi tiga komponen:
$$E[(y - \hat{f}(x))^2] = \text{Bias}^2 + \text{Variance} + \text{Irreducible Error}$$
Bias adalah error yang timbul dari asumsi penyederhanaan yang dibuat oleh model terhadap data nyata. Model dengan bias tinggi (seperti linear regression pada data non-linear) membuat asumsi yang terlalu sederhana, sehingga tidak dapat menangkap hubungan kompleks dalam data. Semakin sederhana model, semakin tinggi biasnya.
Variance mengukur seberapa sensitif prediksi model terhadap fluktuasi kecil dalam data training. Model dengan variance tinggi akan menghasilkan kurva prediksi yang sangat berbeda jika kita mengganti data training dengan sampel lain dari populasi yang sama. Semakin kompleks model, semakin tinggi variancenya.
Sifat tradeoff ini bersifat fundamental: ketika kita mencoba menurunkan bias dengan membuat model lebih kompleks, variance justru meningkat. Sebaliknya, ketika kita mengurangi variance dengan menyederhanakan model, bias akan naik. Irreducible error adalah batas bawah error yang tidak bisa dihilangkan — komponen noise yang melekat pada data itu sendiri, terlepas dari seberapa baik model yang kita gunakan.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Tujuan kita dalam membangun model adalah menemukan titik keseimbangan di mana jumlah Bias² + Variance mencapai minimum. Titik ini sering disebut sebagai sweet spot.
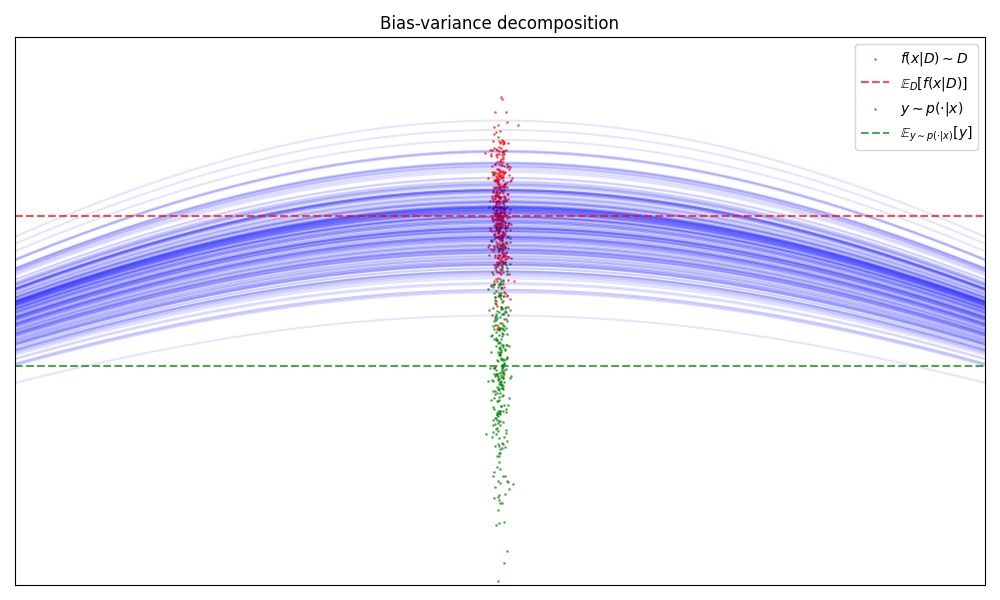
Gambar: Visualisasi dekomposisi Mean Squared Error menjadi Bias² + Variance + Irreducible Error pada suatu titik uji tetap. Titik hijau merepresentasikan noise data (irreducible error), titik merah menunjukkan prediksi model dari berbagai training set, dan selisih antara garis putus-putus merah dan hijau menunjukkan bias. — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Bias-variance_decomposition.png)
Visualisasi Tradeoff dengan Learning Curves dan Complexity Curves
Salah satu cara paling efektif untuk mengidentifikasi sweet spot adalah dengan memplot complexity curve: grafik yang menunjukkan training error dan validation error sebagai fungsi dari tingkat kompleksitas model (misalnya, derajat polinomial).
train_errors, val_errors = [], []
degrees_range = range(1, 20)
for deg in degrees_range:
poly = PolynomialFeatures(degree=deg)
X_poly_train = poly.fit_transform(X_train)
X_poly_val = poly.transform(X_val)
model = LinearRegression()
model.fit(X_poly_train, y_train)
train_errors.append(mean_squared_error(y_train, model.predict(X_poly_train)))
val_errors.append(mean_squared_error(y_val, model.predict(X_poly_val)))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(degrees_range, train_errors, "b-", label="Training Error")
plt.plot(degrees_range, val_errors, "r-", label="Validation Error")
plt.axvline(x=np.argmin(val_errors) + 1, color="g", linestyle="--", label="Sweet Spot")
plt.xlabel("Model Complexity (Polynomial Degree)")
plt.ylabel("Mean Squared Error")
plt.legend()
plt.title("Complexity Curve")
from sklearn.model_selection import learning_curve
train_sizes, train_scores, val_scores = learning_curve(
LinearRegression(), X, y, train_sizes=np.linspace(0.1, 1.0, 10),
cv=5, scoring="neg_mean_squared_error"
)
plt.subplot(1, 2, 2)
plt.plot(train_sizes, -train_scores.mean(axis=1), "b-", label="Training Error")
plt.plot(train_sizes, -val_scores.mean(axis=1), "r-", label="Validation Error")
plt.xlabel("Training Set Size")
plt.ylabel("Mean Squared Error")
plt.legend()
plt.title("Learning Curve")
plt.tight_layout()
plt.show()Output:
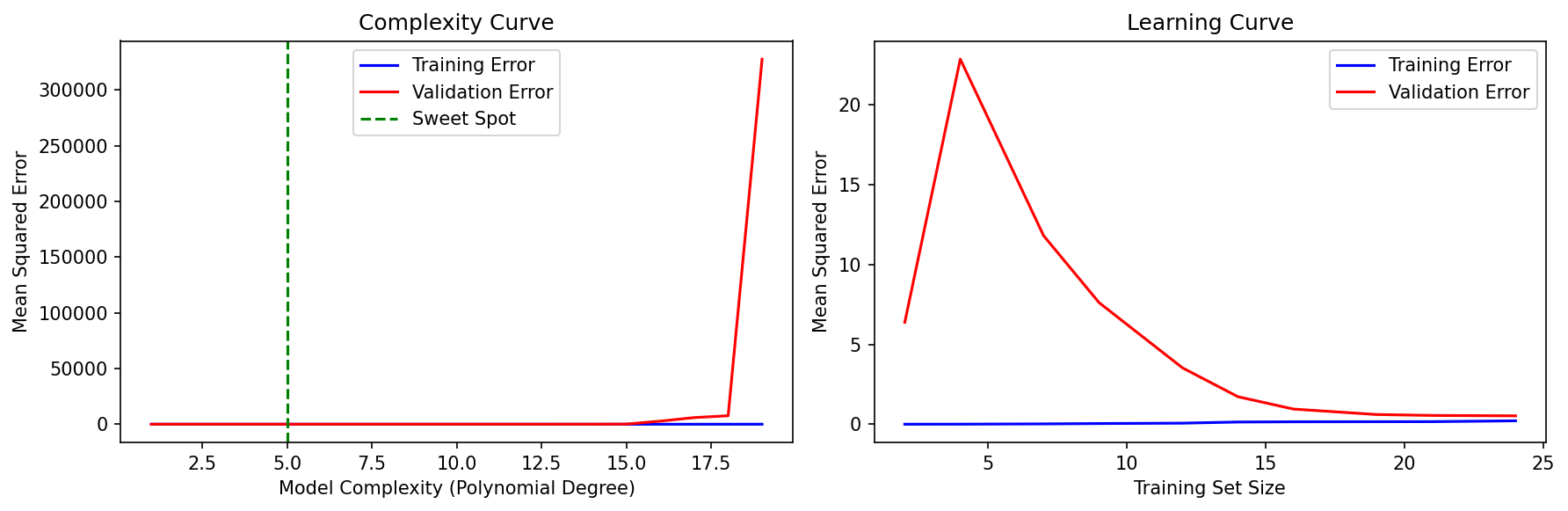
Pada complexity curve, kita bisa melihat bahwa validation error menurun seiring meningkatnya kompleksitas hingga mencapai titik minimum — inilah sweet spot. Setelah titik itu, validation error mulai naik kembali karena model mulai overfit. Training error, di sisi lain, terus menurun dan akhirnya mendekati nol.
Learning curve melengkapi diagnosis ini dengan memplot error terhadap jumlah data training. Untuk model dengan high bias, kedua kurva (training dan validation) akan plateau pada error yang tinggi dan saling berdekatan — menambah data tidak akan membantu. Untuk model dengan high variance, akan ada gap lebar antara training error (rendah) dan validation error (tinggi) — menambah data training dapat membantu memperkecil gap ini.
Teknik Praktis Menyeimbangkan Bias dan Variance
Setelah kita mampu mendiagnosis masalah bias dan variance, langkah selanjutnya adalah menerapkan teknik untuk menyeimbangkannya. Berikut adalah pendekatan yang paling umum digunakan:
Regularization (L1/Lasso dan L2/Ridge) bekerja dengan menambahkan penalty pada koefisien model, sehingga kompleksitas efektif model berkurang tanpa harus menghapus fitur secara drastis. Regularization sangat efektif untuk mengendalikan variance pada model yang cenderung overfit.
from sklearn.linear_model import Ridge
poly = PolynomialFeatures(degree=10)
X_poly_train = poly.fit_transform(X_train)
X_poly_val = poly.transform(X_val)
plain_model = LinearRegression()
plain_model.fit(X_poly_train, y_train)
ridge_model = Ridge(alpha=1.0)
ridge_model.fit(X_poly_train, y_train)
print(f"{'Model':<20} {'Train MSE':<15} {'Val MSE':<15}")
print("-" * 50)
print(f"{'Linear Regression':<20} {mean_squared_error(y_train, plain_model.predict(X_poly_train)):<15.4f} {mean_squared_error(y_val, plain_model.predict(X_poly_val)):<15.4f}")
print(f"{'Ridge (alpha=1)':<20} {mean_squared_error(y_train, ridge_model.predict(X_poly_train)):<15.4f} {mean_squared_error(y_val, ridge_model.predict(X_poly_val)):<15.4f}")Output:
Model Train MSE Val MSE
--------------------------------------------------
Linear Regression 0.0080 0.1021
Ridge (alpha=1) 0.1931 0.1955Pada kode di atas, kita membandingkan linear regression biasa dengan Ridge regression pada polynomial degree 10. Ridge menambahkan penalty L2 pada koefisien, yang memaksa model untuk tidak terlalu bergantung pada fitur-fitur berorde tinggi. Hasilnya, validation error Ridge biasanya lebih rendah dibanding plain model, meskipun training error mungkin sedikit lebih tinggi — inilah tradeoff yang kita kelola secara sadar.
Teknik lain yang efektif meliputi:
- Ensemble methods: Bagging (seperti Random Forest) mereduksi variance dengan merata-rata prediksi dari banyak model. Boosting (seperti XGBoost atau LightGBM) mereduksi bias dengan melatih model secara sekuensial untuk memperbaiki kesalahan model sebelumnya.
- Cross-validation (k-fold) memberikan estimasi performa model yang lebih akurat dengan memvalidasi model pada beberapa subset data, membantu kita memonitor tradeoff secara objektif.
- Menambah data training adalah strategi paling langsung untuk mengatasi high variance — lebih banyak data membuat model lebih stabil karena noise dari sampel individual menjadi kurang berpengaruh.
- Feature selection dan dimensionality reduction mengurangi jumlah fitur yang tidak relevan atau redundan, yang pada gilirannya mengurangi noise dan variance.
Bias-variance tradeoff adalah fondasi konseptual yang mendasari hampir semua keputusan dalam membangun model machine learning. Menguasai konsep ini memungkinkan kita untuk mendiagnosis masalah model secara sistematis, memilih algoritma yang tepat, dan menerapkan teknik optimasi dengan penuh kesadaran. Di bootcamp dan course terstruktur Rumah Coding, konsep fundamental seperti ini dipraktikkan langsung dalam proyek nyata — dari diagnostic visual hingga tuning model di production-grade dataset.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python