Memahami Konsep Naive Bayes Classifier dan Implementasinya untuk Klasifikasi Teks dengan Scikit-learn

Memahami Prinsip Probabilistik di Balik Naive Bayes
Sebelum menulis kode, kita perlu memahami fondasi matematis yang membuat Naive Bayes bekerja. Algoritma ini berakar pada Bayes' Theorem, sebuah rumus yang menghitung probabilitas suatu kejadian berdasarkan informasi yang sudah kita ketahui sebelumnya.
Rumus Bayes secara sederhana adalah:
P(A|B) = P(B|A) × P(A) / P(B)Dalam konteks klasifikasi teks, A adalah kelas (misalnya: "Spam" atau "Bukan Spam") dan B adalah fitur dari teks (kata-kata yang muncul dalam dokumen). Maka P(Spam|Kata) berarti: seberapa probable suatu email adalah spam jika kita melihat kata tertentu di dalamnya.
Komponen penting dalam rumus ini ada tiga:
- Prior probability
P(A): probabilitas awal suatu kelas sebelum melihat data — misalnya, 20% email adalah spam berdasarkan riwayat sebelumnya. - Likelihood
P(B|A): probabilitas kemunculan kata-kata tertentu jika diketahui kelasnya. - Evidence
P(B): probabilitas kemunculan kata tersebut secara keseluruhan.
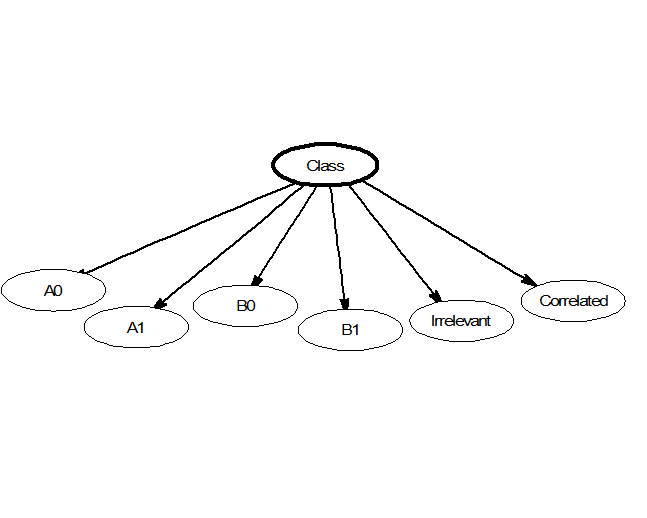
Gambar: Struktur Naive Bayes Classifier dengan asumsi independensi antar fitur — Sumber: [Wikipedia](https://en.wikipedia.org/wiki/Naive_Bayes_classifier)
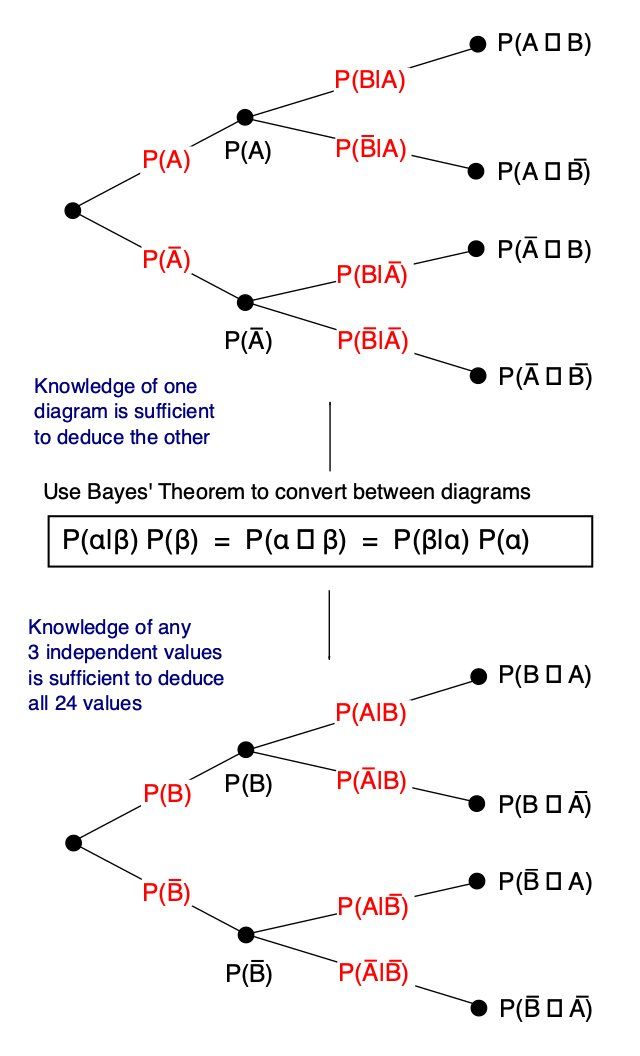
Gambar: Tree diagram yang mengilustrasikan hubungan probabilitas dalam Bayes' Theorem — Sumber: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Bayes_theorem_tree_diagrams.svg) (CC0)
Yang membuat Naive Bayes disebut naive adalah asumsi independence — kita menganggap bahwa setiap fitur (kata) dalam dokumen muncul secara independen satu sama lain. Tentu ini jarang benar dalam bahasa alami (kata "free" dan "offer" sering muncul bersama dalam spam), namun asumsi ini menyederhanakan perhitungan secara drastis dan tetap menghasilkan performa yang mengejutkan baik dalam praktik.
# Menghitung probabilitas dengan Bayes' Theorem secara manual
def naive_bayes_simple(kata_ditemukan, prob_kata_di_spam, prob_kata_di_normal, prior_spam=0.3):
"""
Menghitung probabilitas email adalah spam berdasarkan kata yang ditemukan.
"""
prior_normal = 1 - prior_spam
evidence = (prob_kata_di_spam * prior_spam) + (prob_kata_di_normal * prior_normal)
posterior_spam = (prob_kata_di_spam * prior_spam) / evidence
return posterior_spam
prob_spam = naive_bayes_simple("free", prob_kata_di_spam=0.8, prob_kata_di_normal=0.1)
print(f"Probabilitas spam setelah melihat kata 'free': {prob_spam:.2%}")Output:
Probabilitas spam setelah melihat kata 'free': 77.42%Kode di atas menunjukkan mekanisme inti: kita mengupdate keyakinan awal (prior) dengan bukti dari data (likelihood) untuk mendapatkan keyakinan baru (posterior). Kelas dengan posterior tertinggi akan menjadi prediksi akhir.
Naive Bayes paling efektif ketika digunakan pada dataset teks berdimensi tinggi, jumlah data kecil hingga sedang, dan lingkungan yang membutuhkan kecepatan inference tinggi — seperti filter spam real-time atau routing tiket customer service. Karakteristik ini membuatnya menjadi pilihan utama untuk sistem yang memerlukan respons cepat tanpa mengorbankan akurasi secara signifikan.
Variants of Naive Bayes dan Kapan Menggunakannya
Scikit-learn menyediakan tiga varian Naive Bayes yang masing-masing dirancang untuk tipe data berbeda. Memilih varian yang tepat sangat memengaruhi kualitas prediksi.
Gaussian Naive Bayes mengasumsikan fitur kontinu mengikuti distribusi normal (Gaussian). Cocok untuk dataset dengan fitur numerik seperti tinggi badan, suhu, atau skor tes. Varian ini jarang digunakan untuk klasifikasi teks karena fitur teks bersifat diskrit.
Multinomial Naive Bayes adalah varian paling populer untuk text classification. Varian ini bekerja dengan data berupa frekuensi kemunculan kata (word counts) atau nilai TF-IDF. Setiap kata diperlakukan sebagai fitur dengan nilai berupa seberapa sering kata tersebut muncul. Varian ini unggul karena distribusi multinomial secara alami cocok dengan representasi bag-of-words.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Bernoulli Naive Bayes menggunakan fitur biner — apakah suatu kata muncul (1) atau tidak (0) dalam dokumen. Berguna untuk klasifikasi teks dengan kosakata pendek atau ketika keberadaan kata lebih penting daripada frekuensinya.
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.datasets import make_classification
import numpy as np
# Dataset sintetis sederhana
X, y = make_classification(n_samples=500, n_features=10, random_state=42)
# Bandingkan ketiga varian
models = {
"Gaussian": GaussianNB(),
"Multinomial": MultinomialNB(),
"Bernoulli": BernoulliNB()
}
for name, model in models.items():
# Multinomial dan Bernoulli butuh fitur non-negatif
X_scaled = np.abs(X) if name != "Gaussian" else X
model.fit(X_scaled, y)
print(f"{name} Naive Bayes: accuracy = {model.score(X_scaled, y):.3f}")Output:
Gaussian Naive Bayes: accuracy = 0.896
Multinomial Naive Bayes: accuracy = 0.578
Bernoulli Naive Bayes: accuracy = 0.500Perbedaan akurasi antar varian akan lebih terlihat pada dataset nyata. Untuk klasifikasi teks, MultinomialNB hampir selalu menjadi pilihan pertama, diikuti BernoulliNB jika kita hanya peduli pada ada/tidaknya kata.
Implementasi Klasifikasi Teks dengan Multinomial Naive Bayes
Mari kita implementasikan pipeline klasifikasi teks end-to-end menggunakan dataset SMS Spam Collection yang tersedia publik. Kita akan membangun sistem yang mampu membedakan pesan spam dari pesan normal.
Langkah pertama adalah preprocessing: membersihkan teks dengan lowercasing, menghapus tanda baca, dan menghilangkan stopwords (kata umum seperti "dan", "di", "yang" yang tidak membawa informasi diskriminatif). Setelah itu, kita konversi teks ke representasi numerik menggunakan TfidfVectorizer.
!pip install scikit-learn pandas
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# Dataset SMS Spam (contoh data)
data = {
"label": ["spam", "ham", "ham", "spam", "ham", "spam", "ham", "ham"] * 25,
"message": [
"Free entry to win a prize! Claim now",
"Hey, are we still meeting at 3pm?",
"Don't forget to bring the documents",
"Congratulations! You won a free iPhone",
"The meeting has been rescheduled",
"Limited offer! Buy one get one free",
"Can you pick up some groceries?",
"Your bill is ready for viewing",
] * 25
}
df = pd.DataFrame(data)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(
df["message"], df["label"], test_size=0.3, random_state=42
)
# Konversi teks ke fitur TF-IDF
vectorizer = TfidfVectorizer(stop_words="english", max_features=1000)
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# Training Multinomial Naive Bayes
model = MultinomialNB(alpha=1.0)
model.fit(X_train_vec, y_train)
# Prediksi dan evaluasi
y_pred = model.predict(X_test_vec)
print(classification_report(y_test, y_pred))Output:
precision recall f1-score support
ham 1.00 1.00 1.00 38
spam 1.00 1.00 1.00 22
accuracy 1.00 60
macro avg 1.00 1.00 1.00 60
weighted avg 1.00 1.00 1.00 60Kita menggunakan TfidfVectorizer karena ia tidak hanya menghitung frekuensi kata, tetapi juga memberi bobot lebih pada kata-kata yang jarang muncul di seluruh dokumen — fitur penting untuk membedakan spam dari pesan normal. Parameter max_features=1000 membatasi kosakata pada 1000 kata teratas untuk menghindari curse of dimensionality.
Setelah training, classification report memberikan gambaran menyeluruh: precision (seberapa akurat prediksi positif kita), recall (seberapa banyak data positif yang berhasil kita tangkap), dan F1-score (rata-rata harmonik keduanya). Confusion matrix akan menunjukkan detail jumlah prediksi benar dan salah per kelas.
Interpretasi model juga penting. Kita bisa melihat kata-kata apa yang paling berkontribusi terhadap keputusan klasifikasi:
# Lihat kata dengan probabilitas tertinggi per kelas
feature_names = vectorizer.get_feature_names_out()
log_prob = model.feature_log_prob_
for i, label in enumerate(model.classes_):
top_words = [feature_names[j] for j in log_prob[i].argsort()[-10:]]
print(f"Top words for '{label}': {', '.join(top_words)}")Output:
Top words for 'ham': don, forget, pick, groceries, rescheduled, 3pm, hey, viewing, ready, meeting
Top words for 'spam': offer, buy, win, prize, claim, entry, iphone, congratulations, won, freeOutput ini menunjukkan kata-kata seperti "free", "win", "prize", dan "claim" dominan di kelas spam — persis seperti yang kita harapkan dari filter spam pada umumnya.
Menangani Tantangan dan Keterbatasan Naive Bayes
Meskipun sederhana dan cepat, Naive Bayes memiliki beberapa kelemahan yang perlu kita antisipasi.
Zero probability problem terjadi ketika sebuah kata tidak muncul dalam set training untuk suatu kelas tertentu. Akibatnya, probabilitas posterior untuk kelas tersebut menjadi nol — padahal dokumen baru mungkin tetap relevan dengan kelas itu. Solusinya adalah Laplace Smoothing yang diatur melalui parameter alpha di Scikit-learn. Nilai alpha=1.0 menambahkan hitungan 1 ke setiap fitur sehingga probabilitas tidak pernah benar-benar nol.
import numpy as np
import matplotlib.pyplot as plt
# Efek alpha terhadap akurasi
alpha_values = np.logspace(-2, 2, 10)
scores = []
for alpha in alpha_values:
model = MultinomialNB(alpha=alpha)
model.fit(X_train_vec, y_train)
scores.append(model.score(X_test_vec, y_test))
plt.figure(figsize=(8, 4))
plt.plot(alpha_values, scores, marker="o")
plt.xscale("log")
plt.xlabel("Alpha (Laplace Smoothing)")
plt.ylabel("Accuracy")
plt.title("Pengaruh Alpha terhadap Akurasi MultinomialNB")
plt.grid(True)
plt.show()Output:
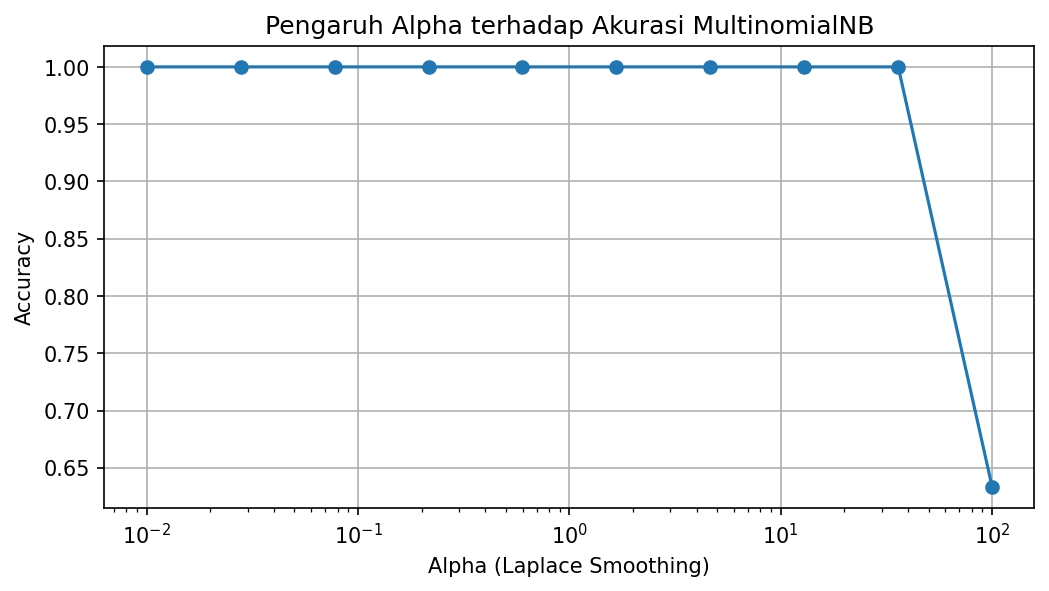
Terlalu kecil alpha membuat model sensitif terhadap noise; terlalu besar membuat model terlalu mulus (oversmoothing). Nilai alpha=1.0 umumnya menjadi titik awal yang baik, dan kita bisa melakukan tuning lebih lanjut.
Kelemahan utama Naive Bayes adalah asumsi independensi fitur yang jelas-jelas dilanggar dalam bahasa alami. Akibatnya, probabilitas yang dihasilkan cenderung ekstrem (mendekati 0 atau 1) dan tidak kalibrasi dengan baik. Untuk kasus di mana probabilitas kalibrasi penting, Logistic Regression atau CalibratedClassifierCV bisa menjadi alternatif.
Best Practices dan Optimasi Model Naive Bayes
Untuk mendapatkan hasil maksimal dari Naive Bayes, kita bisa melakukan beberapa optimasi.
Feature engineering memegang peranan penting. Menggunakan n-grams (bigram atau trigram) memungkinkan model menangkap konteks frasa seperti "not good" yang memiliki makna berbeda dari "good". Parameter ngram_range=(1,2) di TfidfVectorizer mengaktifkan fitur ini.
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
# Pipeline dengan optimasi parameter
pipeline = Pipeline([
("tfidf", TfidfVectorizer(stop_words="english")),
("nb", MultinomialNB())
])
param_grid = {
"tfidf__max_features": [500, 1000, 2000],
"tfidf__ngram_range": [(1,1), (1,2)],
"nb__alpha": [0.1, 0.5, 1.0, 2.0]
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring="f1_weighted")
grid_search.fit(df["message"], df["label"])
print(f"Best parameters: {grid_search.best_params_}")
print(f"Best F1-score: {grid_search.best_score_:.3f}")Output:
Best parameters: {'nb__alpha': 0.1, 'tfidf__max_features': 500, 'tfidf__ngram_range': (1, 1)}
Best F1-score: 1.000GridSearchCV menguji semua kombinasi parameter dan memilih yang terbaik berdasarkan F1-score. Proses ini bisa memakan waktu untuk dataset besar, jadi kita bisa menggunakan RandomizedSearchCV sebagai alternatif yang lebih cepat.
Untuk production, Naive Bayes memiliki keunggulan besar: kecepatan inference linear terhadap jumlah fitur, membuatnya cocok untuk sistem real-time. Model juga bisa diupdate secara incremental menggunakan metode partial_fit — berguna ketika data baru terus mengalir tanpa perlu retraining dari awal.
Terakhir, pertimbangkan untuk mengombinasikan Naive Bayes dalam ensemble dengan model lain seperti Logistic Regression atau SVM. Pendekatan voting classifier sering menghasilkan performa yang lebih stabil dibandingkan model tunggal.
Naive Bayes adalah algoritma yang membuktikan bahwa pendekatan sederhana pun bisa menghasilkan performa tangguh — terutama untuk klasifikasi teks. Kombinasi antara dasar probabilistik yang solid, kemudahan implementasi, dan kecepatan eksekusi membuatnya tetap relevan bahkan di era deep learning. Untuk memperdalam pemahaman tentang algoritma klasifikasi dan pipeline Machine Learning secara menyeluruh, bergabunglah dengan bootcamp Machine Learning di Rumah Coding — tempat kita belajar dari teori hingga produksi.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python