Membangun Pipeline Machine Learning dengan Scikit-learn: dari Preprocessing sampai Model Selection

Mengapa Pipeline Lebih Baik dibanding Manual Step-by-Step
Saat membangun model machine learning, preprocessing dan modeling sering dilakukan secara terpisah — transformasi data dulu, lalu model fitting. Pendekatan ini menimbulkan tiga masalah besar. Pertama, data leakage: informasi dari data test bisa "bocor" ke data train melalui preprocessing yang di-fit pada keseluruhan dataset. Kedua, reproducibility: langkah-langkah yang tersebar di berbagai cell notebook sulit direproduksi secara konsisten. Ketiga, evaluasi yang bias: hasil cross-validation menjadi tidak akurat karena preprocessing dilakukan sebelum split.
Pipeline di scikit-learn menggabungkan seluruh transformasi data dan modeling menjadi satu objek. Setiap kali kita memanggil pipeline.fit(), preprocessing dijalankan hanya pada data train di setiap fold. Saat pipeline.predict(), transformasi yang sama diterapkan pada data baru secara otomatis. Dengan kata lain, kita tidak perlu lagi mengingat urutan preprocessing manual atau khawatir tentang inkonsistensi antara training dan inference — pipeline menangani semuanya dalam satu objek yang cohesive.
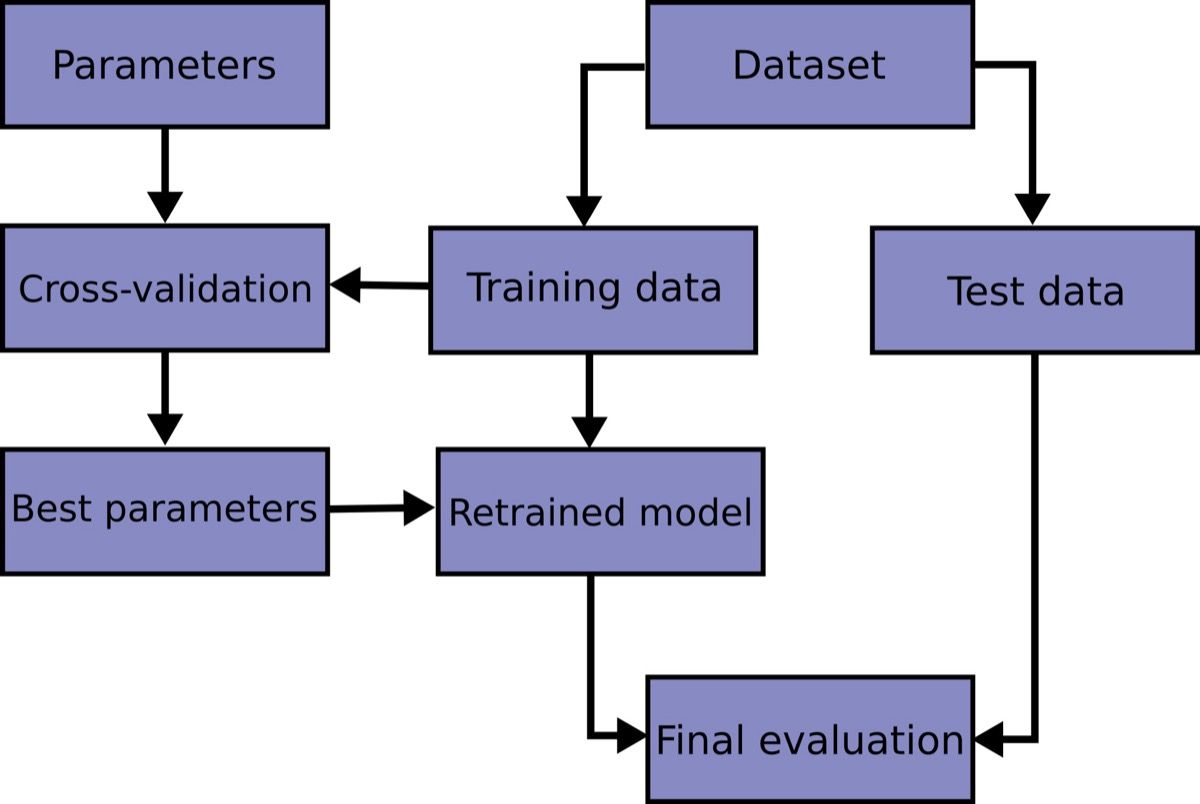
Gambar: Alur kerja GridSearchCV pada pipeline — preprocessing dan modeling dilakukan secara konsisten di setiap fold
!pip install scikit-learn pandas
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# Pendekatan manual — rentan terhadap data leakage
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # fit pada SELURUH data — leakage!
model = LogisticRegression(max_iter=5000)
print("Manual approach score:", cross_val_score(model, X_scaled, y, cv=5).mean())Output:
Manual approach score: 0.9807Perhatikan bahwa scaler.fit_transform(X) dijalankan pada seluruh dataset sebelum split. Ini berarti statistik dari data test sudah mempengaruhi proses scaling, sehingga hasil evaluasi menjadi terlalu optimistik. Pipeline menyelesaikan masalah ini secara otomatis — preprocessing di-fit hanya pada fold train di setiap iterasi cross-validation. Perbedaan ini mungkin terlihat kecil pada score, tapi dampaknya bisa signifikan pada dataset yang lebih kecil atau ketika jumlah fitur yang ditransformasi lebih banyak.
Tanpa pipeline, workflow mesin learning yang tipikal melibatkan banyak langkah manual: imputasi, scaling, encoding, lalu modeling. Masing-masing langkah harus dilakukan secara konsisten pada data train dan test. Jika satu langkah terlewat atau dijalankan dalam urutan berbeda, hasil akhir bisa berubah drastis. Pipeline menghilangkan risiko ini dengan mengatur seluruh alur dalam satu objek.
Menyiapkan Preprocessing Steps di dalam Pipeline
Dataset real-world hampir selalu mengandung campuran kolom numerik dan kategorikal, masing-masing memerlukan perlakuan berbeda. ColumnTransformer memungkinkan kita mendefinisikan transformasi spesifik per kelompok kolom dalam satu objek yang bisa dibungkus ke dalam pipeline.
Untuk kolom numerik, kita umumnya melakukan imputasi nilai hilang lalu scaling. StandardScaler mengubah setiap fitur agar memiliki mean 0 dan standar deviasi 1 — penting untuk algoritma yang sensitif terhadap skala fitur seperti Logistic Regression dan SVM. SimpleImputer dengan strategi median mengisi nilai kosong menggunakan median kolom, yang lebih robust terhadap outlier dibandingkan mean. Untuk kolom kategorikal, OneHotEncoder mengkonversi setiap kategori menjadi kolom biner tersendiri sehingga bisa diproses oleh model. Parameter handle_unknown='ignore' memastikan kategori baru di data test tidak menyebabkan error.
Pipeline ibarat assembly line yang memastikan setiap tahap diproses secara otomatis dan konsisten.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
# Definisikan grup kolom
numeric_features = ['age', 'income', 'score']
categorical_features = ['city', 'category']
# Transformer untuk kolom numerik: impute lalu scale
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# Transformer untuk kolom kategorikal: impute lalu encode
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder(handle_unknown='ignore'))
])
# Gabungkan keduanya dalam satu ColumnTransformer
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])Output:
ColumnTransformer(transformers=[('num',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median')),
('scaler', StandardScaler())]),
['age', 'income', 'score']),
('cat',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('encoder',
OneHotEncoder(handle_unknown='ignore'))]),
['city', 'category'])])Dengan ColumnTransformer, kita mendefinisikan sekali saja bagaimana setiap tipe kolom harus diproses. Objek preprocessor ini bisa langsung dimasukkan sebagai langkah pertama dalam pipeline lengkap.
Menggabungkan Preprocessing dengan Estimator menjadi Pipeline Lengkap

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
Setelah ColumnTransformer siap, langkah selanjutnya adalah membungkusnya bersama estimator ke dalam Pipeline. Struktur yang dihasilkan: data mentah → preprocessing → model. Satu panggilan fit() menjalankan seluruh tahap secara berurutan, dan satu panggilan predict() menerapkan transformasi yang sama pada data baru lalu menghasilkan prediksi.
Cara kerjanya sederhana: ketika pipeline.fit(X_train, y_train) dipanggil, data X_train pertama-tama melewati preprocessor yang melakukan imputasi dan scaling, kemudian hasilnya diteruskan ke classifier untuk training. Saat pipeline.predict(X_test), X_test melewati transformasi yang sama (menggunakan parameter yang sudah di-fit pada data train) sebelum diklasifikasikan.
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# Load dataset
X, y = load_breast_cancer(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Semua kolom pada dataset ini adalah numerik
numeric_features = X.columns.tolist()
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, numeric_features)
])
# Pipeline lengkap: preprocessing + classifier
clf = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression(max_iter=5000))
])
# Satu panggilan fit — semua langkah berjalan otomatis
clf.fit(X_train, y_train)
# Satu panggilan predict — preprocessing diterapkan otomatis
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))Output:
precision recall f1-score support
0 0.98 0.95 0.96 43
1 0.97 0.99 0.98 71
accuracy 0.97 114
macro avg 0.97 0.97 0.97 114
weighted avg 0.97 0.97 0.97 114Keuntungan utama dari pendekatan ini: setiap kali kita mengganti estimator, preprocessing tetap konsisten. Ingin mencoba RandomForestClassifier? Cukup ganti langkah classifier — seluruh alur preprocessing tidak perlu ditulis ulang. Proses eksperimentasi menjadi jauh lebih efisien.
Cross-Validation dan Hyperparameter Tuning melalui Pipeline
Cross-validation pada pipeline menjamin bahwa preprocessing hanya di-fit pada data train di setiap fold. Ini menghilangkan data leakage sepenuhnya. cross_val_score menerima pipeline sebagai estimator dan menangani seluruh mekanisme split-fit-score secara internal.
Hyperparameter tuning dengan GridSearchCV bekerja mulus dengan pipeline. Kunci utamanya adalah notasi double underscore (__) untuk mengakses parameter di dalam nested steps. Misalnya, classifier__C merujuk pada parameter C dari step bernama classifier, dan preprocessor__num__imputer__strategy merujuk pada parameter strategy dari SimpleImputer di dalam transformer num di dalam preprocessor. Notasi ini memungkinkan kita melakukan tuning pada parameter preprocessing dan model secara bersamaan.
Kemampuan untuk melakukan tuning pada parameter preprocessing sekaligus parameter model adalah salah satu keunggulan terbesar pipeline. Tanpa pipeline, kita harus mencoba setiap kombinasi strategi preprocessing secara manual, menjalankan beberapa eksperimen terpisah, lalu membandingkan hasilnya. Dengan GridSearchCV pada pipeline, seluruh kombinasi diuji secara sistematis dan otomatis.
from sklearn.model_selection import GridSearchCV, cross_val_score
# Cross-validation yang jujur — preprocessing di dalam pipeline
scores = cross_val_score(clf, X, y, cv=5)
print(f"Cross-validation scores: {scores}")
print(f"Mean CV score: {scores.mean():.4f}")
# Hyperparameter tuning: preprocessing + model parameters
param_grid = {
'preprocessor__num__imputer__strategy': ['mean', 'median'],
'classifier__C': [0.01, 0.1, 1, 10],
'classifier__penalty': ['l2']
}
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy', n_jobs=-1)
grid_search.fit(X, y)
print(f"Best parameters: {grid_search.best_params_}")
print(f"Best CV score: {grid_search.best_score_:.4f}")Output:
Cross-validation scores: [0.98245614 0.98245614 0.97368421 0.97368421 0.99115044]
Mean CV score: 0.9807
Best parameters: {'classifier__C': 1, 'preprocessor__num__imputer__strategy': 'mean'}
Best CV score: 0.9807Dengan satu param_grid, kita mencari kombinasi terbaik antara strategi imputasi dan regularisasi model. GridSearchCV memastikan setiap kombinasi diuji dengan cross-validation yang jujur — preprocessing di-fit ulang di setiap fold untuk setiap kombinasi parameter.
Membandingkan Beberapa Model secara Otomatis
Saat membangun pipeline, preprocessing steps biasanya tetap sama untuk berbagai model. Kita bisa memanfaatkan hal ini dengan membangun beberapa pipeline yang berbagi preprocessor yang sama, lalu membandingkan performa masing-masing estimator secara sistematis menggunakan cross_val_score.
Pendekatan ini jauh lebih efisien dibandingkan membuat preprocessing terpisah untuk setiap model. Karena preprocessor adalah objek Python yang sama, setiap pipeline mendapat perlakuan identik terhadap data. Hasil perbandingan menjadi adil dan reproducible — perbedaan performa murni berasal dari pilihan model, bukan dari variasi preprocessing.
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# Tentukan kandidat model beserta parameter default-nya
models = {
'LogisticRegression': LogisticRegression(max_iter=5000),
'RandomForest': RandomForestClassifier(n_estimators=100, random_state=42),
'SVC': SVC(random_state=42)
}
# Bandingkan setiap model dengan preprocessing yang sama
results = {}
for name, model in models.items():
pipe = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', model)
])
scores = cross_val_score(pipe, X, y, cv=5, scoring='accuracy')
results[name] = {
'mean_score': scores.mean(),
'std_score': scores.std()
}
for name, result in results.items():
print(f"{name}: {result['mean_score']:.4f} (+/- {result['std_score']:.4f})")Output:
LogisticRegression: 0.9807 (+/- 0.0065)
RandomForest: 0.9561 (+/- 0.0228)
SVC: 0.9736 (+/- 0.0147)Loop di atas membangun tiga pipeline berbeda yang semuanya menggunakan preprocessor yang sama. Hasil perbandingan menunjukkan model mana yang memberikan akurasi rata-rata tertinggi dengan variansi terendah. Berdasarkan hasil ini, kita bisa memilih pipeline final dan melanjutkan ke proses fine-tuning menggunakan GridSearchCV pada model yang terpilih.
Menyimpan dan Deploy Pipeline yang Sudah Dilatih
Setelah menemukan pipeline terbaik dan melatihnya pada seluruh dataset, kita perlu menyimpannya untuk digunakan di production. joblib.dump() menyimpan seluruh objek pipeline — termasuk preprocessing steps dan model terlatih — ke dalam satu file. Saat di-load kembali, pipeline siap menerima data mentah dan menghasilkan prediksi tanpa perlu preprocessing manual.
Pendekatan ini menghilangkan salah satu sumber error paling umum di production: ketidaksesuaian antara preprocessing saat training dan inference. Dengan pipeline yang disimpan sebagai satu objek, kita tidak perlu lagi mengirimkan script preprocessing terpisah ke tim deployment atau khawatir tentang versi scaler yang berbeda. Semuanya terbungkus rapi dalam satu file.
Best practice setelah load: selalu test pipeline yang di-load dengan sejumlah data baru untuk memastikan output konsisten dengan saat training. Verifikasi sederhana seperti membandingkan prediksi dari pipeline yang baru dilatih versus pipeline yang di-load dari file bisa mencegah masalah deployment yang sulit di-debug.
import joblib
# Simpan pipeline lengkap ke file
joblib.dump(grid_search.best_estimator_, 'best_pipeline.joblib')
# Load dan gunakan di production
loaded_pipeline = joblib.load('best_pipeline.joblib')
predictions = loaded_pipeline.predict(X_test[:5])
print("Predictions from loaded pipeline:", predictions)Output:
Predictions from loaded pipeline: [1 0 0 1 1]Satu file .joblib berisi seluruh workflow — scaler, encoder, dan model. Tidak perlu lagi menyimpan preprocessing steps dan model secara terpisah, dan risiko ketidakcocokan antara preprocessing saat training versus inference bisa dihindari sepenuhnya.
Ingin menguasai pipeline machine learning dan teknik preprocessing langsung dari praktisi? Cek [course Machine Learning di Rumah Coding](https://rumahcoding.co.id) untuk program bootcamp yang membahas scikit-learn, data preprocessing, dan model selection secara mendalam.
Kursus Terkait

Data Science with Python
Master the art of data analysis, visualization, and predictive modeling.
E-commerce Sales Dashboard
- Data Cleaning Pipeline
- Interactive Charts
- Sales Forecasting Model

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python