Teori dan Implementasi Support Vector Machine (SVM) untuk Klasifikasi Data Non-Linear

Keterbatasan SVM Linear dalam Menangani Data Non-Linear
_Support Vector Machine_ (SVM) adalah algoritma klasifikasi yang bekerja dengan mencari _hyperplane_ optimal — garis pemisah yang memaksimalkan margin antara dua kelas. Dalam bentuk dasarnya, SVM linear mengasumsikan bahwa data dapat dipisahkan secara linear oleh sebuah garis lurus (untuk data 2D) atau bidang datar (untuk dimensi lebih tinggi). Ini berarti SVM linear hanya efektif ketika kelas-kelas dalam dataset kita terletak di sisi yang berlawanan dari hyperplane tanpa tumpang tindih yang kompleks.
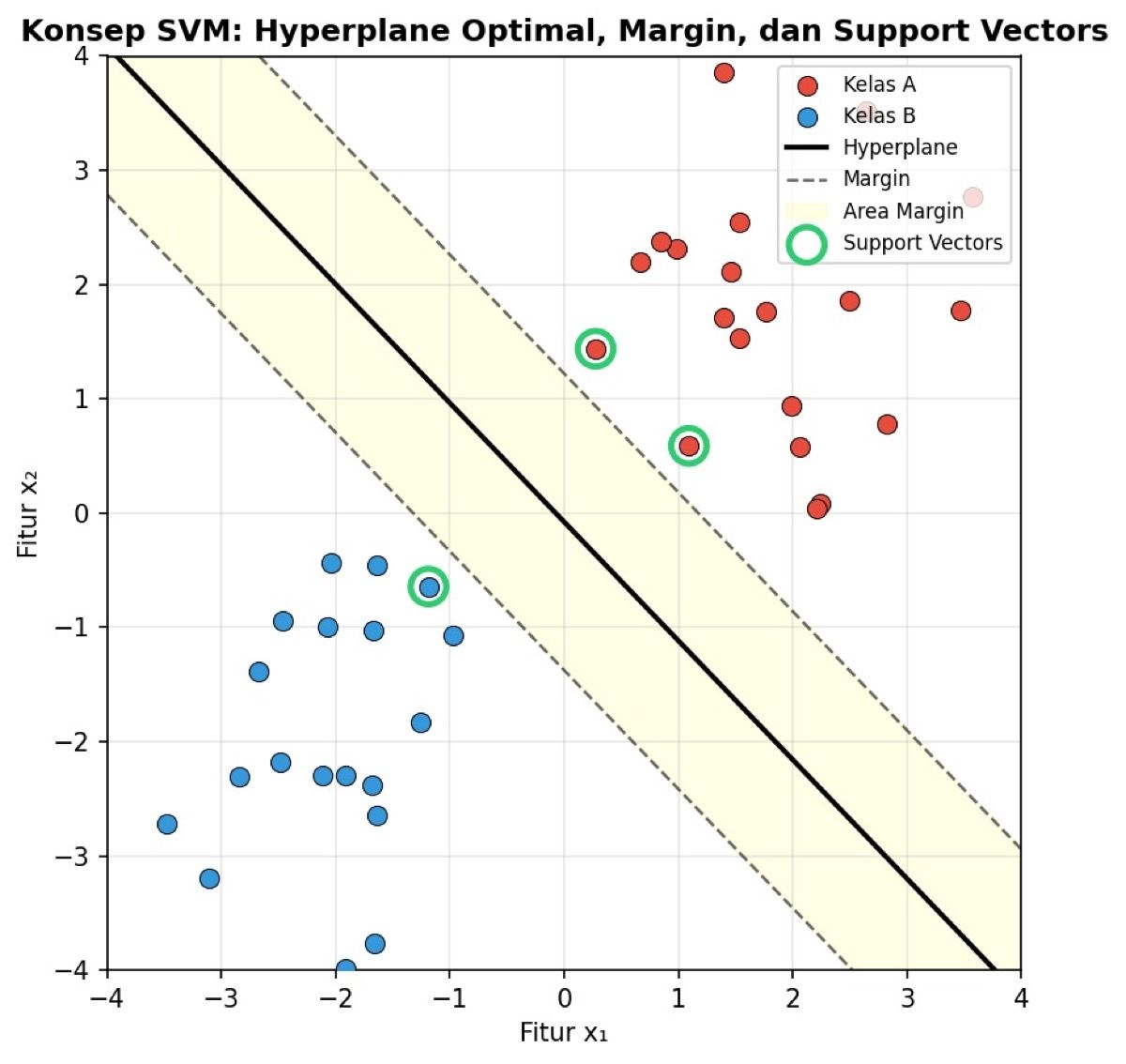
Gambar: Ilustrasi konsep SVM — hyperplane pemisah (garis tebal), area margin (area kuning), dan support vectors (lingkaran hijau) yang menentukan posisi optimal hyperplane — Sumber: Dokumentasi Rumah Coding
Masalah muncul ketika kita berhadapan dengan data non-linear. Bayangkan dua kelas yang membentuk pola lingkaran konsentris — kelas A di dalam lingkaran kecil, kelas B di luar lingkaran besar. Tidak ada satu pun garis lurus yang bisa memisahkan keduanya dengan akurat. Contoh lain adalah dataset _moons_ (bulan sabit) di mana dua kelas melengkung saling membelit. Dalam situasi ini, SVM linear menghasilkan akurasi yang sangat buruk, seringkali tidak lebih baik dari tebakan acak.
Keterbatasan ini menjadi motivasi utama untuk mengembangkan pendekatan yang lebih fleksibel. Kita perlu sebuah mekanisme yang mampu menangani pola melengkung dan non-linear tanpa mengorbankan keunggulan SVM dalam mencari margin yang maksimal.
Memetakan Data ke Ruang Dimensi Lebih Tinggi dengan Kernel Trick
Solusi elegan untuk masalah ini adalah _kernel trick_. Ide dasarnya sederhana namun kuat: jika data tidak bisa dipisahkan secara linear di ruang fitur asli, kita bisa memproyeksikannya ke ruang dimensi yang lebih tinggi di mana pemisahan linear menjadi mungkin. Kernel trick seperti lensa yang membuat pola tak terlihat jadi terlihat terpisah — teknik ini mengubah perspektif tanpa mengubah data itu sendiri.
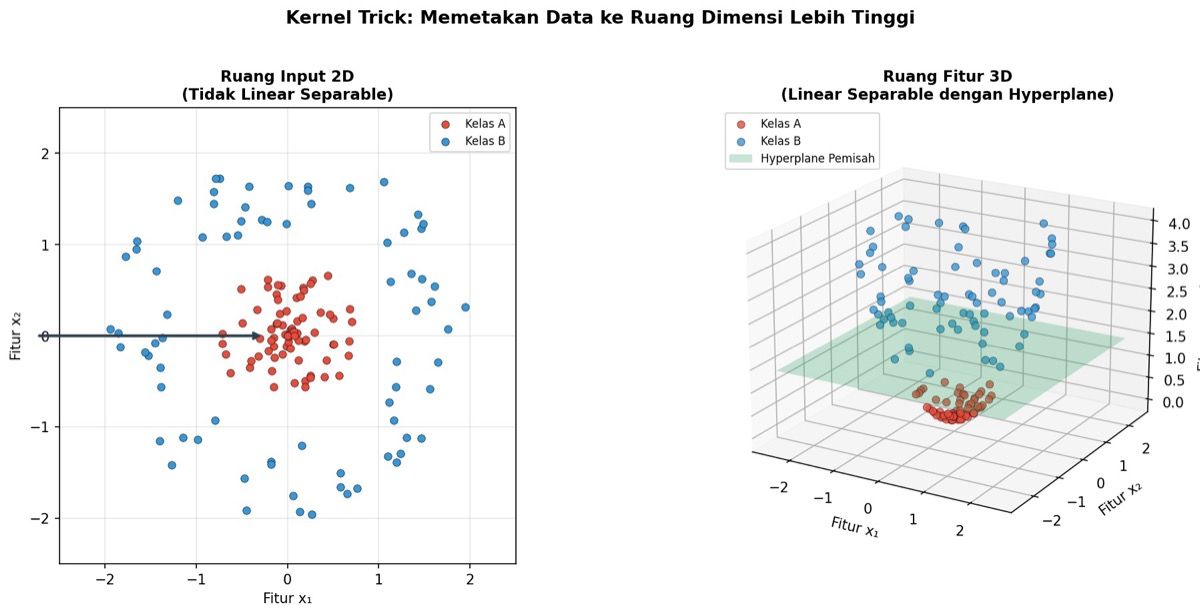
Gambar: Kernel trick — data dua kelas yang membentuk pola lingkaran konsentris di ruang input 2D (tidak bisa dipisahkan garis lurus) dipetakan ke ruang fitur 3D menggunakan φ(x,y) = (x, y, x²+y²) sehingga dapat dipisahkan oleh sebuah hyperplane datar (bidang hijau) — Sumber: Dokumentasi Rumah Coding
Yang membuat kernel trick istimewa adalah efisiensinya. Alih-alih melakukan transformasi eksplisit ke dimensi tinggi (yang bisa sangat mahal secara komputasi), kernel trick menghitung _dot product_ di ruang dimensi tinggi secara implisit menggunakan fungsi kernel. Dengan kata lain, kita mendapatkan manfaat transformasi tanpa perlu benar-benar melakukan transformasi.
Beberapa fungsi kernel yang populer meliputi _polynomial_, _sigmoid_, dan _Radial Basis Function_ (RBF). RBF kernel menjadi pilihan default yang paling umum karena fleksibilitasnya. RBF mengukur kesamaan antara dua titik data berdasarkan jarak Euclidean, dengan parameter gamma yang mengontrol seberapa jauh pengaruh satu titik data. Nilai gamma yang kecil membuat pengaruh menyebar luas (decision boundary cenderung linear), sementara nilai gamma besar membuat model lebih sensitif terhadap variasi lokal.
Implementasi SVM Non-Linear dengan Scikit-learn
Mari kita praktikkan konsep di atas menggunakan Scikit-learn. Kita akan menggunakan dataset sintetis make_moons yang memiliki pola dua kelas melengkung — tantangan klasik untuk SVM non-linear.

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
!pip install scikit-learn matplotlib numpy
from sklearn.svm import SVC
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = make_moons(n_samples=300, noise=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
svm_rbf = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
svm_rbf.fit(X_train, y_train)
y_pred = svm_rbf.predict(X_test)
print(f"Akurasi SVM RBF: {accuracy_score(y_test, y_pred):.3f}")Output:
Akurasi SVM RBF: 0.983Kita memilih kernel rbf karena dataset make_moons memiliki pola non-linear yang cocok ditangani oleh kernel ini. Parameter C=1.0 memberikan keseimbangan antara margin lebar dan toleransi error, sementara gamma='scale' membuat Scikit-learn menghitung nilai gamma secara otomatis berdasarkan jumlah fitur. Proses _fitting_ melatih model untuk menemukan decision boundary non-linear yang optimal. Output yang diharapkan adalah akurasi di atas 0.90, yang menunjukkan bahwa SVM RBF mampu mengklasifikasikan data non-linear dengan sangat baik — kontras dengan SVM linear yang akan menghasilkan akurasi jauh lebih rendah.
Visualisasi Decision Boundary SVM dengan Kernel RBF
Untuk memahami bagaimana SVM RBF bekerja secara visual, kita perlu memplot decision boundary yang dihasilkan. Proses ini melibatkan pembuatan _mesh grid_ yang mencakup seluruh area fitur, lalu meminta model memprediksi label untuk setiap titik dalam grid tersebut.
import numpy as np
import matplotlib.pyplot as plt
def plot_decision_boundary(model, X, y, title):
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200),
np.linspace(y_min, y_max, 200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap='coolwarm')
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap='coolwarm')
plt.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1],
s=100, facecolors='none', edgecolors='k', linewidth=1.5, label='Support Vectors')
plt.title(title)
plt.legend()
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
svm_linear = SVC(kernel='linear', C=1.0, random_state=42).fit(X_train, y_train)
plot_decision_boundary(svm_linear, X_test, y_test, 'SVM Linear')
plt.subplot(1, 2, 2)
plot_decision_boundary(svm_rbf, X_test, y_test, 'SVM RBF')
plt.tight_layout()
plt.show()Output:
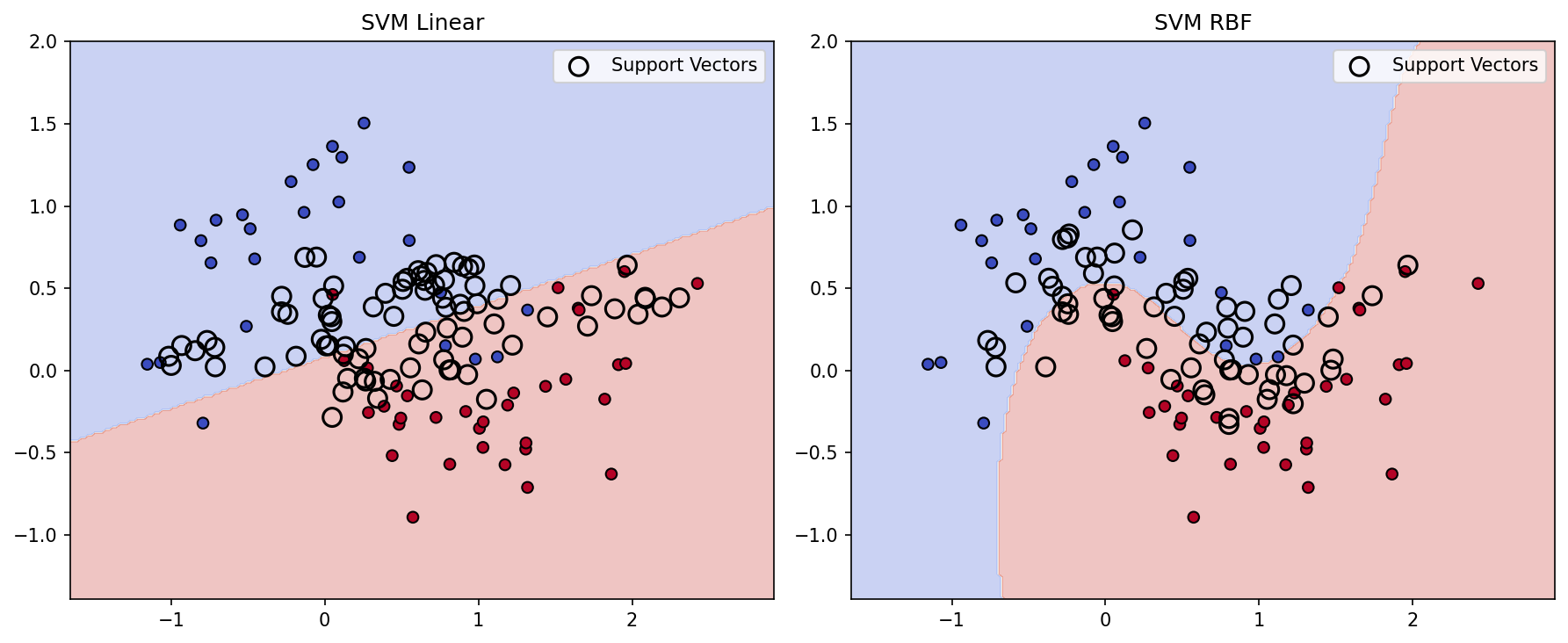
Perbandingan visual antara SVM linear dan SVM RBF sangat mencolok. SVM linear hanya mampu membuat garis lurus yang memotong dataset, mengakibatkan banyak kesalahan klasifikasi. Sebaliknya, SVM RBF menghasilkan decision boundary melengkung yang mengikuti distribusi data asli. Titik-titik yang ditandai sebagai _support vectors_ (lingkaran transparan) adalah sampel data yang berada di dekat batas keputusan dan menentukan posisi margin. SVM RBF mengidentifikasi lebih banyak support vectors, terutama di area di mana dua kelas saling berdekatan, yang memungkinkan boundary beradaptasi secara lokal.
Efek Hyperparameter C dan Gamma pada Hasil Klasifikasi
Dua hyperparameter paling penting dalam SVM RBF adalah C dan gamma. Parameter C mengontrol toleransi terhadap _misclassification_. Nilai C kecil menghasilkan margin lebar dengan toleransi error tinggi (cenderung _underfit_), sedangkan nilai C besar memaksa margin sempit untuk mengklasifikasikan semua titik dengan benar (berisiko _overfit_). Parameter gamma menentukan radius pengaruh satu titik data: gamma kecil membuat pengaruh meluas (boundary lebih halus, mirip linear), gamma besar membuat pengaruh sangat lokal (boundary mengikuti setiap fluktuasi data, berisiko overfit).
Mari kita lihat efek ketiga kombinasi hyperparameter secara berdampingan:
configs = [
(0.1, 0.1, 'C=0.1, gamma=0.1'),
(1, 1, 'C=1, gamma=1'),
(100, 10, 'C=100, gamma=10')
]
plt.figure(figsize=(15, 4))
for i, (C, gamma, title) in enumerate(configs, 1):
plt.subplot(1, 3, i)
model = SVC(kernel='rbf', C=C, gamma=gamma, random_state=42).fit(X_train, y_train)
plot_decision_boundary(model, X_test, y_test, title)
plt.tight_layout()
plt.show()Output:
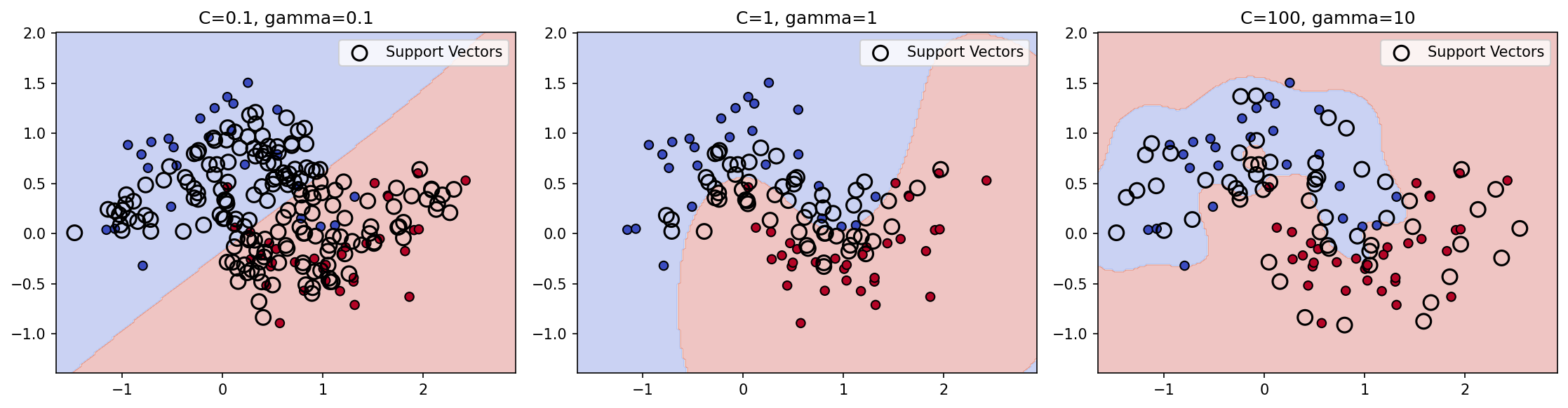
Hasil visual menunjukkan tiga skenario yang berbeda. Kombinasi C=0.1, gamma=0.1 menghasilkan boundary yang terlalu halus — hampir linear — sehingga banyak titik data salah klasifikasi (underfitting). Kombinasi C=1, gamma=1 memberikan keseimbangan yang baik: boundary melengkung mengikuti pola data tanpa terlalu detail. Kombinasi C=100, gamma=10 menghasilkan boundary yang sangat kompleks dengan lekukan yang mengikuti setiap titik data individual, menandakan overfitting. Model overfit ini mungkin memiliki akurasi tinggi pada data training, tetapi performanya akan turun drastis pada data baru. Kuncinya adalah menemukan sweet spot antara underfitting dan overfitting melalui eksperimen dan validasi.
Panduan Memilih Kernel dan Best Practices Implementasi SVM
RBF kernel adalah pilihan default yang paling aman untuk data non-linear karena fleksibilitasnya dalam menangani berbagai bentuk decision boundary. Kernel ini hanya memiliki dua hyperparameter (C dan gamma) yang relatif mudah di-tuning. _Polynomial kernel_ bisa menjadi alternatif ketika kita mencurigai adanya interaksi fitur pada derajat tertentu, tetapi polynomial kernel memiliki lebih banyak parameter (degree, coef0) yang membuat tuning lebih kompleks.
Beberapa praktik penting dalam implementasi SVM. Pertama, _feature scaling_ menggunakan StandardScaler adalah langkah wajib sebelum SVM. SVM sangat sensitif terhadap skala fitur karena perhitungan jarak (termasuk dalam kernel RBF) sangat dipengaruhi oleh magnitude nilai. Tanpa scaling, fitur dengan rentang nilai besar akan mendominasi perhitungan kernel. Kedua, gunakan GridSearchCV untuk mencari kombinasi C dan gamma optimal secara sistematis. Ketiga, perhatikan bahwa kompleksitas komputasi SVM meningkat secara kuadratik terhadap jumlah sampel (O(n²) hingga O(n³)). Untuk dataset besar (ratusan ribu sampel), pertimbangkan menggunakan _LinearSVC_ atau _SGDClassifier_ dengan kernel approximation sebagai alternatif yang lebih efisien.
Setelah memahami teori dan praktik SVM dengan kernel trick, langkah selanjutnya adalah menguasai algoritma klasifikasi lainnya dan tahu kapan menggunakannya. Bergabunglah dengan kursus Machine Learning di Rumah Coding untuk pendalaman lebih lanjut — dari konsep fundamental hingga implementasi di industri — agar kita bisa membangun model yang tidak hanya akurat, tetapi juga tepat konteks.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python