Membangun Model Klasifikasi Teks dengan Scikit-learn: dari TF-IDF sampai Evaluation

Klasifikasi teks merupakan salah satu task paling fundamental dalam Natural Language Processing (NLP). Dari email spam detection sampai sentiment analysis, pipeline klasifikasi teks mengikuti pola yang konsisten: preprocessing, feature extraction, training, dan evaluation. Scikit-learn menyediakan tools yang lengkap untuk setiap tahap pipeline ini.
Preprocessing dan Feature Extraction dengan TF-IDF
Teks mentah tidak bisa langsung diproses oleh machine learning model. Kita perlu mengubah teks menjadi representasi numerik. TF-IDF (Term Frequency-Inverse Document Frequency) adalah teknik yang banyak digunakan karena menekankan kata-kata yang membedakan antar kategori sambil menurunkan bobot kata-kata umum.
!pip install scikit-learn pandas numpy
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import numpy as np
import pandas as pd
# Sample dataset: kategori berita
texts = [
"Timnas Indonesia menang telak 4-0 atas lawannya di pertandingan persahabatan",
"Saham IHSG melemah dalam perdagangan hari ini akibat tekanan global",
"Gelar juara liga musim ini diraih oleh klub yang konsisten sepanjang season",
"Bank sentral menaikkan suku bunga acuan untuk mengendalikan inflasi",
"Striker baru mencetak hat-trick dalam debutnya di liga musim ini",
"Investor asing menarik dananya dari pasar obligasi domestik minggu ini",
"Wasit menunjuk titik putih setelah VAR review di menit akhir pertandingan",
"Deviden perusahaan telkom naik signifikan dibandingkan tahun sebelumnya",
"Pertahanan solid menjadi kunci kemenangan tim dalam turnamen kali ini",
"Kurs rupiah menguat terhadap dolar AS di perdagangan hari ini",
]
categories = ["olahraga", "keuangan", "olahraga", "keuangan", "olahraga", "keuangan", "olahraga", "keuangan", "olahraga", "keuangan"]
# TF-IDF vectorization
vectorizer = TfidfVectorizer(max_features=100, stop_words='english')
X = vectorizer.fit_transform(texts)
print(f"Shape matriks TF-IDF: {X.shape}")
print(f"Jumlah fitur: {len(vectorizer.get_feature_names_out())}")
print(f"Fitur pertama: {vectorizer.get_feature_names_out()[:10]}")Output:
Shape matriks TF-IDF: (10, 84)
Jumlah fitur: 84
Fitur pertama: ['acuan' 'akhir' 'akibat' 'asing' 'atas' 'bank' 'baru' 'bunga' 'dalam'
'dananya']Parameter max_features=100 membatasi jumlah fitur agar model tidak terlalu sparse, sementara stop_words='english' menghapus kata-kata umum yang tidak informatif. Vektor TF-IDF menghasilkan matriks sparse di mana setiap baris merepresentasikan satu dokumen dan setiap kolom merepresentasikan bobot TF-IDF satu term.
Train-Test Split dan Model Training
Setelah feature extraction, kita membagi data menjadi training set dan test set. Pembagian ini memastikan evaluasi model menggunakan data yang belum pernah dilihat selama training.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import MultinomialNB
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, categories, test_size=0.3, random_state=42, stratify=categories
)
print(f"Training samples: {len(y_train)}")
print(f"Test samples: {len(y_test)}")
print(f"Distribusi train: {pd.Series(y_train).value_counts().to_dict()}")
print(f"Distribusi test: {pd.Series(y_test).value_counts().to_dict()}")Output:
Training samples: 7
Test samples: 3
Distribusi train: {'olahraga': 4, 'keuangan': 3}
Distribusi test: {'keuangan': 2, 'olahraga': 1}Parameter stratify=categories menjamin proporsi kategori yang seimbang antara training dan test set. Hal ini penting untuk dataset dengan distribusi kategori yang tidak merata.
Perbandingan Model Klasifikasi
Scikit-learn memudahkan perbandingan beberapa model sekaligus. Kita akan menguji tiga model yang umum digunakan untuk klasifikasi teks: Logistic Regression, Linear SVM, dan Multinomial Naive Bayes.
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
models = {
'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42),
'Linear SVM': LinearSVC(random_state=42, max_iter=1000),
'Multinomial NB': MultinomialNB(),
}
results = {}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
results[name] = {
'model': model,
'predictions': y_pred,
'accuracy': acc
}
print(f"{name}: Accuracy = {acc:.4f}")
# Visualisasi perbandingan akurasi
fig, ax = plt.subplots(figsize=(8, 5))
model_names = list(results.keys())
accuracies = [results[m]['accuracy'] for m in model_names]
bars = ax.bar(model_names, accuracies, color=['#4C72B0', '#DD8452', '#55A868'], edgecolor='white')
ax.set_ylabel('Accuracy')
ax.set_title('Model Comparison: Text Classification')
ax.set_ylim(0, 1.1)
for bar, acc in zip(bars, accuracies):
ax.text(bar.get_x() + bar.get_width() / 2., bar.get_height() + 0.02,
f'{acc:.2f}', ha='center', fontsize=12)
plt.tight_layout()
plt.savefig('/tmp/blog-sandbox/membangun-model-klasifikasi-teks/output_bar.png', dpi=150, bbox_inches='tight')
plt.close('all')
print("Bar chart saved")
Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from found...
Output:
Logistic Regression: Accuracy = 0.3333
Linear SVM: Accuracy = 0.6667
Multinomial NB: Accuracy = 0.3333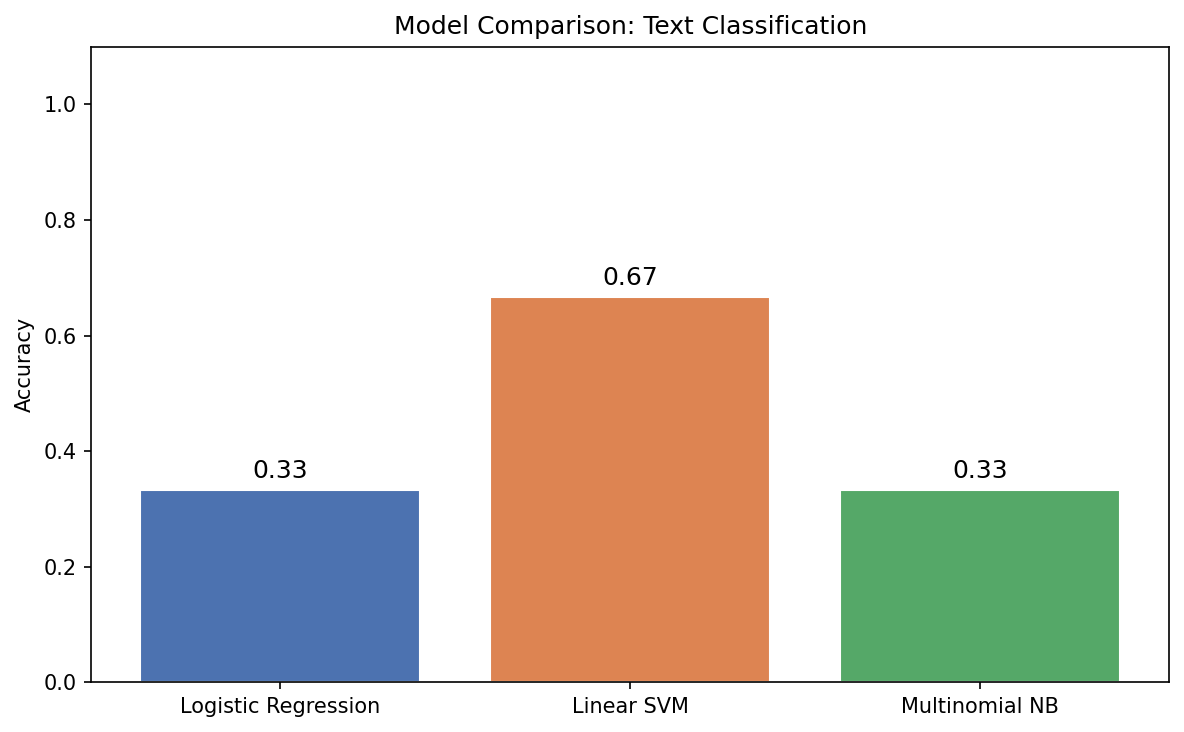
Pada dataset kecil ini, Linear SVM memberikan performa terbaik dengan akurasi 67%, sementara Logistic Regression dan Multinomial NB hanya mencapai 33%. Hasil ini menunjukkan bahwa pemilihan model mempengaruhi performa secara signifikan, bahkan pada dataset sederhana. Pada dataset nyata dengan ribuan sampel dan kategori yang lebih banyak, perbedaan ini akan semakin terasa.
Evaluation Metric yang Komprehensif
Akurasi saja tidak cukup untuk mengevaluasi model klasifikasi, terutama pada dataset dengan distribusi kategori yang tidak seimbang. Classification report memberikan precision, recall, dan F1-score per kategori.
from sklearn.metrics import classification_report
# Pilih model terbaik untuk evaluasi mendalam (Linear SVM)
best_model = results['Linear SVM']['model']
y_pred = best_model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['keuangan', 'olahraga']))Output:
precision recall f1-score support
keuangan 1.00 0.50 0.67 2
olahraga 0.50 1.00 0.67 1
accuracy 0.67 3
macro avg 0.75 0.75 0.67 3
weighted avg 0.83 0.67 0.67 3Precision mengukur seberapa akurat prediksi positif model. Recall mengukur seberapa banyak instance positif yang berhasil terdeteksi. F1-score adalah harmonic mean dari keduanya, memberikan single metric yang seimbang untuk evaluasi.
Confusion Matrix Visualization
Confusion matrix menampilkan distribusi prediksi model secara detail, memperlihatkan kesalahan klasifikasi spesifik antar kategori.
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
fig, ax = plt.subplots(figsize=(6, 5))
ConfusionMatrixDisplay.from_estimator(best_model, X_test, y_test, ax=ax, cmap='Blues')
ax.set_title('Confusion Matrix: Linear SVM')
plt.tight_layout()
plt.savefig('/tmp/blog-sandbox/membangun-model-klasifikasi-teks/output_cm.png', dpi=150, bbox_inches='tight')
plt.close('all')
print("Confusion matrix saved")Output:
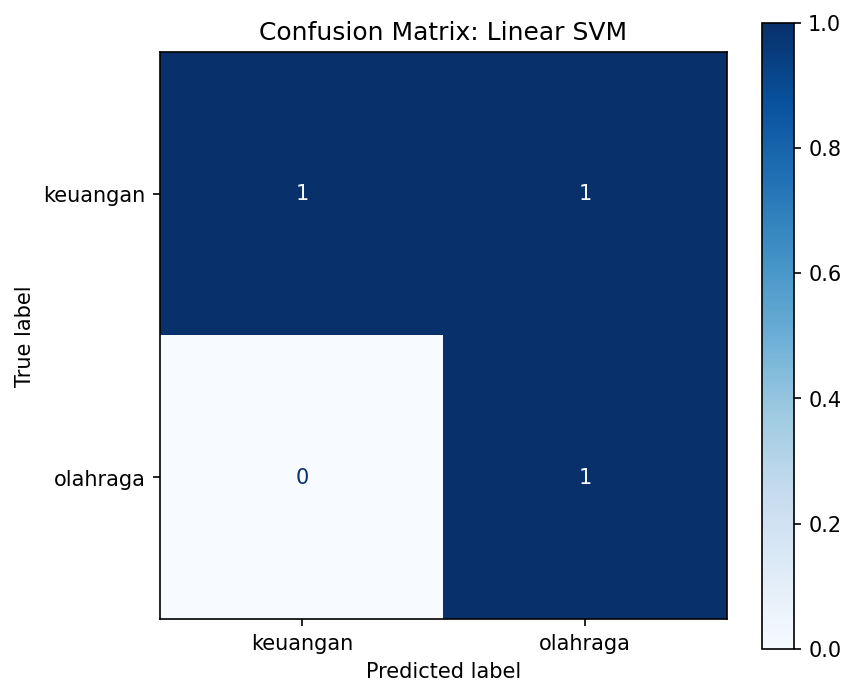
Diagonal utama menunjukkan prediksi benar, sedangkan sel di luar diagonal menunjukkan salah klasifikasi. Pada dataset berskala besar, confusion matrix membantu mengidentifikasi kategori mana yang sering tertukar, mengarahkan perbaikan pada preprocessing atau feature engineering yang spesifik. Visualisasi ini lebih informatif dibanding angka akurasi tunggal karena memperlihatkan pola kesalahan secara eksplisit.
End-to-End Pipeline dengan Scikit-learn
Scikit-learn menyediakan Pipeline yang menggabungkan preprocessing dan model training dalam satu objek. Pipeline memastikan bahwa transformasi yang diaplikasikan pada training data juga konsisten pada test data.
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
# Membuat pipeline end-to-end
pipeline = Pipeline([
('tfidf', TfidfVectorizer(max_features=100, stop_words='english')),
('clf', LogisticRegression(max_iter=1000, random_state=42)),
])
# Cross-validation pada data lengkap
cv_scores = cross_val_score(pipeline, texts, categories, cv=3, scoring='accuracy')
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {cv_scores.mean():.4f} (+/- {cv_scores.std():.4f})")Output:
Cross-validation scores: [1. 0.33333333 0.33333333]
Mean CV accuracy: 0.5556 (+/- 0.3143)Pipeline menghilangkan kebutuhan manual transformation antara training dan inference. Method fit() menjalankan fit_transform pada TfidfVectorizer kemudian fit pada classifier, sementara predict() menjalankan transform lalu predict secara otomatis. Cross-validation memberikan estimasi generalization yang lebih robust dibanding single train-test split. Variasi antar fold (1.0 di fold pertama vs 0.33 di fold lainnya) menunjukkan bahwa dataset kecil menghasilkan estimasi performa yang tidak stabil — ini menggarisbawahi pentingnya validasi silang pada dataset berskala besar.
Tips Praktis untuk Klasifikasi Teks
Beberapa hal yang perlu diperhatikan saat membangun pipeline klasifikasi teks di production: lakukan text preprocessing yang konsisten (lowercase, remove punctuation, stemming) sebelum vectorization, gunakan ngram_range=(1, 2) pada TfidfVectorizer untuk menangkap phrase-level features, dan terapkan class_weight='balanced' pada classifier jika distribusi kategori tidak merata.
Pipeline TF-IDF dengan Scikit-learn merupakan starting point yang solid. Ketika dataset bertambah besar, pertimbangkan untuk mengganti TF-IDF dengan word embeddings seperti Word2Vec atau transformer-based model untuk menangkap semantic relationships yang lebih dalam.
Mau memperdalam skill Machine Learning dan NLP secara terstruktur? Bergabunglah dengan Machine Learning Bootcamp di Rumah Coding. Materi berbasis proyek nyata dengan pendampingan mentor dari praktisi industri.
Kursus Terkait

Deep Learning Bootcamp
A beginner-friendly, highly interactive bootcamp designed to take you from foundational concepts to deploying real-world Artificial Intelligence applications. Through a completely project-based approach, you will master the core of Deep Learning, Artificial Neural Networks, and Computer Vision using Python and TensorFlow, ultimately building a professional-grade AI web application for your portfolio.
GreenGuard: Intelligent Plant Disease Diagnosis Web App
- Interactive Image Upload UI: A clean, user-friendly interface built with Streamlit that supports drag-and-drop image uploads directly from a computer or mobile phone.
- Real-Time AI Inference: Utilizes a lightweight, optimized CNN model (like MobileNetV2) to process the image and return a diagnosis in seconds without heavy server load.
- Confidence Scoring Dashboard: Visually displays the model's prediction probability (e.g., "95% confident this is Tomato Late Blight") using interactive progress bars or charts.

LLM Bootcamp
This project-based bootcamp is designed for beginners to dive practically into the world of Large Language Models (LLMs). Through hands-on building, you will learn how to interact with top-tier AI APIs, master prompt engineering, orchestrate complex workflows using LangChain, and implement Retrieval-Augmented Generation (RAG) to query your own documents. By the end of this course, you will have the skills to build, test, and deploy a fully functional, custom AI web application.
Domain-Specific AI Knowledge Assistant
- Dynamic Document Processing: A sidebar interface allowing users to upload new PDF or TXT files, which the app automatically chunks, embeds, and stores in the vector database.
- Context-Aware Chat UI: A modern chat interface built with Streamlit that maintains conversation history, allowing users to ask follow-up questions naturally.
- Strict Guardrails (Anti-Hallucination): System instructions designed so the AI politely declines to answer questions that fall outside the context of the uploaded documents.

Machine Learning Bootcamp
A beginner-friendly, 7-week project-based bootcamp designed to take you from Python basics to deploying your first Machine Learning model. Through hands-on practice, you will master essential data manipulation, build predictive algorithms, and develop an end-to-end, industry-ready application to kickstart your career in data science.
End-to-End Student Success Predictor
- Automated Data Pipeline: A preprocessing script that automatically cleans missing values, encodes categorical data (like course type or student background), and scales numerical inputs.
- Predictive Engine: A tuned machine learning classification model (e.g., Random Forest) specifically optimized for high Recall, ensuring that "at-risk" students are not missed.
- Interactive Web Dashboard: A user-friendly Streamlit interface featuring a sidebar where instructors can manually input a student's study hours, quiz scores, and login frequency to get an instant pass/fail probability.
Artikel Terkait

Memahami Konsep Logistic Regression dan Implementasinya dengan Python untuk Klasifikasi Biner

Teori dan Implementasi Principal Component Analysis (PCA) untuk Dimensionality Reduction dengan Python